Day16 支持向量机实作
https://github.com/PacktPublishing/Machine-Learning-Algorithms
线性支持向量机
一样先导入套件,上面的是用来算数学的;下面的是用来画画的,并且帮它们取绰号(np & plt)。
import numpy as np
import matplotlib.pyplot as plt
再来,用seed()随机产生整数的乱数後,设定样本数,细分为两个类别各500个的向量的样本集。
from sklearn.datasets import make_classification np.random.seed(1000) nb_samples = 500 X, Y = make_classification(n_samples=nb_samples, n_features=2, n_informative=2, n_redundant=0,n_clusters_per_class=1)
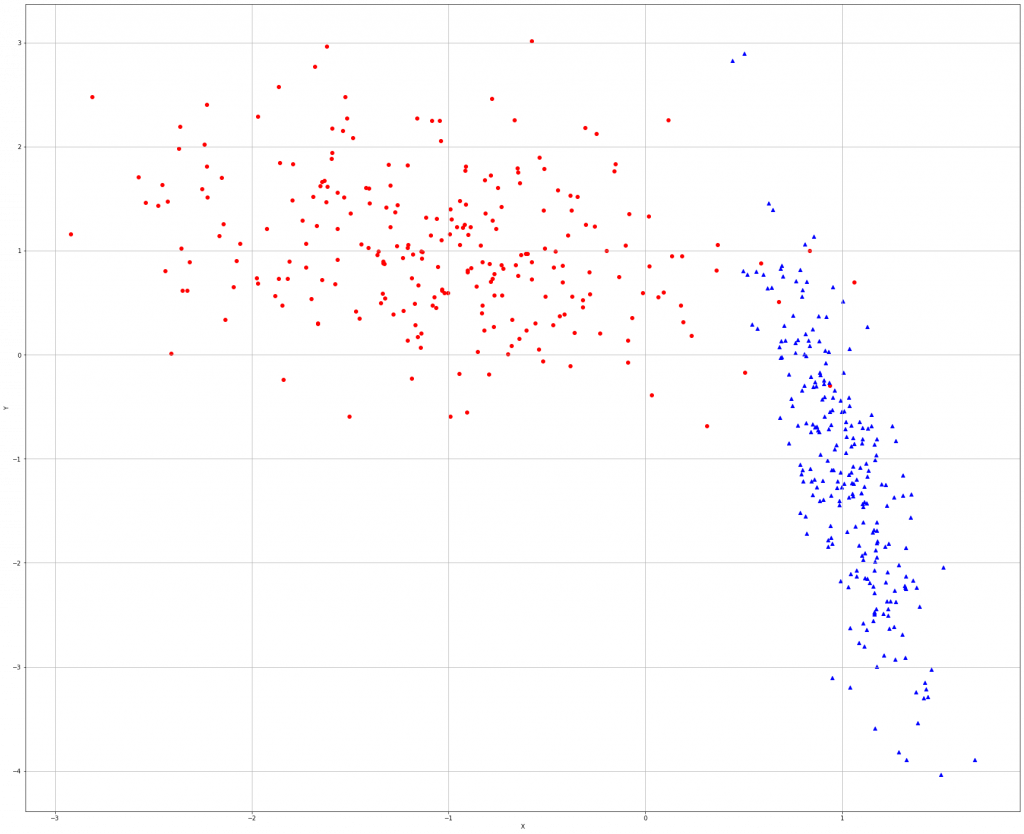
可以看到图中有些点介於重叠处,因此,需要使用正数的C让模型捕捉较复杂的动态。
scikit-learn有SVC类别,可以增加我们效率。并且会使用他与交叉验证来验证效能。
from sklearn.svm import SVC from sklearn.model_selection import cross_val_score svc = SVC(kernel='linear') svc_scores = cross_val_score(svc, X, Y, scoring='accuracy', cv=10) print('Linear SVM CV average score: %.3f' % svc_scores.mean())#Linear SVM CV average score: 0.984
非线性支持向量机
使用make_circles()函式建立非线性资料集。
from sklearn.datasets import make_circles nb_samples = 500 X, Y = make_circles(n_samples=nb_samples, noise=0.1)
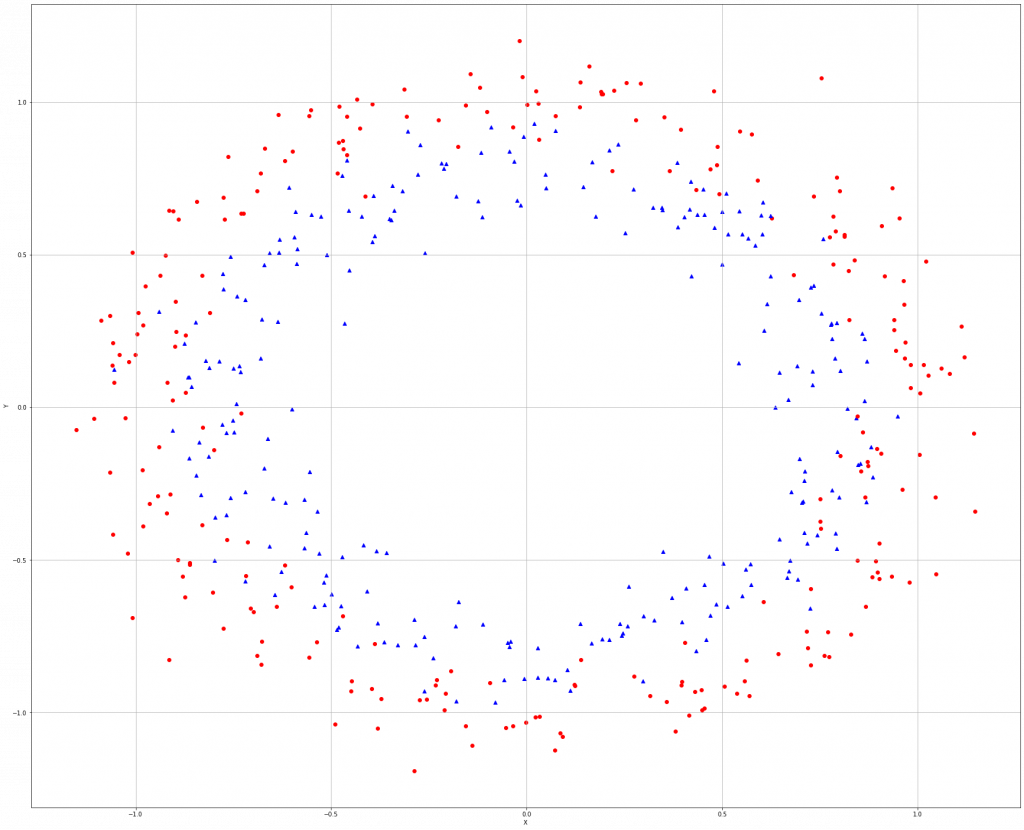
若使用逻辑斯回归预测的话,错误率大概45%,所以要用其他更准确的方式。
Logistic regression CV average score: 0.450
那我们使用不同的核函数来测试。最终结果资料集的几何预期,最佳的核是'rbf',准确率有88%
import multiprocessing
from sklearn.model_selection import GridSearchCV
param_grid = [
{
'kernel': ['linear', 'rbf', 'poly', 'sigmoid'],
'C': [0.1, 0.2, 0.4, 0.5, 1.0, 1.5, 1.8, 2.0, 2.5, 3.0]
}
]
gs = GridSearchCV(estimator=SVC(), param_grid=param_grid,
scoring='accuracy', cv=10, n_jobs=multiprocessing.cpu_count())
gs.fit(X, Y)
print(gs.best_estimator_) # SVC(C=1.5)
print('Kernel SVM score: %.3f' % gs.best_score_) # Kernel SVM score: 0.880
Azure - Day1 储存体帐户 (Storage Accounts)
Home -> 资源群组(Resource Groups) -> 储存体帐户(Stor...
[Python 爬虫这样学,一定是大拇指拉!] DAY17 - 爬虫事前准备
爬虫事前准备 本篇章之後将进入爬虫环节,但开始撰写程序前,我们先来安装会使用的套件吧! 本系列文将使...
[Day23]Virtual Service
上一篇的Bookinfo这个服务中,我们有使用samples/bookinfo/networking...
【Day13】漏洞分析Vulnerability Analysis(二)
哈罗~ 昨天安装完了Window版的Nessus, 今天来做一个简单的扫描实作。 首先先打开浏览器进...
Day.1 前言
今年是第二次参加,这次一样努力以不断赛为目标 不知不觉默默已经工作好一阵子了,从一开始觉得演算法好像...