[Day22] NLP会用到的模型(五)-self-attention
一. self-attention的编码方式
昨天说明了注意力主要是要明确算出input与output之间相关的资讯量,那怎麽算呢,这边我会说明现在最常使用的self-attention的方法。
self-attention其实就是会将每个词会将其他词的资讯考虑进去,也就是在对某一个词的做编码时,将整个句子的上下文语境考虑进去,以李孟的这篇文章[1]提到的例子来说明:
句子1: 胖虎叫大雄去买漫画,回来慢了就打他
句子2: 妹妹说胖虎是「胖子」,他听了很不开心
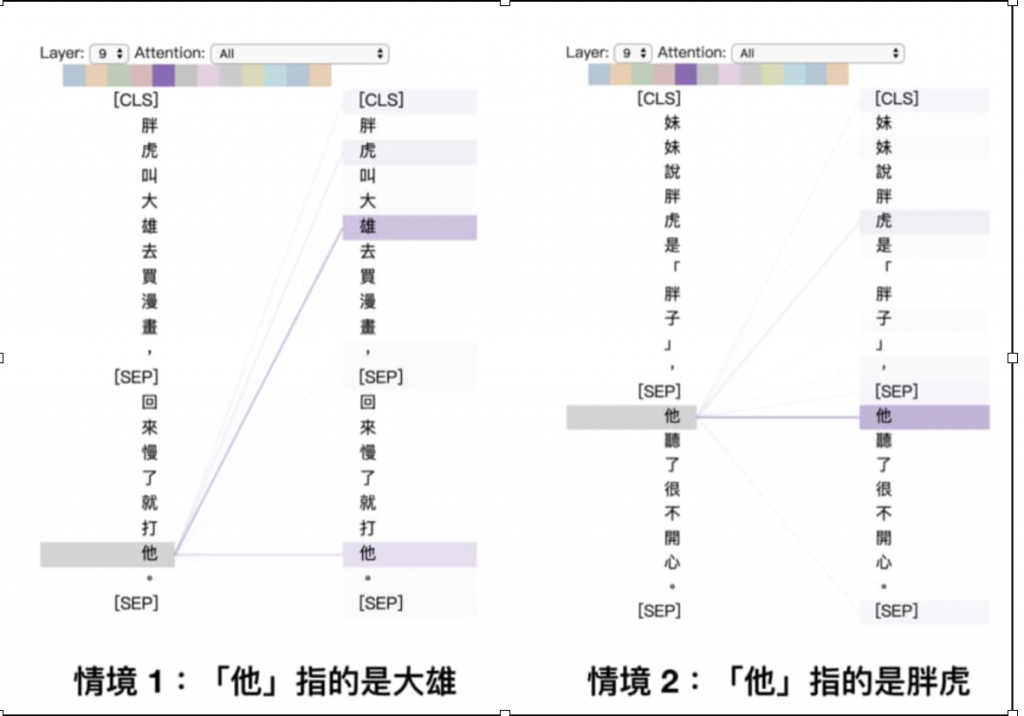
这2个他代表的人不同,第一个句子他应该要接收较多的'大雄'这个资讯,第二个句子他应该要接收较多的'胖虎'这个资讯,藉由这样去计算每个词与每个词之间的相关程度,最後就可以encdoe出一个适合这个句子的编码罗~~
二. 计算方式
目的: 得到一个可以代表句子文章且考虑上下文的编码向量
这边我会用这个网站[2]的图来解说~这网站写的其实非常详细了,各位也可以详读全,需要有三个矩阵来计算: Queries、Keys与Values,假设现在有一个句子叫做'Thinking Machines':
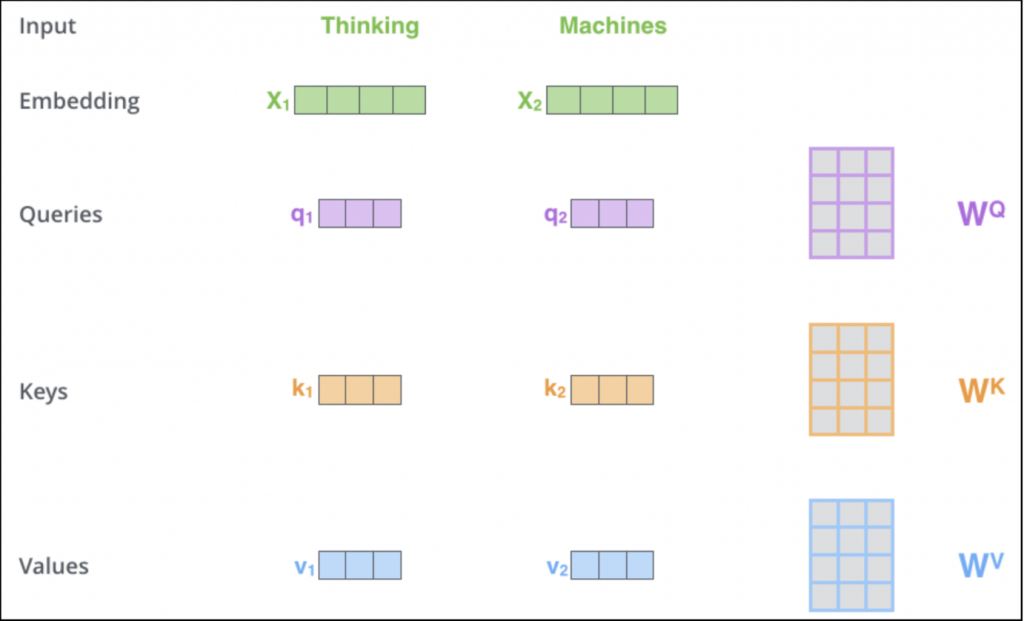
那要怎麽利用这三个矩阵来得到Queries, Keys, Values及其意义:
• 利用训练三个矩阵WQ、WK及WV
• Q: query,需要查询的问题,ex: 第一个词(q1)想知道他在这个句子所占的资讯为何
• K: key,等着被查的答案群,q会跟所有k做计算
• V: value,实际的特徵讯息
如下图,我们将thinking(x1)与machines(x2)叠起来,随机产生三个矩阵(WQ、WK及WV,这三个矩阵是在train的时候会调整的):
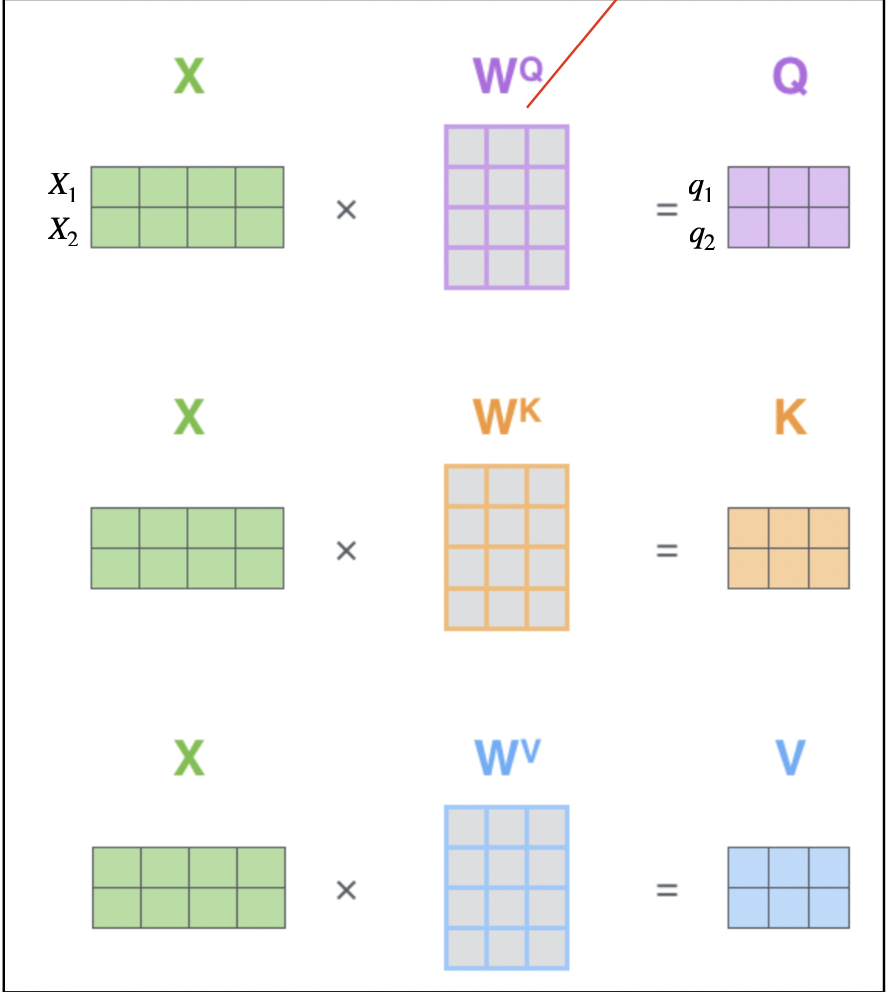
计算流程:
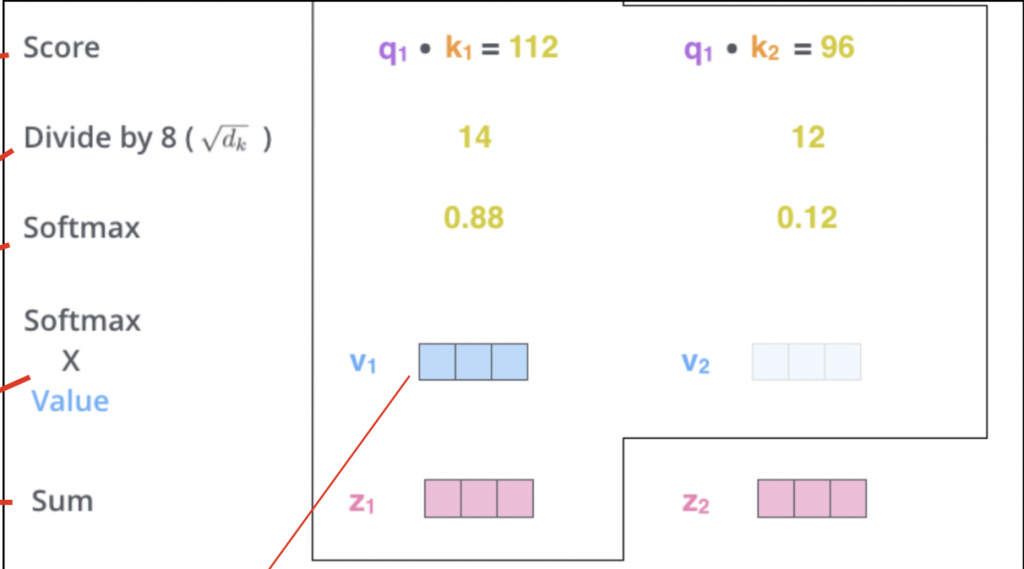
- 每个q会与每个k计算一个分数
- Scale dot-product attention: 第一点的值除以 根号dk 用来控制内积因随维度增大而变大的问题
- 利用softmax对数值进行normalize
- 第三点得出的值与v相乘得出词的编码向量
- 将第四点的每一个v相加,得到的就是这个词在整个句子的编码向量
如下图的z就是经过上述计算完後的句子编码向量:
--
以上大致就是self-attention的计算方式,transformer与bert里面都是这个东西而已XD
参考资讯
[1] https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html
[2] https://jalammar.github.io/illustrated-transformer/
IDS 的检测阈值(The detection threshold of IDS)
混淆矩阵中的敏感性是评估 IDS 性能的常用方法。 .一旦 IDS 发送警报,就应该对其进行调查和验...
Unity与Photon的新手相遇旅途 | Day24-Photon房间载入设定
今天内容为房间载入的程序码设定,明天会教大家如何测试。 ...
第29天-CSS-影像-(3-3)
背景位置 background-position 可以使用这个属性将背景图片指定到想要的位置 有以下...
[Day 30]铁人练成
终於来到第 30 天! 这篇的开头要献给 Outcome First 团队,从开始被团长 TD 偷拐...
iOS APP 开发 OC 第六天, 练习实作一个类
tags: OC 30 day 题目 请依照题目实作一个类: 类名:手机(Phone) 属性:颜色(...