Day13 - 使用爬虫套件撷取网页内容
接续昨天的内容,今天要实作使用爬虫技术,根据给定的小说网址,抓取其书名和作者资讯。
这次会使用两个套件:
- requests:用来发出HTTP请求,透过HTTP下载指定资料,这次主要使用来抓取指定网页的HTML。
- BeautifulSoup:用来解析HTML结构,使我们可以更轻松的搜寻所需使用的资料。
安装套件
pip install requests
pip install BeautifulSoup4
下载HTML
import requests
page = requests.get("http://www.jjwxc.net/onebook.php?novelid=3397298")
print(page.text)
print("encoding: " + page.encoding)
使用GET方法取得网站的HTML,但在中文网站上有时会出现乱码问题:
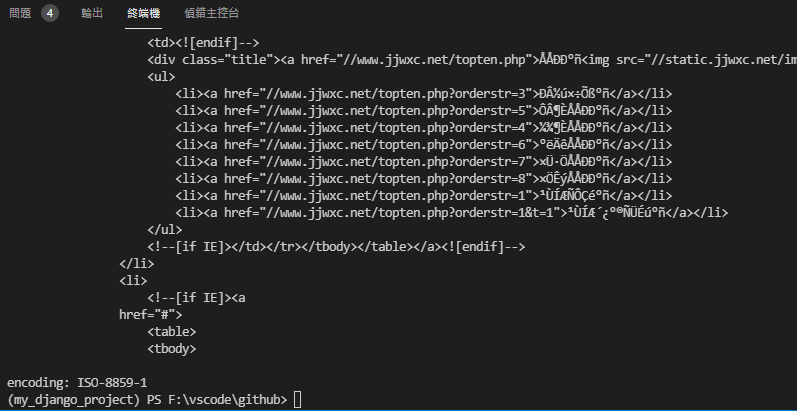
主要原因在於requests虽然会自动判断网页,但有可能会判断错误。
如此范例中,使用page.encoding显示requests的编码方式为ISO-8859-1,但实际打开HTML,在head中标示使用gb18030。
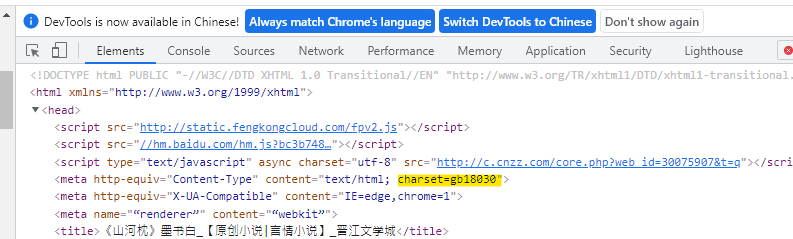
因此只要将page.encoding手动设定和HTML内相同的编码,即可解决乱码问题。
import requests
page = requests.get("http://www.jjwxc.net/onebook.php?novelid=3397298")
page.encoding = 'gb18030'
print(page.text)
print("encoding: " + page.encoding)
撷取HTML
在取得HTML後,接下来我们就可以使用BeautifulSoup进行解析。
soup = BeautifulSoup(page.content, 'html.parser')
其中的'html.parser'为指定BeautifulSoup使用的解析器,不同的解析器产出的结果都不同;回传的soup,则是是经过解析後产生的树状结构物件。
接着回到chrome浏览器,在书名的部分点击右键,选择「检查」,在开发者工具中会看到书名使用标签,且其属性itemprop为articleSection。
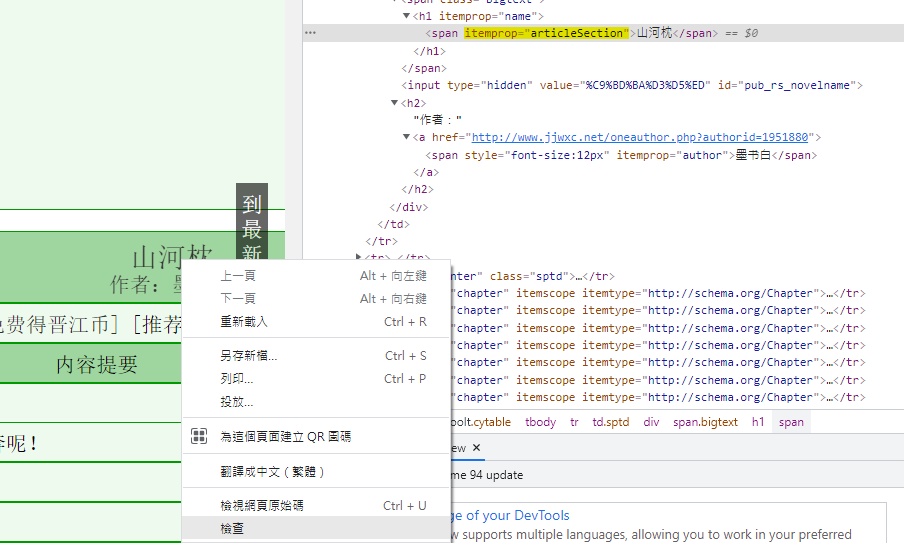
了解抓取目标的标签属性後,即可透过soup.find()方法找到该标签:
title_tag = soup.find("span",itemprop="articleSection")
print(title_tag)

使用print()确认内容,发现find()回传内容会包含HTML标签,故再使用正规表示式处理,撷取所需的文字。
完整程序:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get("http://www.jjwxc.net/onebook.php?novelid=3397298")
page.encoding = 'gb18030'
soup = BeautifulSoup(page.content, 'html.parser')
title_tag = soup.find("span",itemprop="articleSection")
author_tag = soup.find("span", itemprop="author")
title = re.compile(r'>(.*)<').search(str(title_tag))
print(title.group(1))
author = re.compile(r'>(.*)<').search(str(author_tag))
print(author.group(1))
<<: [DAY10] 用 Automated ML 快速开发
>>: Day 25 | BroadcastReceiver 广播
Day 03 Introduction to AI
Challenges and risks with AI Bias can affect resul...
AWS Academy LMS (Learning Management System) 基础 - 教师
AWS Academy 登录画面 https://www.awsacademy.com/SiteLo...
Flutter体验 Day 15-滚动组件
滚动组件 滚动组件是具有可滚动(Scroll)效果的内容区块,可以透过滚动的方式提供更多可浏览的内容...
Backtrader - 绘图
以下内容皆参考 Backtrader 官网 有了策略可以让我们进行评估,有了历史资料可以进行回测,加...
【Day17】密码破解 ─ 工具实作篇(二)
哈罗~ 昨天介绍了L0phtCrack破密工具, 今天来介绍另一个ncrack的密码破解工具。 nc...