Day 13 - [语料库模型] 01-TF-IDF与余弦相似性
TF-IDF(Term Frequency - Inverse Document Frequency)和余弦相似性是整套系统很重要的部分,主要用来建立整个问答集的模型,还有比对使用者输入的句子和问答集的哪一句最相似。
简介
TF-IDF
- 常用在资讯检索与文字探勘的加权方式,是一种统计方法,用来评估一个词在句子或文件中的重要程度。
- 应用於中文时,由於中文字词间不如英文有空白相隔,因此中文语句需先经过适当断词。
- 假设出现越多次的词是越不重要的词。
TF-IDF 分为两个部分,TF 和 IDF。(IDF 由 DF 转换而来)
- TF(词频):一个词在一个句子中出现的频率。
- DF(文件频率):是指一个词出现在几个句子中。
- IDF(逆向文件频率): IDF便是将DF经过转换,IDF 越低的表示这个词越不重要,反之亦然。
TF-IDF 实例说明
以五个撷取自问答集的问句为例,经过断词之後,问句会变成表中的格式。
- 表1
| 编号 | 问句 |
|---|---|
| 0 | ['如何', '申请', '长期', '照顾', '服务', '及', '流程', '为', '何', '?'] |
| 1 | ['申请', '长照', '服务', '有', '什麽', '条件', '?'] |
| 2 | ['长期', '照顾', '服务', '项目', '有', '哪些', '?'] |
| 3 | ['何谓', '是', '「', '居家', '服务', '」', '?'] |
| 4 | ['何谓', '「', '喘息', '服务', '」', '?'] |
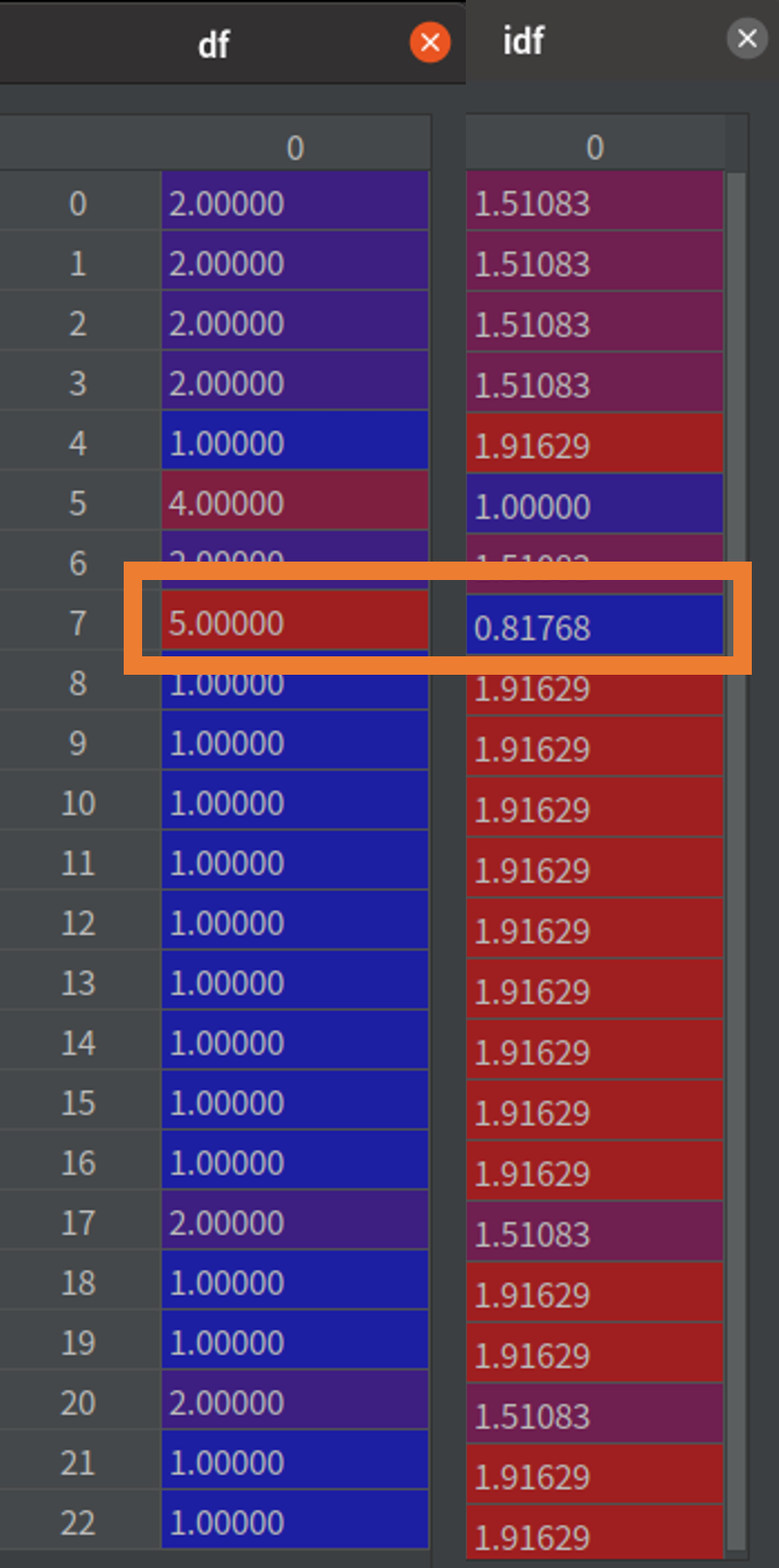
首先,我们会把所有的词整理成一个集合(图 1)。再统计每个词出现在句子中的频率,例如,「有」出现在第 1、2 句(参考 表格 1、图 1 绿框、图 2 绿框)。再统计一个词出现在几个句子中,例如,「服务」在五个句子都有,所以相对的 IDF 值就会比较小(参考 表格 1、图 1 橘框、图 3 橘框)。IDF 可以被当作是一个权重,用来表示这个词的重要程度,把 TF * IDF 就会得到这个资料集的模型(图 4)。
- 图1
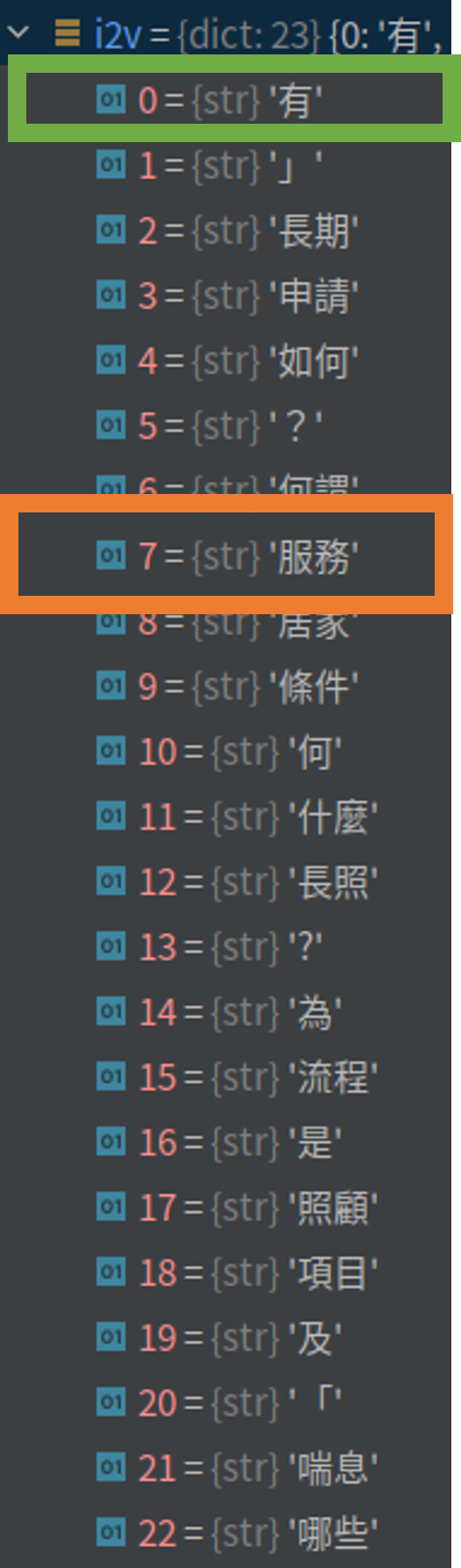
- 图2
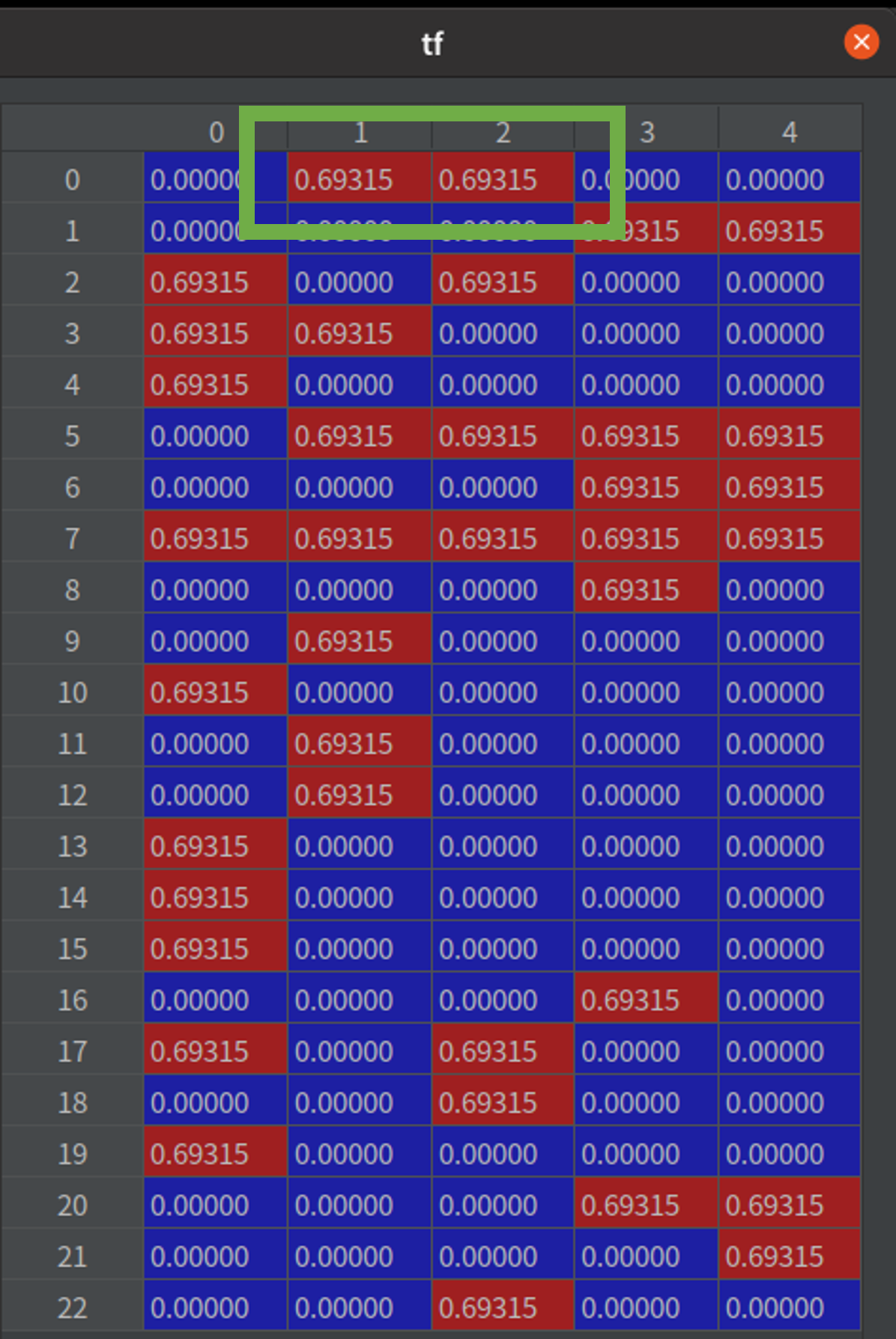
- 图3
- 图4
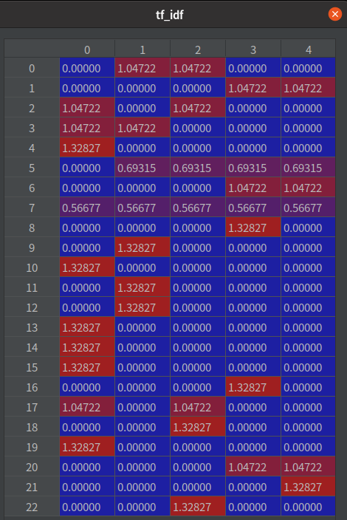
TF-IDF 使用余弦相似性公式计算出输入的问句与问答集中每个问题的相似性,再找出相似性最高的前三笔,回传给使用者端 APP 使用。
TF-IDF 矩阵
TF-IDF 可以计算出每个词在句子中权重分布的状况,再透过余弦相似性比较输入的句子与问答集中每个问题的相似性,最後找到与输入句子最相符的问答组合。
我们用程序画了一张图,每一列代表一个句子,每一栏代表一个词,颜色深浅代表这个词在这个句子中的重要性。如截图所示,栏位个别代表一个句子,每一列则代表每一个词,由这个矩阵可以观察到所有权重的分布状况。

因整个问答集的问句及词语太多,完整的截图放在文中不易阅读,因此本文中仅使用部分问句与词语生成图表示意。
余弦相似性
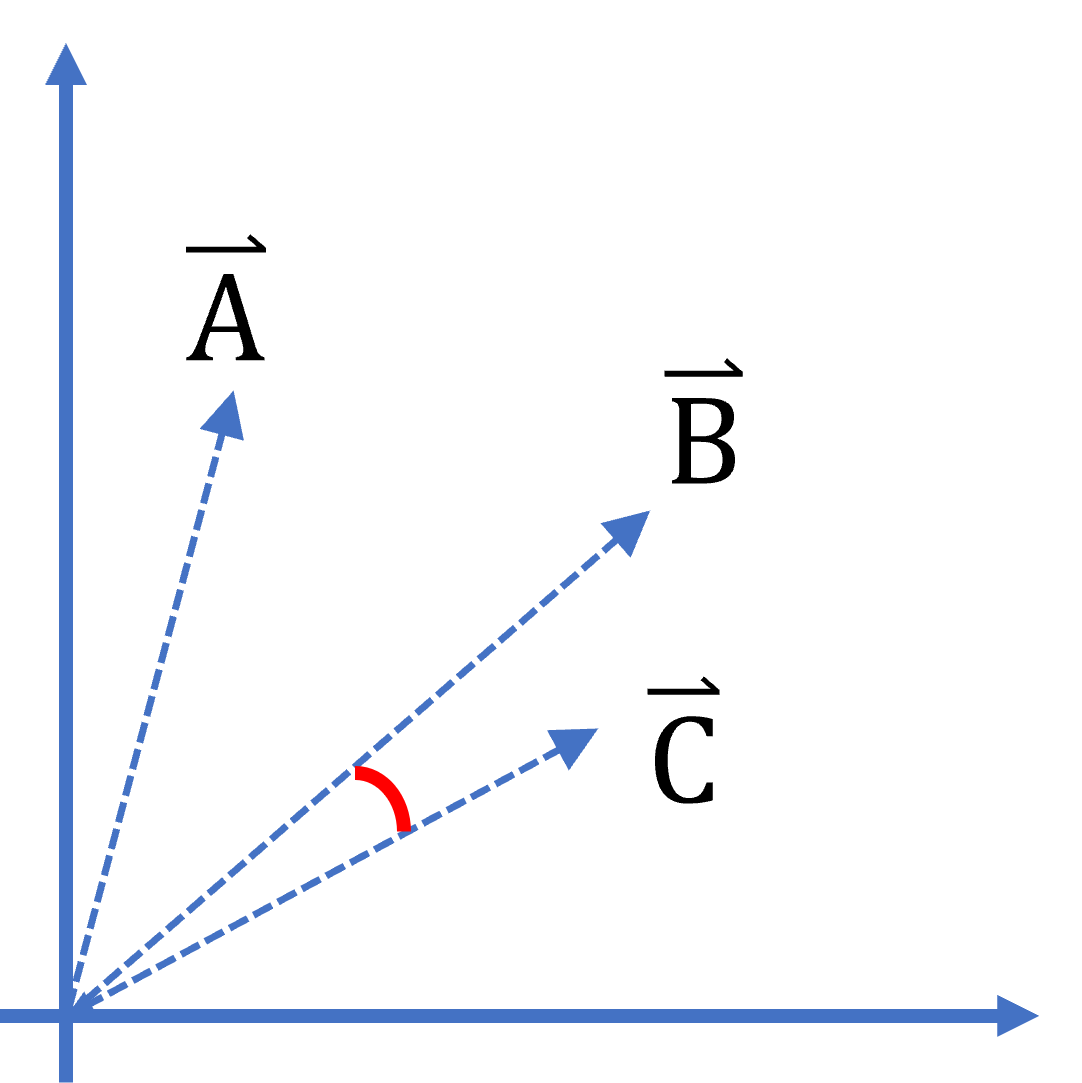
这些句子都可以当成是一个一个的向量,当然他的维度比较高,我们这边就以二维的做示意图,余弦相似度无关乎向量大小,重点是向量之间的方向。
本文以二维示意图说明,假设资料集中有 A、B 两个句子,C 是要比对的句子。当把 C 放进来一起比较就可以看出,C 和 B 的余弦相似性比 C 和 A 大。
结语
透过 TF-IDF 建立模型,再使用余弦相似性比对句子间的相似性。基本上本系统最核心的部分就是这两个部分了。
>>: Day 21: Convolutional Neural Networks — 卷积神经网路初探(下)
初探 OpenTelemetry
为什麽会接触到 OpenTelemetry,算是因为 Log 的追踪关系,在後台上有两三个 Spri...
Day 19 - [语料库模型] 07-程序码: 余弦相似性
嗨,昨天语料库模型建好了,下一步要如何使用呢? 我们要如何比对输入的句子与语料库中的哪一句最相似呢?...
JavaScript DOM | createElement()
接续昨天的 DOM 方法,JavaScript 常会出现:按一下某按钮,页面上会生出新的区块,这是怎...
Day 10 Self-attention(四) 要如何平行运算?
Self-attention 昨天讲到要怎麽用input的四个vector,a1、a2、a3、a4来...
【D18】尝试料理:取得所有股票清单
前言 有了这些功能後,想要知道能不能跑所有的股票,然後做这些事情,无论是行情订阅,还是历史资料。因此...