[Day 05] 当我~们同在一起在17在17 (k-means 理论篇)
前言
有一说一,表情辨识到底还是个分类任务。
如果我说有一种演算法可以在不需要标签的情况下自动帮我们分组,你相信吗?
那就叫分群演算法(clustering)!
机器学习可分成三种:
- 监督式机器学习:有输入资料(X)且也有全部的标签(y)
- 非监督式机器学习:有输入资料但没有标签。
- 半监督式机器学习:有输入资料,但只有一小部分有标签。
分群演算法适用在第2、3种情况,
而今天最经典的分群演算法当属k-means了!可能连高中生也听过
监督式: 没什麽好说的

半监督: 什麽是伪标签(pseudo-label)?
所谓的pseudo-label是指我们在做半监督式学习时,
给予未标签的资料一个伪标签。(好饶舌)
-
假设我们有两组训练资料,但其中一组资料为unlabeled data
-
我们用labeled data那组去训练一个机器学习模型(Model A)
(这里的机器学习可以是监督也可以是非监督,但由於已经有label了,在此推荐用监督) -
Model A已经学会将资料分类了,於是我们将Model A对unlabeled data进行预测分类即生成伪标签。
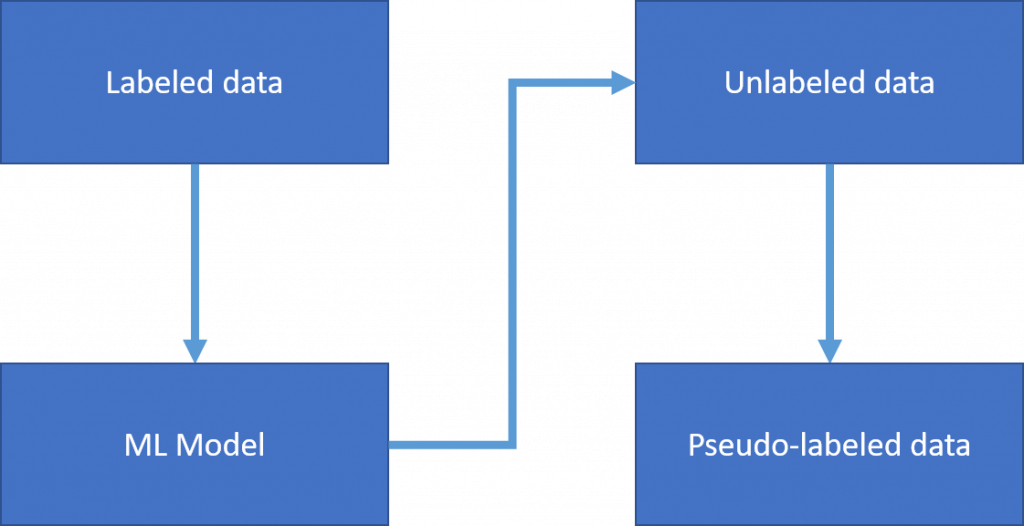
-
接下来我们合并labeled data和pseudo-labeled data,训练出一个完整的机器学习模型(Model B)
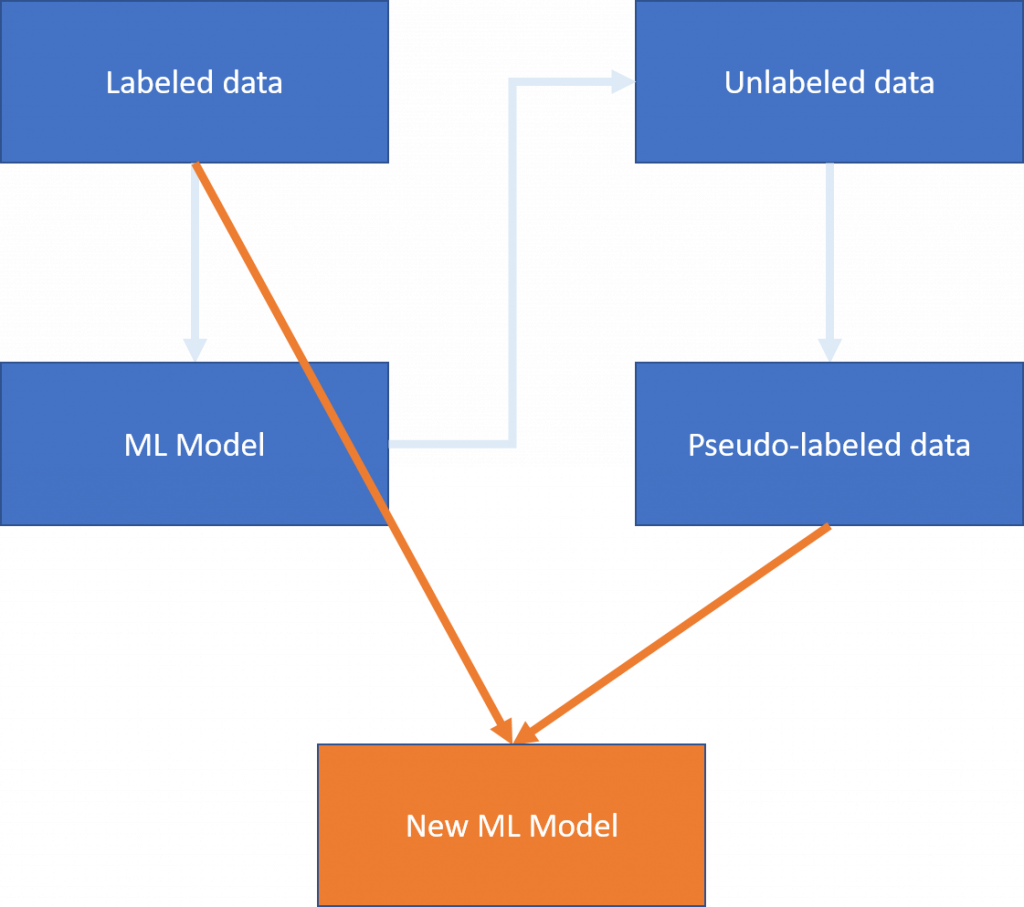
修但几勒!那如果我们一开始就完全没有labeled data怎麽办?
非监督:对没有标签的资料进行分组!
试想你是一个国一新生班级的导师,
今天是开学第一天,你要帮大家分组,但对於学生们完全不熟,
於是你想出一个奇招...
导师:我在这边选出三位小组长(⊕)
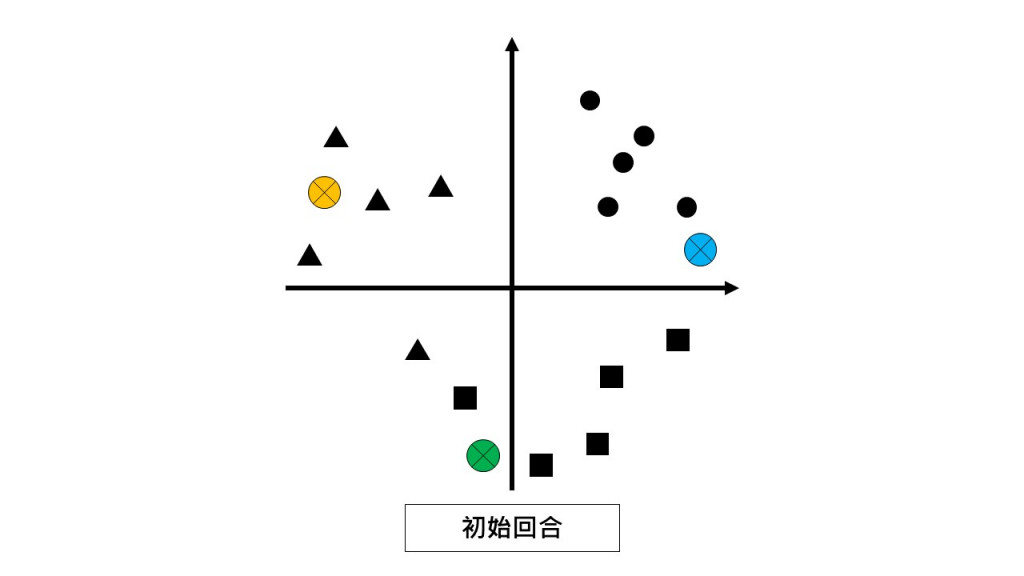
第一回合:请同学们都不要动,根据和你离最近的小组长回报你是哪一组的。(E-step)
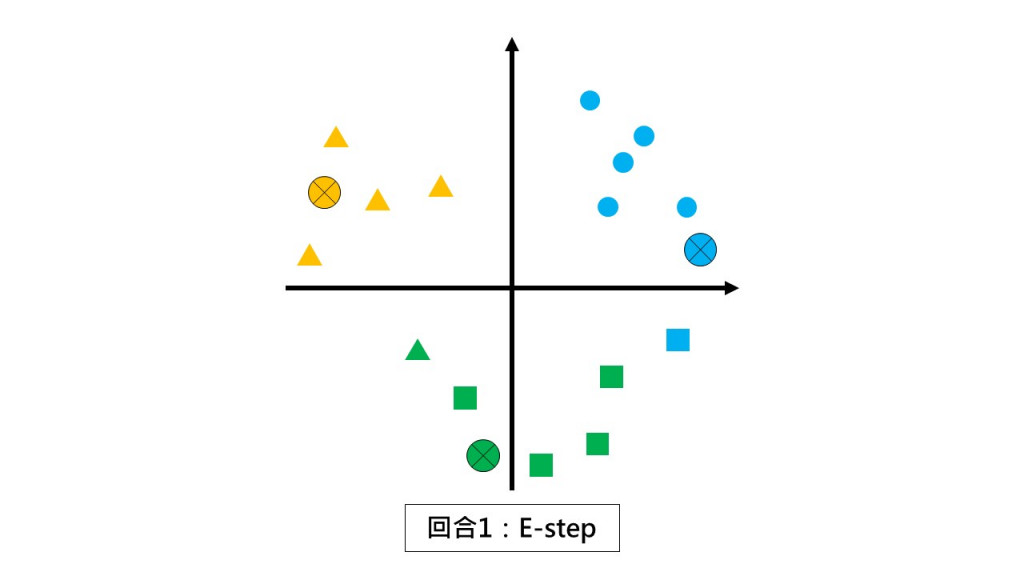
第一回合:请各组以组中心的位置当作新小组长。(M-step)
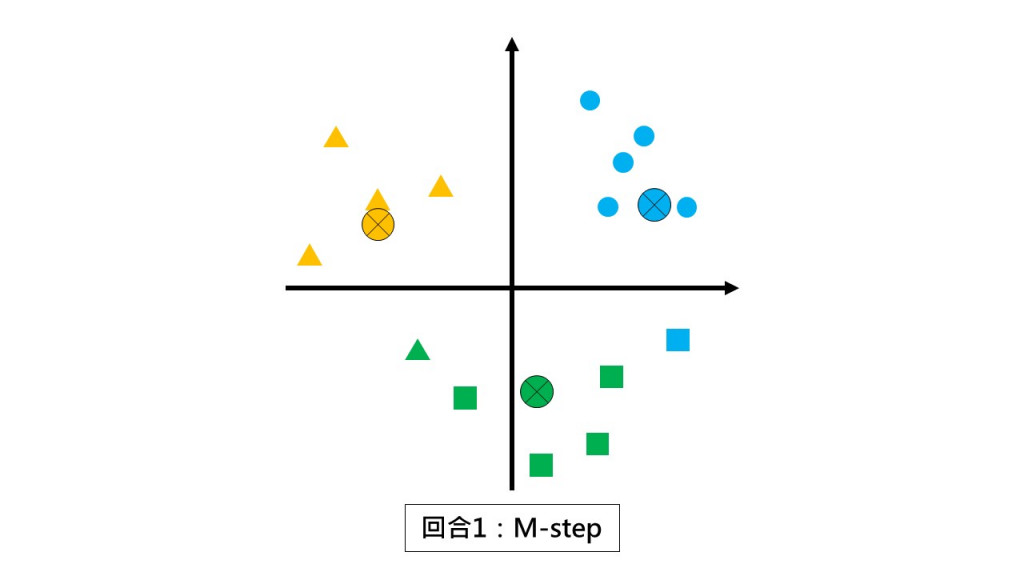
第二回合 E-step:请同学们都不要动,根据和你离最近的小组长回报你是哪一组的。
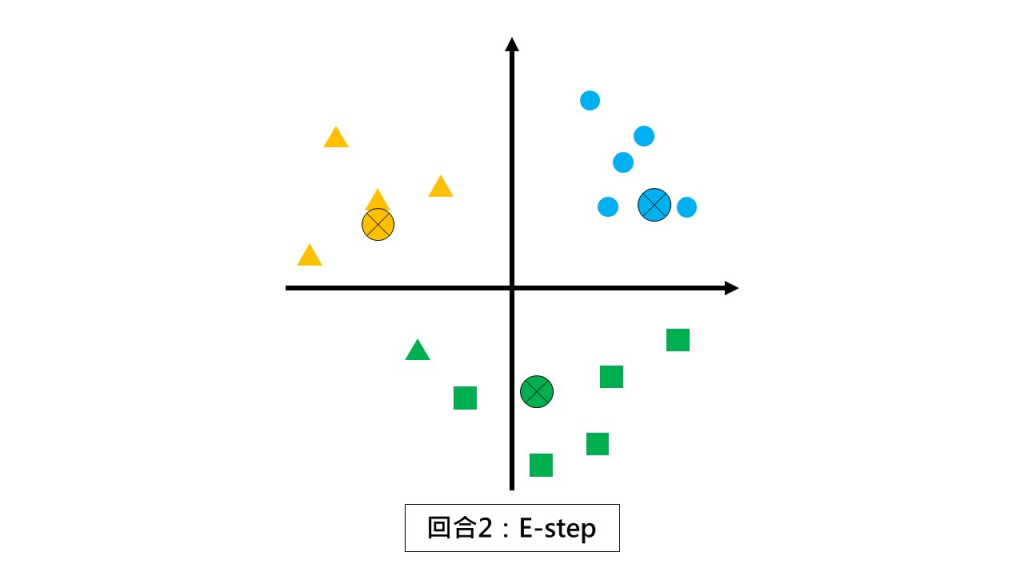
第二回合 M-step:请各组以组中心的位置当作新小组长。
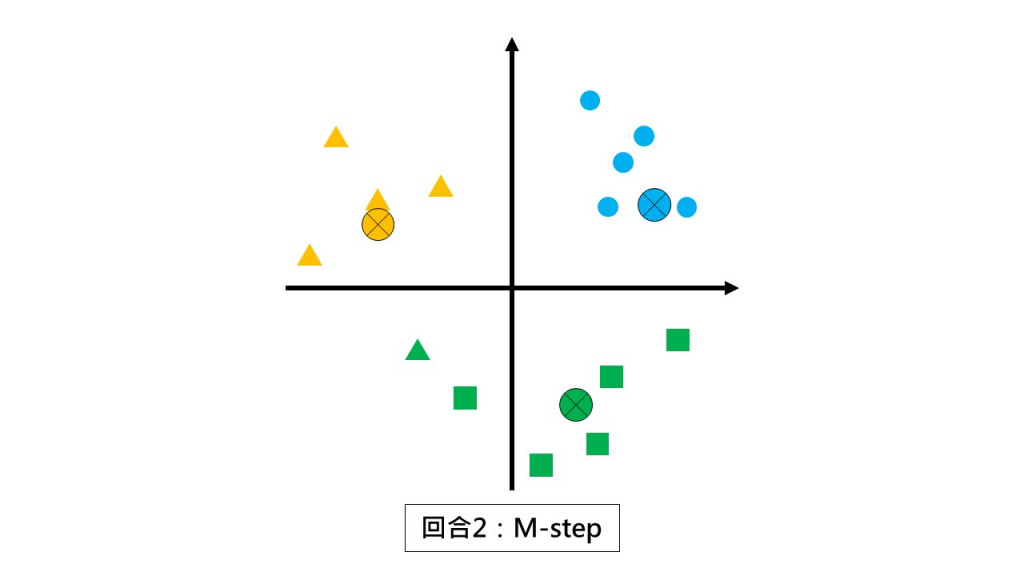
第三回合 E-step:请同学们都不要动,根据和你离最近的小组长回报你是哪一组的。
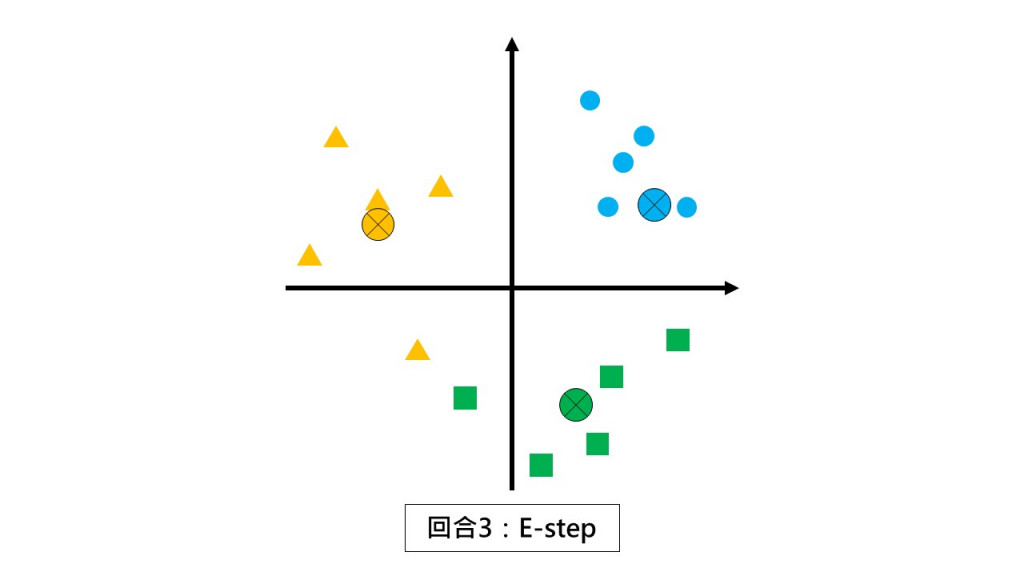
第三回合 M-step:请各组以组中心的位置当作新小组长。
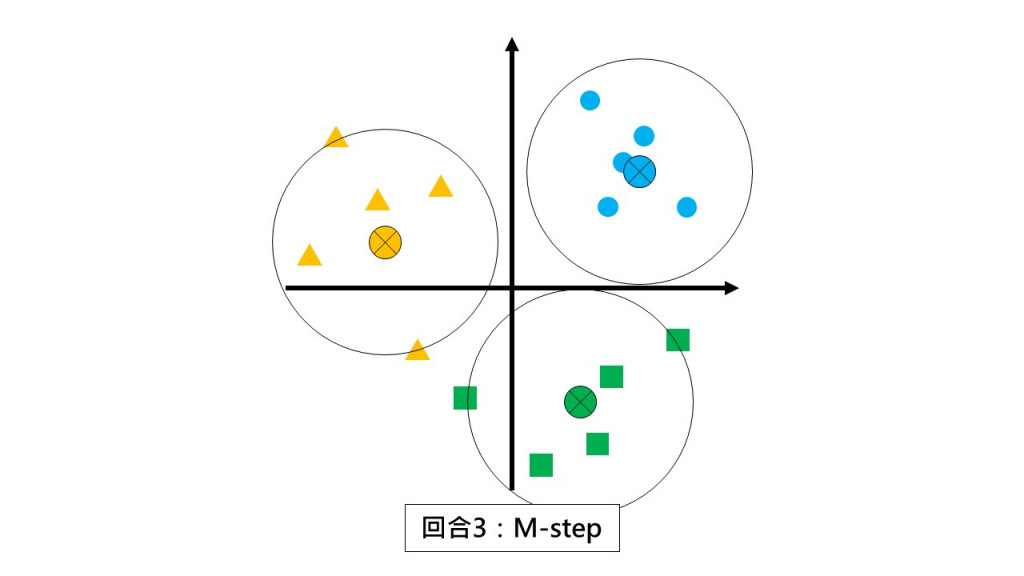
好了,这时候你就会发现:
你在完全不知道学生原本是三角形、圆形或方形的情况下,
成功把它们分群了,而且分出来的三群刚好分开了三种类型的学生
而这就是k-means演算法!
k-means 演算法介绍
这时候你就要问了:什麽是 E-step 和 M-step ?
EM全名为Expectation-Maximization,EM演算法又称最大期望演算法。
E-step为计算期望值,M-step则为最大概似估计,用来更新E-step上的隐藏参数。
在k-means中,这个参数就是平均值(μ)。
演算法数学式:
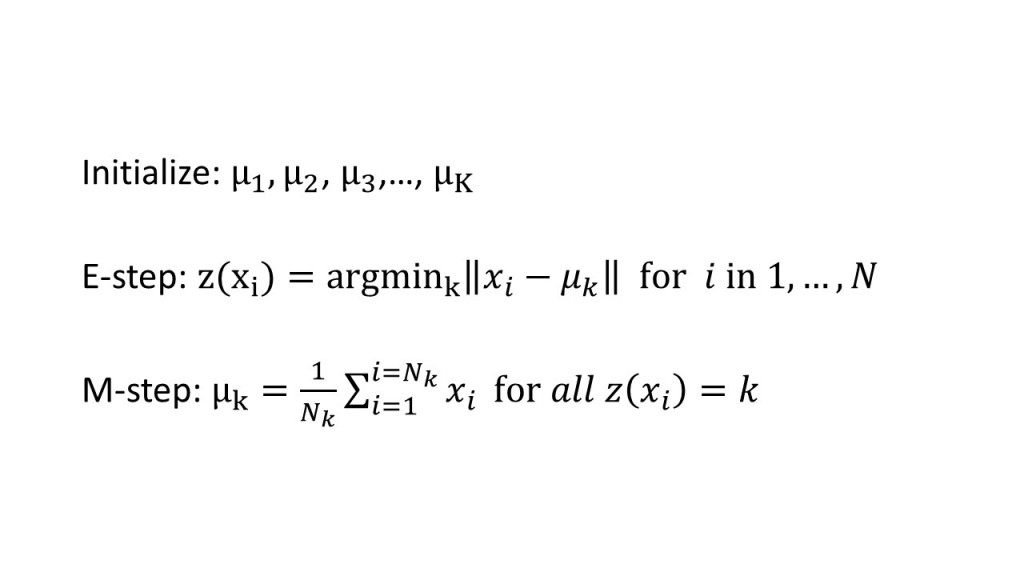
k-means流程如下:
- 初始化k个平均值(组中心)
- 执行E-step,让各个点依造在各组的最大机率去决定归附在哪一个组。
- 执行M-step,更新各组平均值(μ)
- 回到2.,直到收敛为止。
为什麽会收敛?
想像我们有一个损失函数,其计算方式为该组的点与组中心的距离平方和。
如何让这个损失函数最小化呢?那就是用选用x的平均值取代所有x,
而这个步骤其实就是M-step在做的呢!
结语
理论介绍完了,今天也快结束了。
明天让我们进入k-means实作吧!
冒险村14 - counter cache
14 - counter cache 在许多情况下,会需要统计一对多关联的资料数量。举例来说像是 U...
企划实现(25)
在fragment里面使用元件 常常在写程序时会遇到再fragment抓不到元件的事情 用这个方式就...
数据分析的好夥伴 - Python基础:资料形式(下)
接下来让我们来一一认识在Python里面的容器:容器型态:串列(list)、字典(dict)、元祖(...
[day22] 快速产生测试资料
功能测试时很常需要删掉坏掉的资料库纪录,这时就需要重置测资,但每次都开管理工具来做太麻烦了,写个小工...
[JS] You Don't Know JavaScript [Scope & Closures] - The Module Pattern
前言 在本章节中将介绍这本书最重要的程序组织之一,module,module会用到我们之前所介绍的所...