[Day23] NLP会用到的模型(六)-transformer架构
一. 介绍
transformer就是像前述介绍的,他就是一个seq2seq model,将一个序列转成另一个序列,中间都是由前一天所说self-attention所构成的~~在2017年,google 提出了全部由attention所构成的nn模型的paper: “ATTENTION IS ALL YOU NEED”。这篇主要是处理机器翻译的工作,并且做到比RNN与CNN的架构更好,各位可以去拜读一下此paper[1]。
整体架构如下:
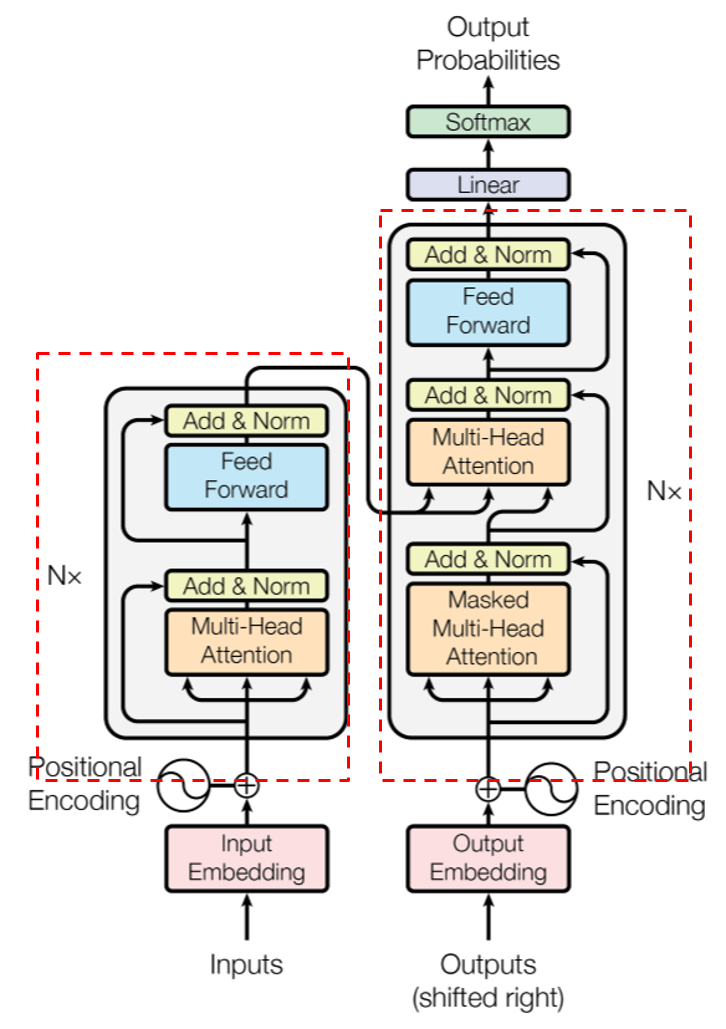
- 左边的红框框为encoder的架构:
-
由2个部分组成,第一部分是multi-head-attention组成,第二部分是feed-forword network组成,这样是一层encoder,在该论文中使用6层
-
第二部分只比第一部分多了一块mask multi-head attention,为何会多一个mask呢,其实就是让模型在训练decoder的时候,不样让模型之後的输出是甚麽,例如: ouput今天有一句话经断词後为[‘我’, ‘今天’, ‘很’, ‘帅’],他会依序进入decoder,所以第一个词是'我',其用意就是看'我'这个词与input的句子哪个词最相关(也就是attention的用意),确保後续的词并不会影响前面在训练的词。
-
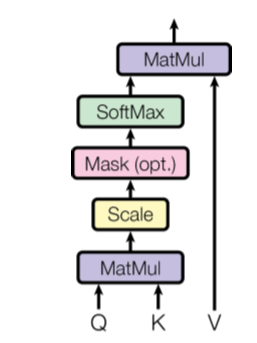
那明明就有self-attention了,为何还要有Multi-head self-attention,这其实就是重复做attention的意思,下图就是一个attention,就是昨天各位看到的最下面的计算流程:
Multi-head就是多头的意思,就是重复做attention,堆叠其来如下图,主要就是想透过不同角度来撷取不同的特徵,这篇论文主要是有8个头,也就是8个注意力机制:
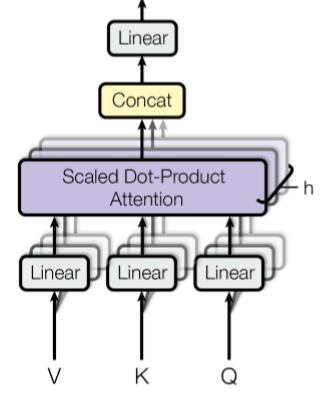
最後再把这8个的attention连起来,再经过一次线性转换,得到最後文字/句子编码
明天会开始慢慢介绍encoder与decoder的部分~
参考资讯
[1] https://ddoo8059.medium.com/transformer-%E7%90%86%E8%A7%A3-7a30ed23e6ed
[2] Vaswani, A., et al. “Attention Is All You Need. arXiv 2017.” arXiv preprint arXiv:1706.03762.
<<: 从零开始的8-bit迷宫探险【Level 15】迷人的反派角色-制作怪物
>>: Day 09. Zabbix 监控 ESXi vSphere
26. Redux 的用途 & 入门实作 (下)
这篇来把上一篇跳过的action补上,然後会补充一点之前没讲过的super()和React Refs...
[Day9] 建立订单交易API_2
笔者在这一章节,进行hashId及取得nonce资料的实作 def get_hash_id(hash...
[Day22] Websocket Injection
前言 :Websocket除了能建立一个双向通讯通道外,还能干嘛? :当然是拿来Injection阿...
[Day 8] 设计UI画面-Figma
昨天已经把功能规画完了, 接下来就需要画成UI,前端开发时会比较方便 也避免程序写完後才发现画面不合...
Day 04 - Spring Boot 的前世今生
结束了恼人的环境安装,但我们还没有要开始Spring Boot 的实作,因为在开始学习一项技术之前,...