GPU程序设计(1) -- Hello CUDA !
前言
CUDA Toolkits 是 NVIDIA GPU 卡的程序工具箱,可呼叫相关函数,在GPU卡上进行相关数学运算,尤其是张量(Tensor),常用於图形处理或深度学习的计算。
使用TensorFlow一段时间,常发生GPU记忆体不足(OOM),因此,想直接使用 CUDA Toolkits,看看是否有改善空间,或许也可以更了解GPU的运作,因此,就来一趟 CUDA 学习之旅吧 !!
安装
安装 CUDA Toolkits 之前,须确定驱动程序是否安装,对应可安装的CUDA Toolkits版本。步骤如下:
-
GPU卡驱动程序:一般而言,GPU卡驱动程序会随PC购买就已安装妥当,可在桌面按滑鼠右键,选择【NVIDIA 控制面板】,视窗出现後点选左下角的【系统资讯】,即可看到GPU卡相关讯息,相关说明可参阅『Win10 安装 CUDA、cuDNN 教学』。
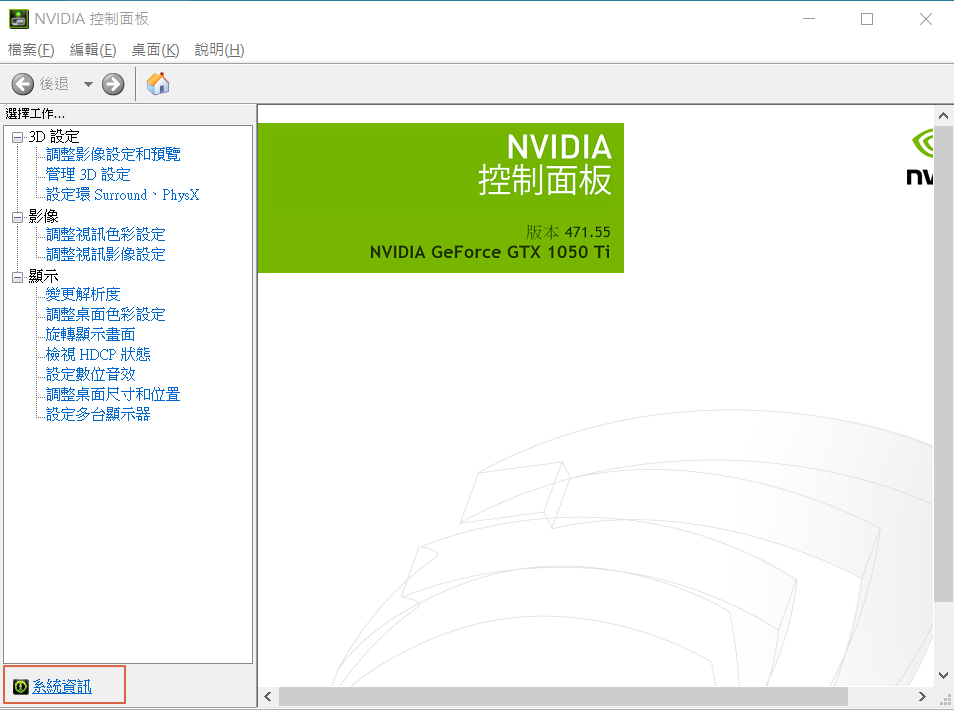
图一. GPU卡系统资讯 -
安装 Visual Studio(简称 vs):自微软官网下载Visual Studio,目前CUDA的范例支援vs 2017/2019,故安装 vs 2019。
-
安装 CUDA Toolkits:笔者有使用TensorFlow,故配合TensorFlow规定安装相对的版本,目前为v11.2。
开战
CUDA Toolkits 安装後,可以在 C:\ProgramData\NVIDIA Corporation\CUDA Samples 目录下找到一堆范例程序,我们就先来执行看看吧。
-
首先,找一支向量运算的专案 v11.2\0_Simple\vectorAdd,滑鼠双击(double click) vectorAdd_vs2019.sln,会以vs 开启专案,在专案名称按滑鼠右键,选择【属性】,
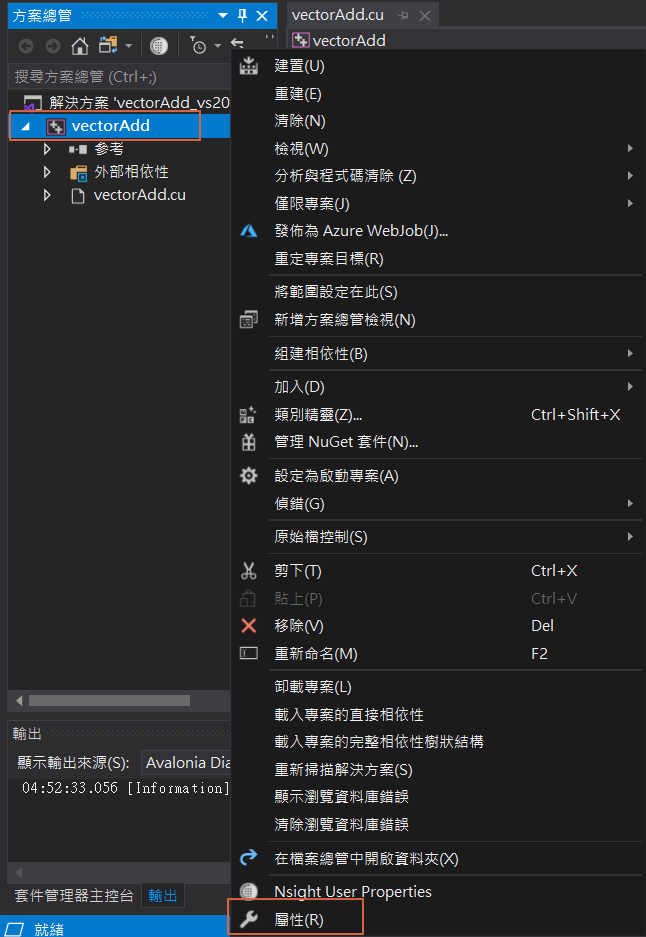
图二. vs 专案属性 -
点选【CUDA C/C++】> 【Common】,在【CUDA Toolkits Custom Dir】输入CUDA Toolkits安装目录,通常是【C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2】,注意目录最後的版本别,要随安装版本不同而修改,按确定後,即可建置专案。
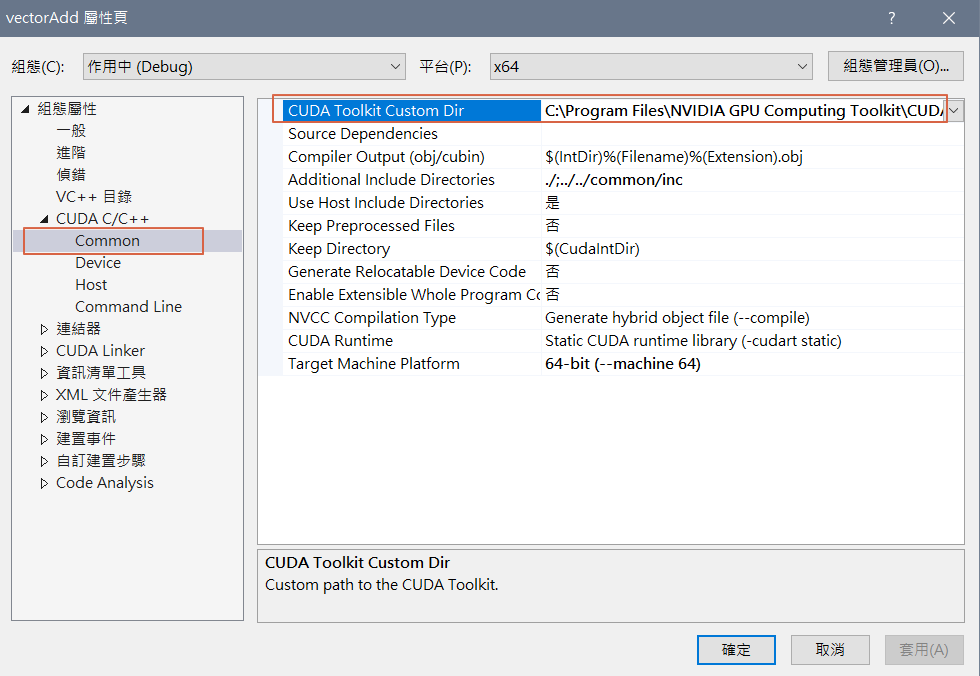
图三. 设定 CUDA Toolkits 安装目录 -
执行:出现以下讯息即大功告成。
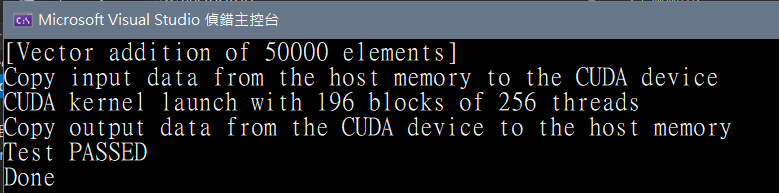
图四. 执行结果
取得GPU的资讯
再测试另一专案 v11.2\1_Utilities\deviceQuery\deviceQuery_vs2019.sln,执行结果如下,可得知GPU卡相关讯息。
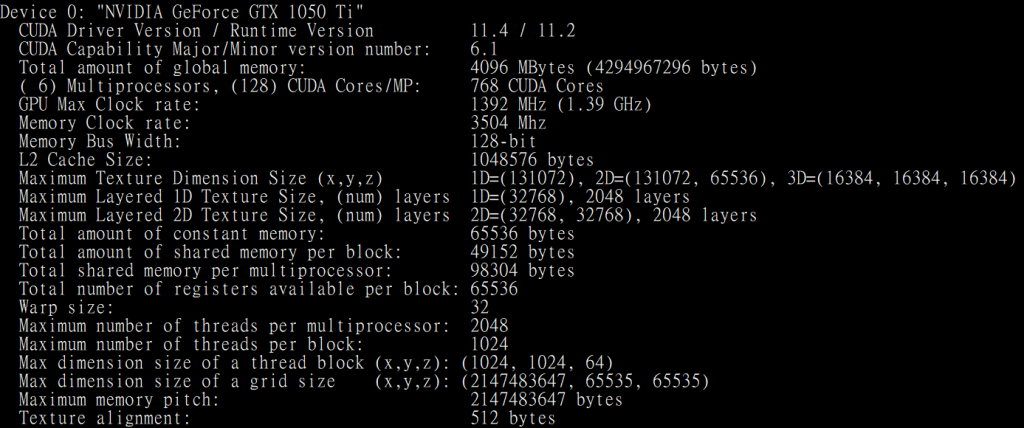
图五. deviceQuery 执行结果
写一支全新的程序
接下来从无到有,写一支全新的程序,步骤如下:
-
建立新专案,选择【CUDA 11.2 Runtime】范本,按【下一步】。
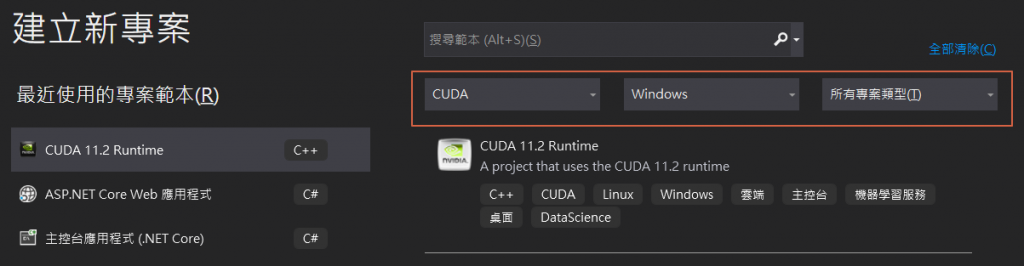
-
修改专案属性及位置,按【下一步】。
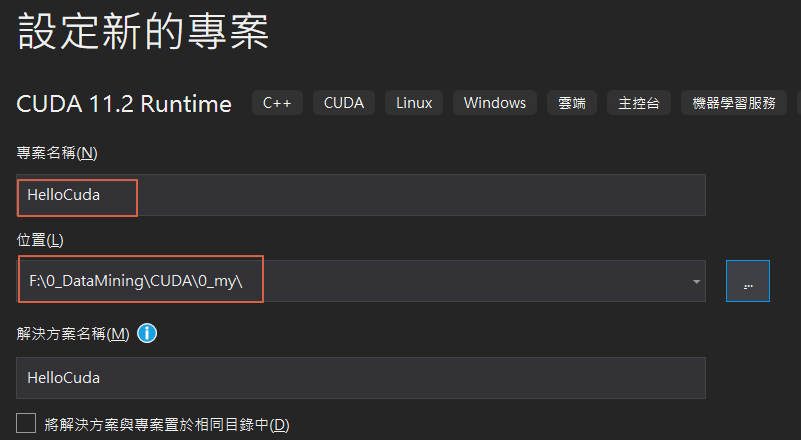
-
专案建立後,会自动产生一个程序档kernel.cu,为两向量相加的范例。
-
同上,点选【CUDA C/C++】> 【Common】,在【CUDA Toolkits Custom Dir】输入CUDA Toolkits安装目录,通常是【C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2】,按【确定】。
-
执行:出现以下讯息即大功告成。
{1,2,3,4,5} + {10,20,30,40,50} = {11,22,33,44,55}
- 修改kernel.cu内容,将原有程序全部删除,再加上以下内容:
#include <iostream>
#include <stdio.h>
__global__ void myfirstkernel(void) {
}
int main(void) {
myfirstkernel << <1, 1 >> > ();
printf("Hello, CUDA!\n");
return 0;
}
- 执行:出现以下讯息即大功告成。
Hello, CUDA!
程序说明
global 表示 myfirstkernel 函数在 GPU 执行,目前函数内容是空的。而 main() 仍然是在 CPU 执行。
<< <1, 1 >> > :<<<block 数目, thread 数目>>>
现在 CPU、GPU都是多核心的设计,程序透过多执行绪(Multi-threads)平行处理各项子任务,可以明显缩短执行时间,一个程序会被切割给多个执行绪区块(blocks of threads)独立执行,即平行处理。如下图,在两核(Streaming Multiprocessors, SM)及四核的GPU执行,程序会自动分配到所有的执行绪区块,称为『Automatic Scalability』。
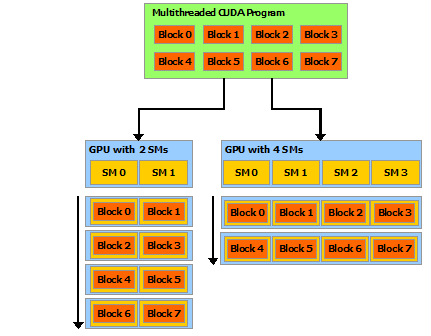
图五. Automatic Scalability,图片来源:CUDA C++ Programming Guide
一个区块内的所有执行绪都会在同一核(processor core)处理,每个区块最多可以有1024个执行绪,上述程序就是指定一个区块,且含一个执行绪,下次我们再来测试使用多区块、多执行绪。
NVCC
其实 CUDA Toolkits 也附一个编译器 NVCC,可直接编译C++程序,例如一个程序 hello.cu 内容如下:
#include<stdio.h>
__global__ void cuda_hello(){
printf("Hello World from GPU!\n");
}
int main() {
printf("Hello World from CPU!\n");
cuda_hello<<<1,1>>>();
return 0;
}
执行下列指令即可建制执行档 hello.exe。
nvcc hello.cu -o hello.exe
适合简单的程序,但不能除错。
Day04 如何通讯-网路协商
WebRTC 通讯 WebRTC 最常见的应用场景就是一对一的视讯通话,当我们准备和另一端的人进行点...
Day12 - 解析图片中的 QR Code 资料
前言 前篇讲解如何产二维条码 QR Code,这篇则是示范如何解析(解码) QR Code,类似工具...
DAY 24 - 四足战车 (5) 完
大家好~ 我是五岁~ 今天是画四族战车的最後一天~ ✧◝(⁰▿⁰)◜✧ 最後来把他完成上色跟光影吧!...
自动化 End-End 测试 Nightwatch.js 之踩雷笔记:等待物件II
前篇提到可以利用 waitForElementVisible() 去等待一个物件的 display ...
Day 4 - 稳若磐石
前言 上次还欠了cin >> 的介绍!我可没忘记唷!只不过说到cin >>这...