[Day 10] 近朱者赤,近墨者黑 - KNN
近朱者赤,近墨者黑 - KNN
今日学习目标
- K-近邻演算法介绍
- KNN 演算法解析
- KNN 於分类器和回归器的做法
- 比较 KNN 与 k-means 差异
- 实作 KNN 分类器与回归器
- 实作 KNN 分类器,观察不同 k 值会对分类结果造成什麽影响
- 实作 KNN 回归回器
K-近邻演算法 (KNN)
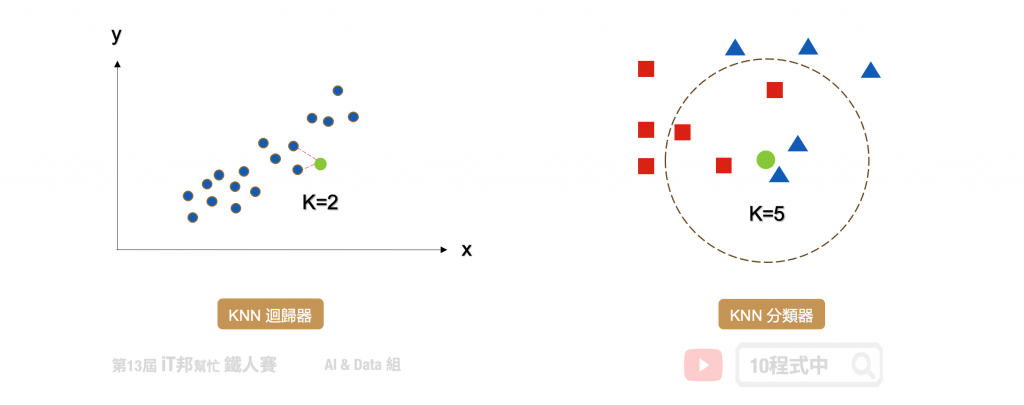
KNN 的全名 K Nearest Neighbor 是属於机器学习中的 Supervised learning 其中一种算法,顾名思义就是 k 个最接近你的邻居。分类的标准是由邻居「多数表决」决定的。在 Sklearn 中 KNN 可以用作分类或回归的模型。
KNN 分类器
在分类问题中 KNN 演算法采多数决标准,利用 k 个最近的邻居来判定新的资料是在哪一群。其演算法流程非常简单,首先使用者先决定 k 的大小。接着计算目前该笔新的资料与邻近的资料间的距离。第三步找出跟自己最近的 k 个邻居,查看哪一组邻居数量最多,就加入哪一组。
- 决定 k 值
- 求每个邻居跟自己之间的距离
- 找出跟自己最近的 k 个邻居,查看哪一组邻居数量最多,就加入哪一组
如果还是没办法决定在哪一组,回到第一步调整 k 值,再继续
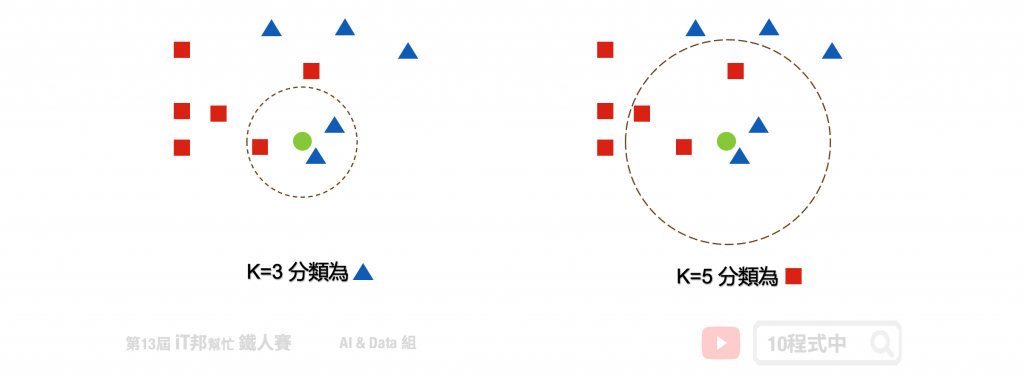
k 的大小会影响模型最终的分类结果。以下图为例,假设绿色点是新的资料。当 k 等於 3 时会搜寻离绿色点最近的邻居,我们可以发现蓝色三角形为预测的结果。当 k 设为 5 的时候结果又不一样了,我们发现距离最近的三个邻居为红色正方形。
KNN 回归器
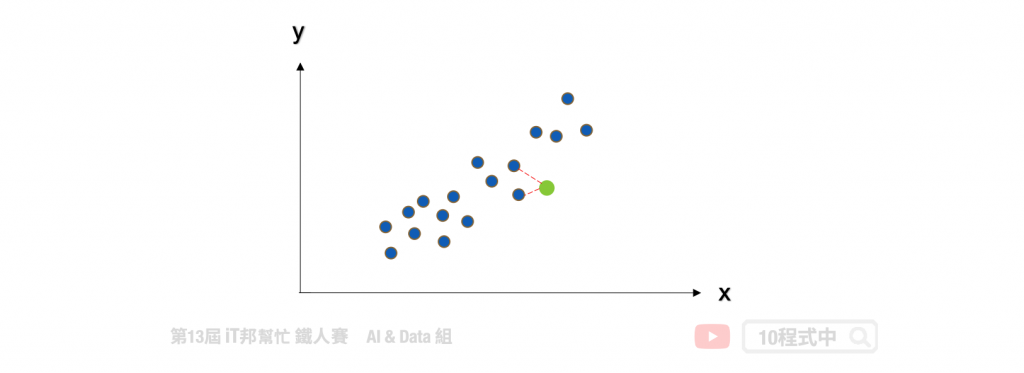
KNN 同时也能运用在回归问题上面。回归模型输出的结果是一个连续性数值,其预测该值是 k 个最近邻居输出的平均值。以下图为例当 k=2 时,假设我们有一个输入特徵 x 要预测的输出为 y。当有一笔新的 x 进来的时候, KNN 回归器会寻找邻近 2 个 x 的输出做平均当作是该笔资料的预测结果。
KNN 度量距离的方法
要判断那些是邻居的话,首先要量化相似度,而欧几里得距离 (Euclidean distance) 是比较常用的方法来量度相似度。除此之外还有明可夫斯基距离(Sklearn 预设)、曼哈顿距离、柴比雪夫距离、夹角余弦、汉明距离、杰卡德相似系数 都可以评估距离的远近。

KNN 与 k-means 勿混淆
KNN 的缺点是对资料的局部结构非常敏感,因此调整适当的 k 值极为重要。另外大家很常将 KNN 与 K-means 混淆,虽然两者都有 k 值要设定但其实两者无任何关联。KNN 的 k 是设定邻居的数量采多数决作为输出的依据。而 K-means 的 k 是设定集群的类别中心点数量。

[程序实作]
KNN 分类器
采用鸢尾花朵资料集做为分类范例,使用 Sklearn 建立 k-nearest neighbors(KNN) 模型。以下是 KNN 常见的模型操作参数:
Parameters:
- n_neighbors: 设定邻居的数量(k),选取最近的k个点,预设为5。
- algorithm: 搜寻数演算法{'auto','ball_tree','kd_tree','brute'},可选。
- metric: 计算距离的方式,预设为欧几里得距离。
Attributes:
- classes_: 取得类别阵列。
- effective_metric_: 取得计算距离的公式。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
from sklearn.neighbors import KNeighborsClassifier
# 建立 KNN 模型
knnModel = KNeighborsClassifier(n_neighbors=3)
# 使用训练资料训练模型
knnModel.fit(X_train,y_train)
# 使用训练资料预测分类
predicted = knnModel.predict(X_train)
使用Score评估模型
我们可以直接呼叫 score() 直接计算模型预测的准确率。
# 预测成功的比例
print('训练集: ',knnModel.score(X_train,y_train))
print('测试集: ',knnModel.score(X_test,y_test))
执行结果:
训练集: 0.9619047619047619
测试集: 0.9555555555555556
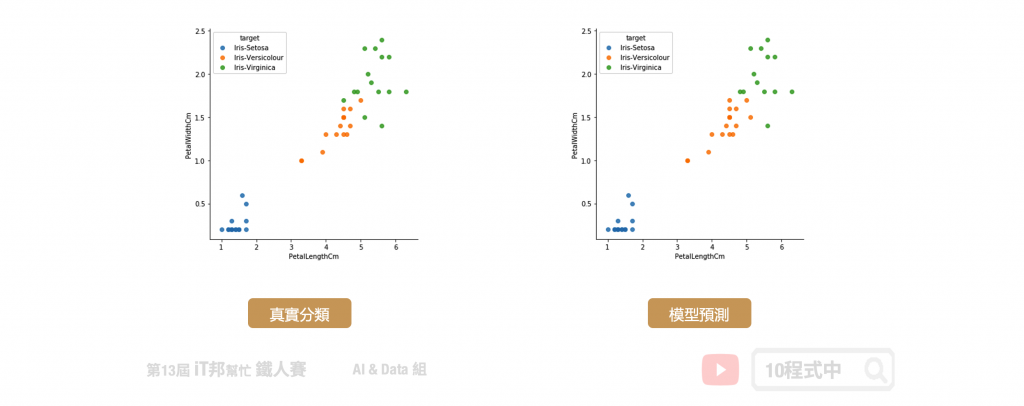
我们可以查看训练好的模型在测试集上的预测能力,下图中左边的是测试集的真实分类,右边的是模型预测的分类结果。从图中可以发现蓝色的 Setosa 完整的被分类出来,而橘色与绿色的分布是紧密相连在交界处分类的结果比较不稳定。但最终预测结果结果在训练集与测试集都有百分之95以上的准确率。
KNN 回归器
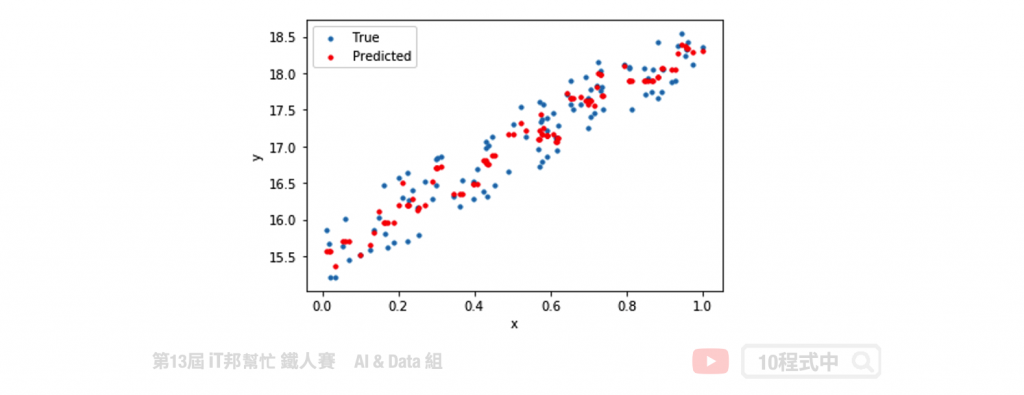
KNN 不仅能够作为分类器,也可以做回归连续性的数值预测。其预测值为k个最近邻居的值的平均值。
Parameters:
- n_neighbors: 设定邻居的数量(k),选取最近的k个点,预设为5。
- algorithm: 搜寻数演算法{'auto','ball_tree','kd_tree','brute'},可选。
- metric: 计算距离的方式,预设为欧几里得距离。
Attributes:
- classes_: 取得类别阵列。
- effective_metric_: 取得计算距离的公式。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
from sklearn.neighbors import KNeighborsRegressor
# 建立 KNN 模型
knnModel = KNeighborsRegressor(n_neighbors=3)
# 使用训练资料训练模型
knnModel.fit(x,y)
# 使用训练资料预测
predicted= knnModel.predict(x)
模型评估
Sklearn 中 KNN 回归模型的 score 函式是 R2 score,可作为模型评估依据,其数值越接近於1代表模型越佳。除了 R2 score 还有其他许多回归模型的评估方法,例如: MSE、MAE、RMSE。
from sklearn import metrics
print('R2 score: ', knnModel.score(x, y))
mse = metrics.mean_squared_error(y, predicted)
print('MSE score: ', mse)
本系列教学内容及范例程序都可以从我的 GitHub 取得!
增强关联式资料库的参照完整性(enforce the referential integrity of the relational database)
.外键(Foreign key)强制引用完整性。 .主键(Primary key)可增强实体的完整性...
鬼故事 - 什麽东西我都要拿在手上
鬼故事 - 什麽东西我都要拿在手上 Credit: 九品芝麻官 故事开始 小路是小华同公司的 Pre...
【从实作学习ASP.NET Core】Day04 | View 视图
昨天成功建立了 Controller 也得到了回传值,但它终究只是字串,所以今天要让他正式传入网页...
Day 11【连动 MetaMask - Pop Up & Login Detection】Can`t use current password.
【前言】 嗨嗨大家好,今天的主题延续昨天的检测是否已经安装插件後,紧接着而来的是 MetaMask...
【Day08】条件渲染 Conditional Rendering
在 JSX 中,可以使用 JavaScript 中 if 陈述式 或条件运算子如 三元运算子(ter...