[Day19] Tableau 轻松学 - Data Extract
前言
每当我们修改工作表或者仪表板的时候,Tableau Desktop 会立即进行运算以显示出对应的视图,这样的即时显示对我们资料分析来说是非常加分的。但是,若遇到资料集有百万甚至上千万笔资料,每一步修改所造成的运算量是非常可观的,有可能每修改一个地方就需要等待数分钟甚至更久的时间才能看到结果,对於时间宝贵的我们来说,这是一个急需被解决的问题。因此,这里分享如何使用 Data Extract 来缓解这样的问题。
Data Extract
说明
Data Extract 能让我们先从原本的资料集 (例如:资料库) 中撷取资料放到 Tableau 自己的资料档案 Hyper (.hyper),Hyper 格式对大型资料集进行了优化,使 Tableau Desktop 可以透过快速资料引擎 (Fast Data Engine) 对存放於 Hyper 档案中的资料集快速地进行查询与分析处理,避免与资料集源头直接连线。
使用
在 Data Source 页面的右上角,会看到 Connection 区域有 Live 与 Extract,Live 指的是与资料源头连线是即时的,所有的动作都是与资料源头即时互动;而 Extract 就是我们所说的 Data Extract,会将资料集的资料先存一份到 Hyper 档案中,之後的所有操作都是与 Hyper 档案来做互动。这里选择 Extract 即可使用 Data Extract 的功能,若还需要进一步设定,可以点击位於 Extract 右边的 Edit 来做设定,通常会使用到的是 Extract Filters,让我们可以在资料源头就先过滤掉不需要的资料
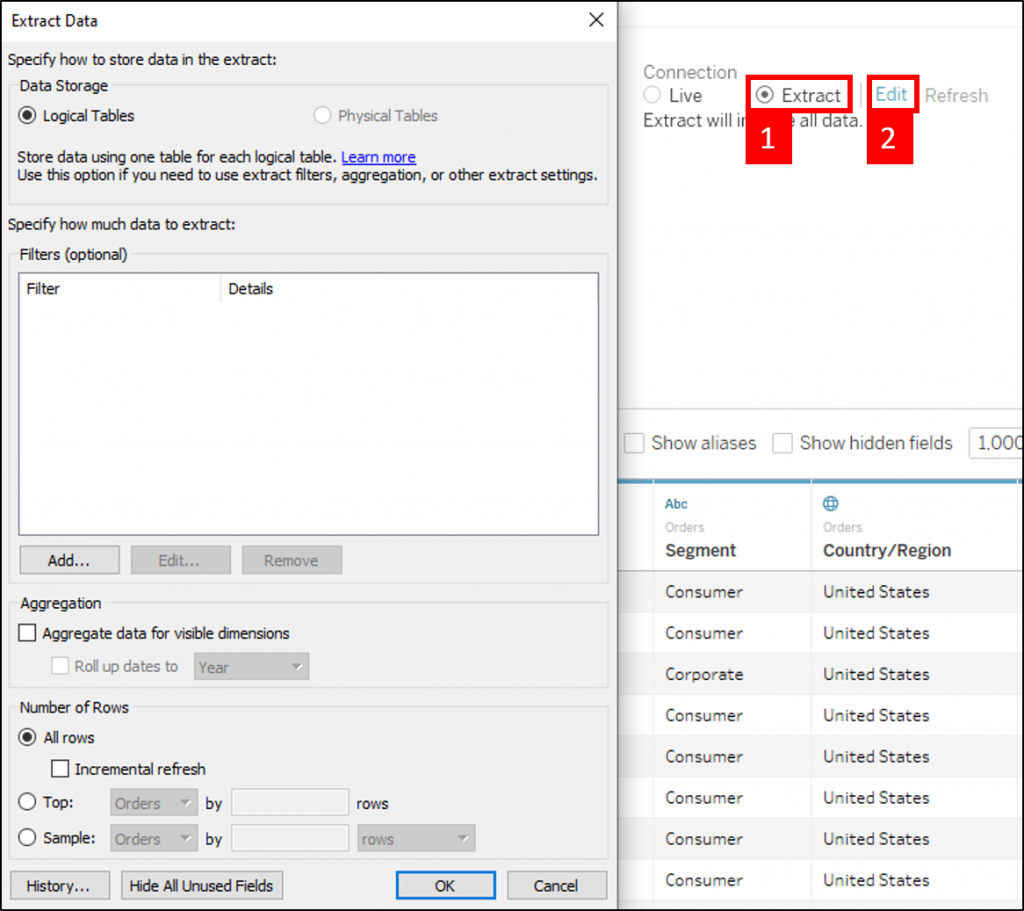
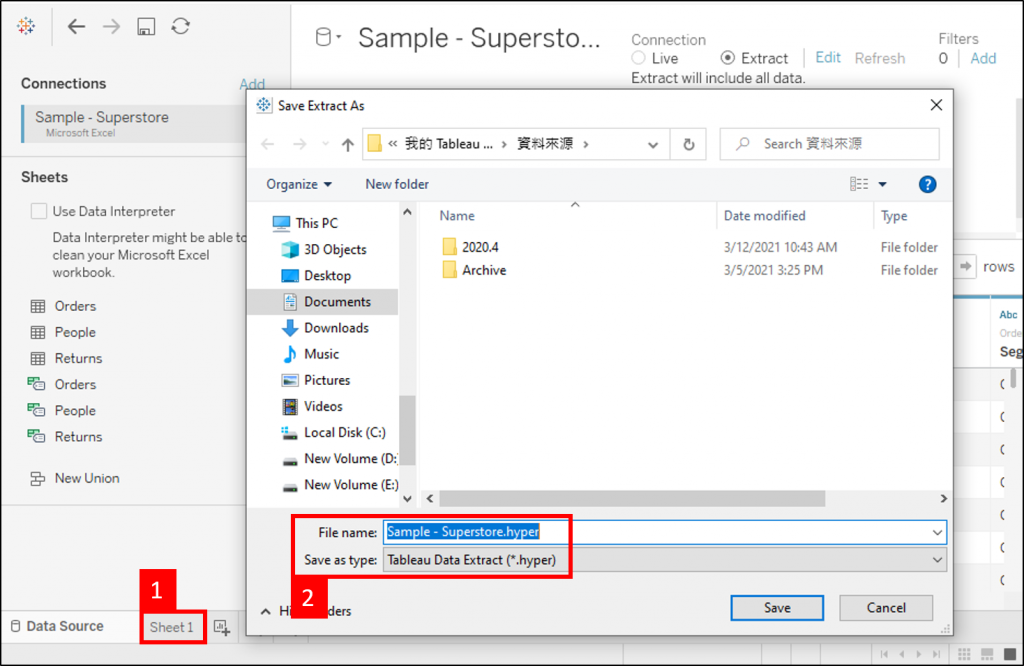
当我们离开 Data Source 页面时 (例如:切换到其他工作表或仪表板),Tableau Desktop 会请我们选择要存放 Hyper 档案的路径,成功储存才能使用 Hyper 资料格式所带来的种种好处
结语
曾经遇过千万笔的资料集,实作时是选择 Live 与资料库连线,导致每个步骤的修改都要等上一两分钟,後来向前辈请教才知道 Data Extract 的好处!分享这个好用的小秘诀给读者。
>>: 【Day 20】JavaScript 流程控制与例外处理
Day 18 Chatbot integration- Face Login- 人脸登入
Chatbot integration- Face Login- 人脸登入 这边要做的事情不是用人脸...
【JavaScript】很适合今天的NaN
【前言】 本系列为个人前端学习之路的学习笔记,在过往的学习过程中累积了很多笔记,如今想藉着IT邦帮忙...
[Day16] MySQL 简介
之前我们在写 API 程序的时候,一开始使用写死在程序里的资料集合(List),这个方法虽然快速让我...
LeetCode解题 Day30
698. Partition to K Equal Sum Subsets https://leet...
DAY28-SQL语法(VIEW实作)
今天要用第二个方法来建立虚拟资料表(VIEW),就是用T-SQL语法来写,先来看看他的语法: WIT...