范例(二)预测心血管疾病的可能性
第二个范例将以心血管疾病的Dataset进行说明如何执行training、tracking与serving. 这个范例来源为这里.
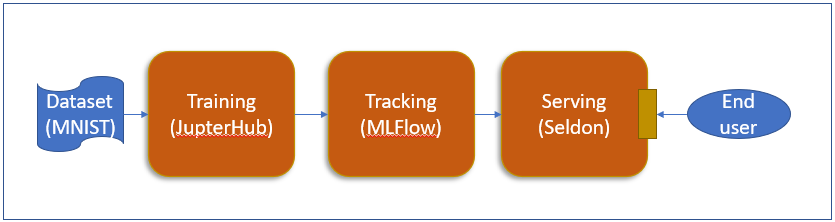
第Day1 的示意图表示如下:
- Training: 一样使用JupyterHub
- Tracking: 也一样使用MLFlow, 将parameter、metrics与model记录在MLFlow
- Serving: 会使用Seldon core执行部署模型
范例程序可以从github下载
- notebook: cardiovascular_disease_prediction_notebook.ipynb
- dataset: cardio_train.csv
在cardio_train.csv里面的栏位包含:
- age: 年龄
- gender: 姓别
- height: 身高
- weight: 体重
- ap_hi: 收缩压
- ap_lo: 舒张压
- cholesterol: 胆固醇状况
- gluc: 血糖状况
- smoke: 是否抽烟
- alco: 是否饮酒
- active: 活动状况
- cardio: 罹患心血管疾病的机率
训练完成後, 执行推论时,使用者需要提供age、gender、height、weight、ap_hi、ap_lo、cholesterol、gluc、smoke、alco、active资料, 系统将会回传该人员罹患心血管疾病的机率.
执行训练时会使用XGBoost(eXtreme Gradient Boosting)进行模型的训练, 关於XGBoost的介绍可以参考wikipedia
会使用这个范例进行说明的原因下如:
- 因为资料量不大,所以执行训练的时间比较短(省时)
- XGBoost是资料科学家很常使用的机器学习工具, 在Kaggle比赛经常采用XGBoost参赛.
- 完成训练之後产生的model档可以放在seldon上进行部署
下一篇我们就来说明这份推估心血管疾病机率的notebook内容
参考资料
https://www.kaggle.com/sulianova/cardiovascular-disease-dataset
https://zh.wikipedia.org/wiki/XGBoost
<<: Day09 Platform Channel - BasicMessageChannel
>>: [Day 24] DOM Array Methods 实作练习
MySQL学习_Day1
学习内容 关联式资料库、创建资料库、建立表格 在进入MySQL学习之前,Icebear特别去了解一下...
[DAY5]认识kubectl指令
kubectl 装好K8S後,可以使用kubectl进行K8S CLUSTER的操作 开启TERNI...
Day 25:「好慢喔,下载多少了?」- 进度条
终於到了我们的元件篇啦!!! 今天是第一个元件,所以稍微简单一点。 我们要来做下载的进度条~ 前置...
DAY 30- NFT & 结语
最後一篇,想说讲一下最近很夯的NFT,做为一个结尾。 NFT Non-Fungible Token,...
伸缩自如的Flask [day11] log with mongoDB
首先,理论上今天应该进展使用Python到写资料进mySql,但是我发现用来记录log的套件像是lo...