[Day 11] 核模型 - 支持向量机 (SVM)
核模型 - 支持向量机 (SVM)
今日学习目标
- SVM 分类器
- 何谓支持向量机? 非线性与线性?
- 多元分类支持向量机。
- SVR 回归器
- 学习 SVR 方法如何处理连续性输出。
- SVM 分类器与 SVR 回归器手把手实作
- 藉由图形化的边界,来了解使用不同的 Kernel 及不同参数的意义。
- 查看 SVR 方法在简单线性回归和非线性回归表现。
SVM 分类器
支持向量机 (support vector machine, SVM) 是一个基於统计学习的监督式演算法,透过找出一个超平面,使之将两个不同的集合分开。一般的分类问题我们就是要,找出在不同的资料类别中的分隔线。但在一般状况下这个分隔线非常复杂且有很多种可能。然而 SVM 就是要在这很多种的可能当中找出最佳的解。SVM 演算法的精神就是找出一条分隔线使所有在边界上的点离得越远越好,使模型抵抗杂讯的能力更佳。
SVM 可分为以下两种:
- 线性可分支持向量机
- 非线性可分支持向量机
线性可分支持向量机
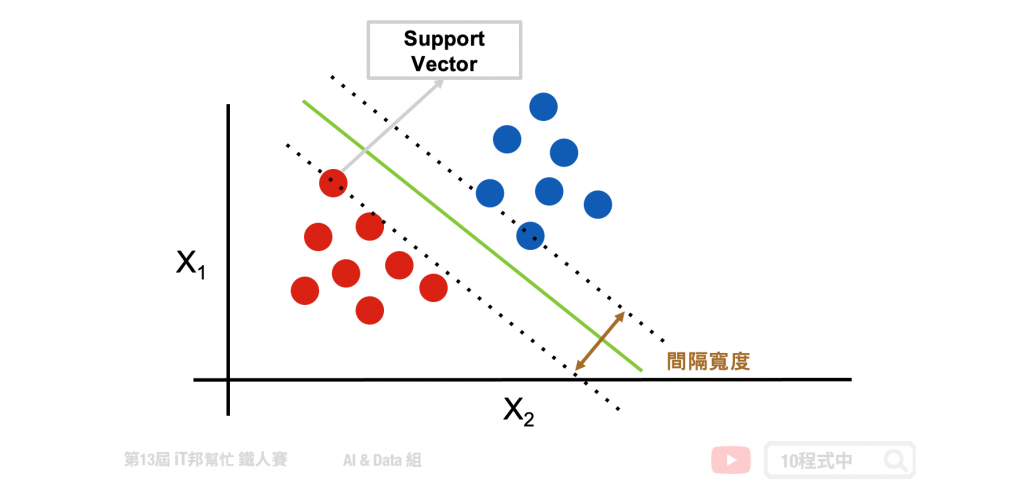
线性可分支持向量机就是在下图范例的二维图形中找出一条线,目标让这条直线与两个类别之间的间隔宽度距离最大化。其中离两条虚线(间隔超平面)距离最近的点,就称为支持向量 (support vector)。
当然现实生活中的资料往往稍微复杂,那如果不是线性可分集合怎麽办呢?我们可以运用核函数(kernel function) 帮我们造出不可分的分割平面。
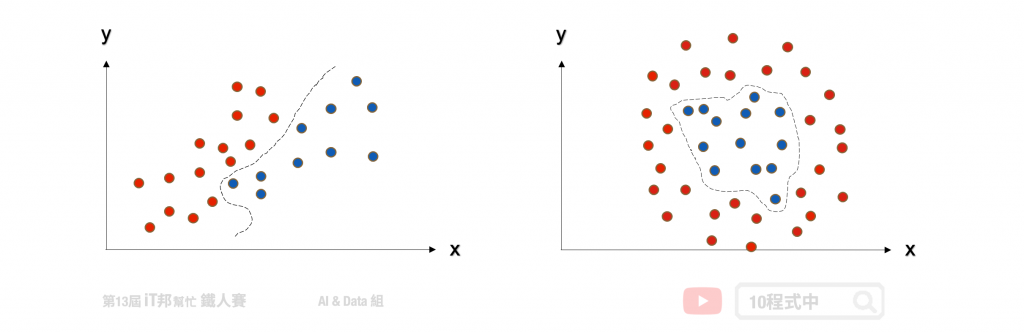
非线性可分支持向量机
除了进行线性分类之外 SVM 还可以使用核技巧有效地进行非线性分类,将其输入的资料投到更高维度的空间,并在高维度的空间进行高维度的分类或降维。简单来说透过多维度的投影技巧,将原本在二维空间中不可分的点到了三维空间就可分了。但是随着资料量增加其运算也会变多,相对的执行速度就会变慢。
两个非线性的 Kernel:
- Polynomial 高次方转换
- Radial Basis Function 高斯转换
多元分类支持向量机
SVM 演算法最初是为二元分类问题所设计的,但是现实生活中的例子一定不只有两类的问题要解决。他的解决方式与 [Day 9 逻辑回归] 所提到的多元分类逻辑回归是一样的。主要是将一个多元分类问题转换为多个二元分类问题。常见方法包括 one-vs-rest(OvR) 和 many-vs-many(MvM) 两种。
- one-vs-rest(OvR)
- 将某个类别的样本归为一类,其他剩余的样本归为另一类
- many-vs-many(MvM)
- 在任意两类样本之间设计一个 SVM
详细介绍可以参考 [Day 9 逻辑回归]
SVR 回归器
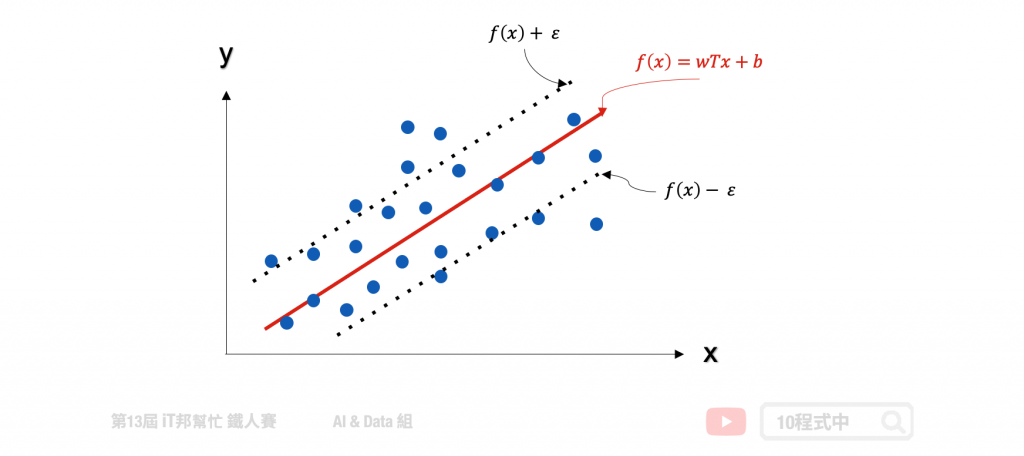
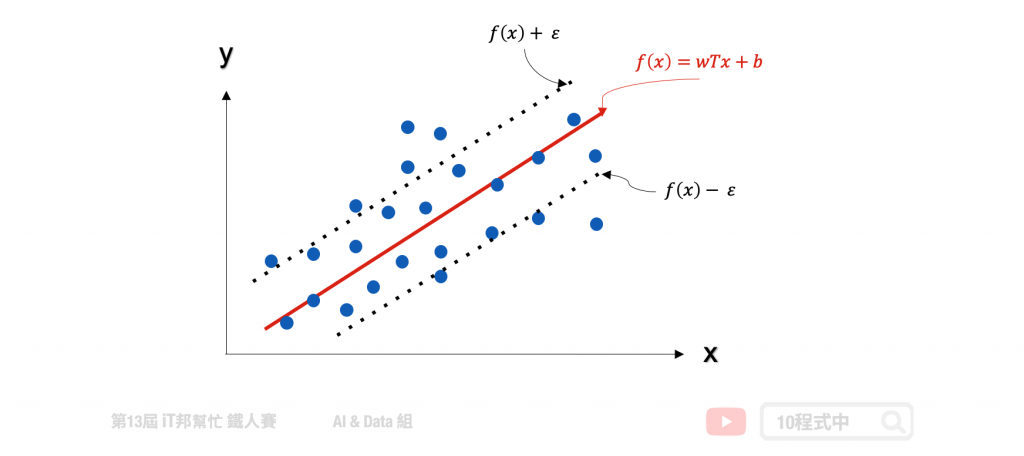
支持向量机(SVM)是专门处理分类的问题,还有另一个名词称为支持向量回归(Support Vector Regression, SVR)专门处理回归问题。SVR 是 SVM 的延伸,而支持向量回归只要 f(x) 与 y 偏离程度不要太大,既可以认为预测正确。如下图中的回归范例,在线性的 SVR 模型中会在左右加上 ? 作为模型容忍的区间。因此在训练过程中只有在虚线以外的误差才会被计算。此外 SVR 也提供了线性与非线性的核技巧,其中在非线性的模型中可以使用高次方转换或是高斯转换。
[程序实作]
支持向量机 (Support Vector Machine, SVM) 模型
SVM 能够透过超参数 C 来达到 weight regularization 来限制模型的复杂度。除了这点我们还能透过 SVM 的 Kernel trick 的方式将资料做非线性转换,常见的 kernel 除了 linear 线性以外还有两了非线性的 Polynomial 高次方转换以及 Radial Basis Function 高斯转换。
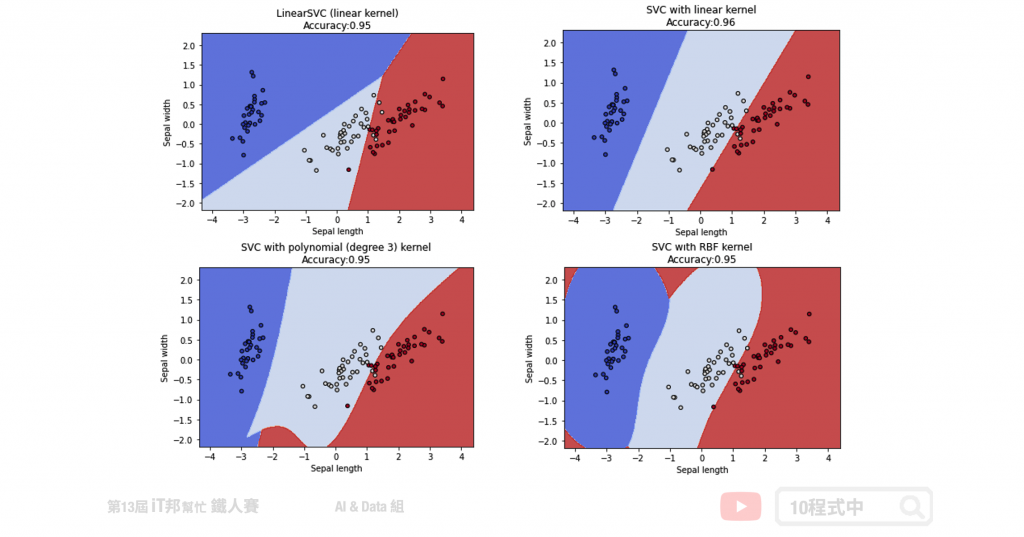
四种不同SVC分类器:
- LinearSVC (线性)
- kernel='linear' (线性)
- kernel='poly' (非线性)
- kernel='rbf' (非线性)
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
- predict_proba: 预测每个类别的机率值。
LinearSVC
Parameters:
- C: 限制模型的复杂度,防止过度拟合。
- max_iter: 最大迭代次数,预设1000。
from sklearn import svm
# 建立 linearSvc 模型
linearSvcModel=svm.LinearSVC(C=1, max_iter=10000)
# 使用训练资料训练模型
linearSvcModel.fit(train_reduced, y_train)
# 使用训练资料预测分类
predicted=linearSvcModel.predict(train_reduced)
# 计算准确率
accuracy = linearSvcModel.score(train_reduced, y_train)
训练集 Accuracy: 0.96
kernel='linear'
Parameters:
- C: 限制模型的复杂度,防止过度拟合。
- kernel: 此范例采用线性。
from sklearn import svm
# 建立 kernel='linear' 模型
svcModel=svm.SVC(kernel='linear', C=1)
# 使用训练资料训练模型
svcModel.fit(train_reduced, y_train)
# 使用训练资料预测分类
predicted=svcModel.predict(train_reduced)
# 计算准确率
accuracy = svcModel.score(train_reduced, y_train)
训练集 Accuracy: 0.97
kernel='poly'
Parameters:
- C: 限制模型的复杂度,防止过度拟合。
- kernel: 此范例采用 Polynomial 高次方转换。
- degree: 增加模型复杂度,3 代表转换到三次空间进行分类。
- gamma: 数值越大越能做复杂的分类边界。
from sklearn import svm
# 建立 kernel='poly' 模型
polyModel=svm.SVC(kernel='poly', degree=3, gamma='auto', C=1)
# 使用训练资料训练模型
polyModel.fit(train_reduced, y_train)
# 使用训练资料预测分类
predicted=polyModel.predict(train_reduced)
# 计算准确率
accuracy = polyModel.score(train_reduced, y_train)
训练集 Accuracy: 0.97
kernel='rbf'
Parameters:
- C: 限制模型的复杂度,防止过度拟合。
- kernel: 此范例采用 Radial Basis Function 高斯转换。
- gamma: 数值越大越能做复杂的分类边界
from sklearn import svm
# 建立 kernel='rbf' 模型
rbfModel=svm.SVC(kernel='rbf', gamma=0.7, C=1)
# 使用训练资料训练模型
rbfModel.fit(train_reduced, y_train)
# 使用训练资料预测分类
predicted=rbfModel.predict(train_reduced)
# 计算准确率
accuracy = rbfModel.score(train_reduced, y_train)
训练集 Accuracy: 0.97
我们藉由图形化的边界,来了解使用不同的 Kernel 及不同参数的意义。以下范例将原先 鸢尾花朵资料集四个特徵透过 PCA 降成二维,以利我们做视觉化观察。透过四种不同的 SVC 实验我们可以发现不同的核技巧所预测出来的决策边线都不尽相同。然而越复杂的模型相对的边界就会变得越扭曲,因为非线性的模型能够有比较好的拟合使得错误率降低。
支持向量回归(Support Vector Regression, SVR) 模型
在 Sklearn 中 SVM 提供回归的模型称作 SVR。此外 SVR 回归器也提供了三种不同的核函数,分别有一个线性以及两个非线性的模型可以呼叫。在 SVR 回归的实验,我们拿一组非线性的资料作为例子。并查看在不同的核技巧下模型所拟合的成效为何?
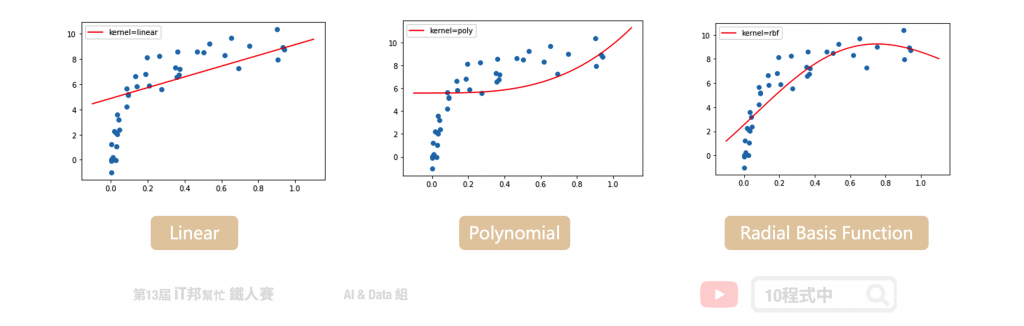
三种不同SVR回归器:
- kernel='linear' (线性)
- kernel='poly' (非线性)
- kernel='rbf' (非线性)
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
kernel='linear'
Parameters:
- C: 限制模型的复杂度,防止过度拟合。
- kernel: 此范例采用线性。
from sklearn import svm
# 建立 kernel='linear' 模型
linearModel=svm.SVR(C=1, kernel='linear')
# 使用训练资料训练模型
linearModel.fit(x, y)
# 使用训练资料预测分类
predicted=linearModel.predict(x_test)
训练集 MSE: 5.903802524650818
kernel='poly'
Parameters:
- C: 限制模型的复杂度,防止过度拟合。
- kernel: 此范例采用 Polynomial 高次方转换。
- degree: 增加模型复杂度,3 代表转换到三次空间进行分类。
- gamma: 数值越大越能做复杂的预测。
from sklearn import svm
# 建立 kernel='poly' 模型
polyModel=svm.SVR(C=6, kernel='poly', degree=3, gamma='auto')
# 使用训练资料训练模型
polyModel.fit(x, y)
# 使用训练资料预测分类
predicted=polyModel.predict(x_test)
训练集 MSE: 8.296270605383441
kernel='rbf'
Parameters:
- C: 限制模型的复杂度,防止过度拟合。
- kernel: 此范例采用 Radial Basis Function 高斯转换。
- gamma: 数值越大越能做复杂的分类边界。
from sklearn import svm
# 建立 kernel='rbf' 模型
rbfModel=svm.SVR(C=6, kernel='rbf', gamma='auto')
# 使用训练资料训练模型
rbfModel.fit(x, y)
# 使用训练资料预测分类
predicted=rbfModel.predict(x_test)
训练集 MSE: 2.2551572190243157
这里的回归模型采用非线性的资料进行数据拟合的实验。我们可以发现线性的核函数无法有效的预测所有数据点的趋势。而非线性的模型中 RBF 的模型对於此资料有比较好的预测结果。
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: JavaScript学习日记 : Day11 - 函数绑定
>>: Day 08:深仍可测的元件样式-Deep Selectors
Day 14 - Functor
Introduction 在先前我们提到了 compose,并且将许多单一功能的纯函式,透过 com...
Day 9:1046. Last Stone Weight
今日题目 题目连结:1046. Last Stone Weight 题目主题:Array, Heap...
day 15 - 从执行时间开始优化
经过了前面几天的步骤, 已经算是走过一遍本机开发到交付的流程了, 接下来再依照团队推上k8s的流程新...
day23 : TIDB on K8S (下)
尝试使用了TIDB後,接着就开始让他跟k8s做结合吧,我会介绍一次完整的TIoperator,然後配...
[ Day10] Web 小复习
哈罗各位安安 今天是连续发文的第10天 我没囤文,每天当下产文完成1/3了 洒花~ ㄟ我会不会太早庆...