Day 14 储存宝石:S3是什麽? S3 vs EBS 方案比较

今天我们将来了解 S3 与 EBS 这两种储存方案的各自特点,并为大家介绍 AWS S3 在整体架构中的基本定位。
AWS S3 及 EBS 的储存类别比较 (Storage)
AWS 服务中的 S3 及 EBS 的类别,分别对应 Object-Level Storage (下图#1)及 Block-Level Storage (下图#2)。

AWS S3 及 EBS 的功能比较 (Operation)
S3 与 EBS 能做的事情不同,S3 能做到创造(Create)与删除(Delete)(下图#1);而 EBS 除了创造(Create)与删除(Delete),甚至能做到修改(Edit)(下图#2)。
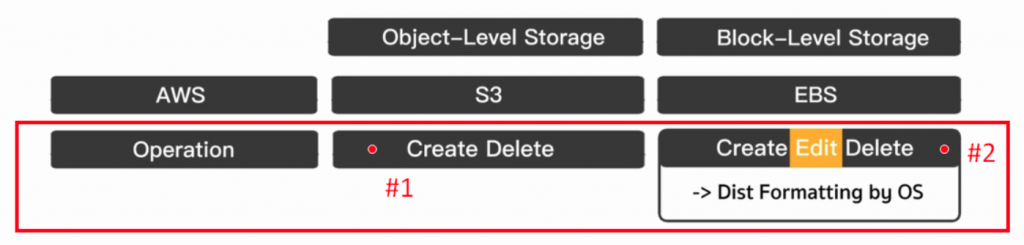
S3 的功能 (Operation)
S3 只能做到创造(Create)与删除(Delete)(下图#1),也就是我们只能把一个完整的档案上传上去,或者把上面已存在的完整档案给直接删掉,我们不能开启一个档案,对里面的某一行进行修改,这是 Object-Level Storage 类别的一个小缺点(下图#2)。

EBS 的功能 (Operation)
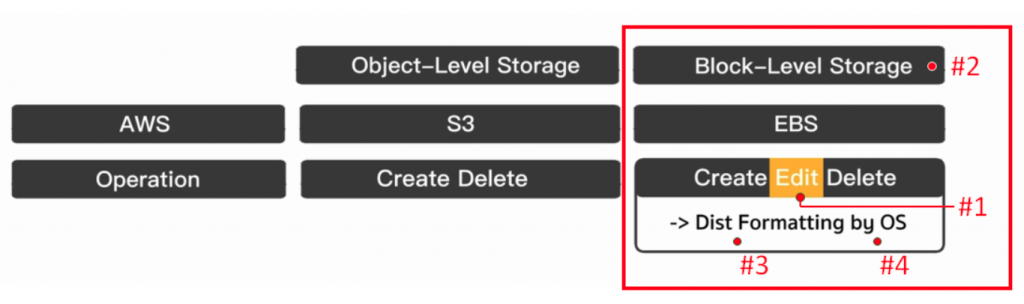
为什麽 EBS 能够比 S3 多出一个修改(Edit)功能呢?(下图#1)
这是因为 EBS 是 Block-Level Storage 类别(下图#2),所以当我们想要挂载到任何一台 EC2 Instance 的时候,都需要先进行硬碟格式化(Dist Formatting)(下图#3),并且这个硬碟格式化还要根据不同的作业系统来做(下图#4)。
透过这个方式,作业系统才会知道如何去使用这个硬碟空间,正因为更了解这个硬碟空间的格式,才能针对一个档案,打开并对其进行新增或修改。
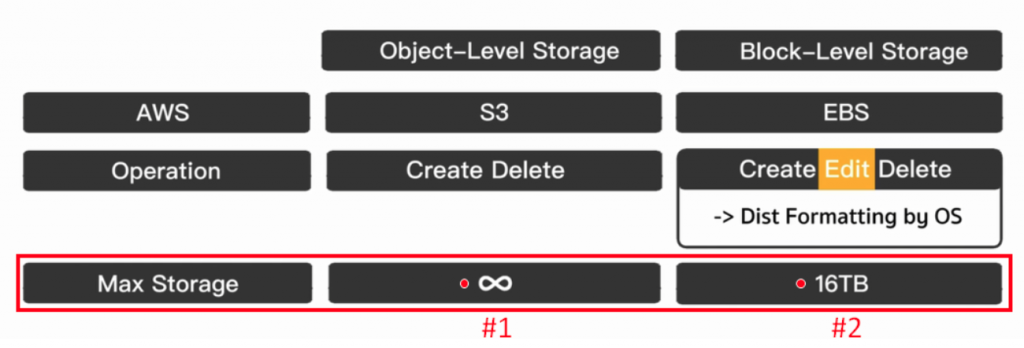
AWS S3 及 EBS 的最大的储存空间 (Max Storage)
我们可以从下图看到指标最大的储存空间,S3 最大是无限(下图#1),EBS 最大则只能存到 16TB (下图#2),也就是与 EBS 相较下,S3 远远能够无上限并不停的存放。
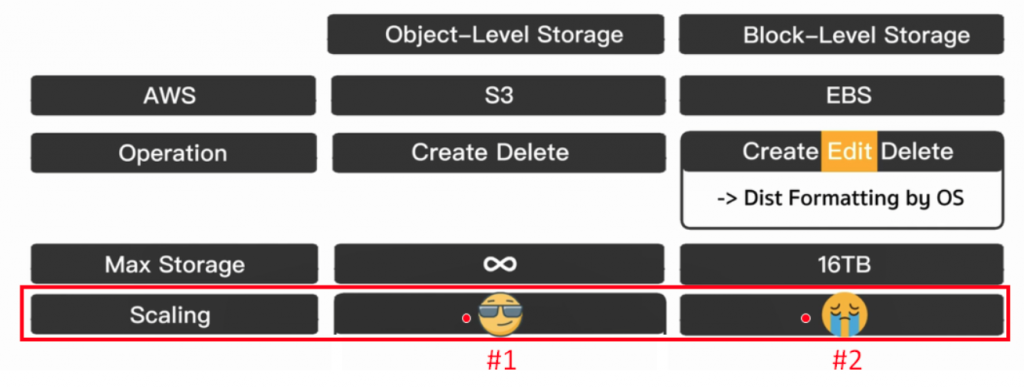
AWS S3 及 EBS 的 Scaling 比较
在面对更大需求的时候,S3 在 Scaling 的方面相较於 EBS 是非常厉害的(下图#1),而 EBS 则非常的不好(下图#2),下面我们将细部说明原因。
S3 的 Scaling
背後原由是 S3 其实是一个分散式系统,AWS 会一次启动多台的 Server 来应付所有的 S3 请求,所以 S3 的 Scaling 是非常的强大的。
譬如下图以 1 个 ● 代表 1 个 Server,并且 S3 有可能一次启动 8 台 Server 来应付请求,但这样强大的 Scaling 也带来了一点小副作用。
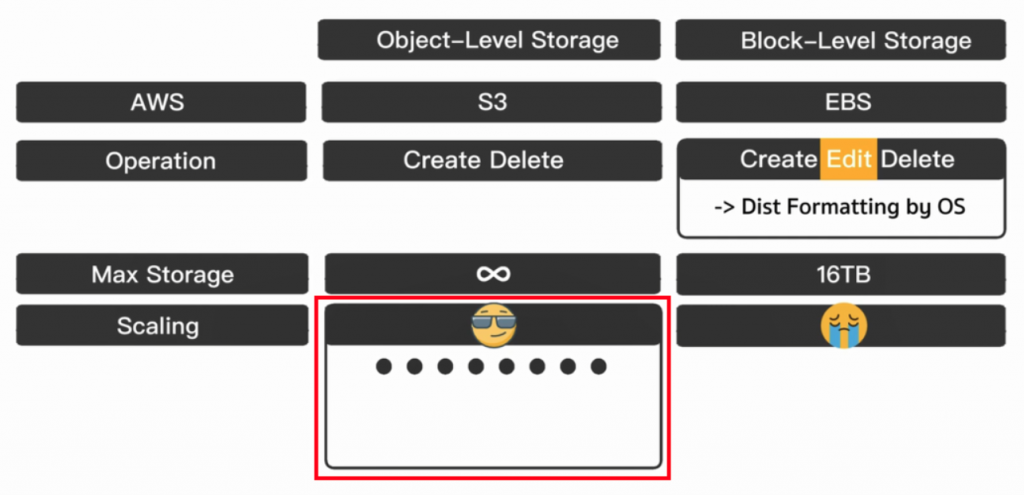
假设我们上传一个新的档案,它有可能不会瞬间的直接同步到 8 台的 Server 上面,只同步到 6 台 Server (下图#1)。而如果这麽恰好的,後面的请求刚好撞到这两台还没跟前面同步的 Server (下图#2),我们是有可能会拿到不同步的档案的。
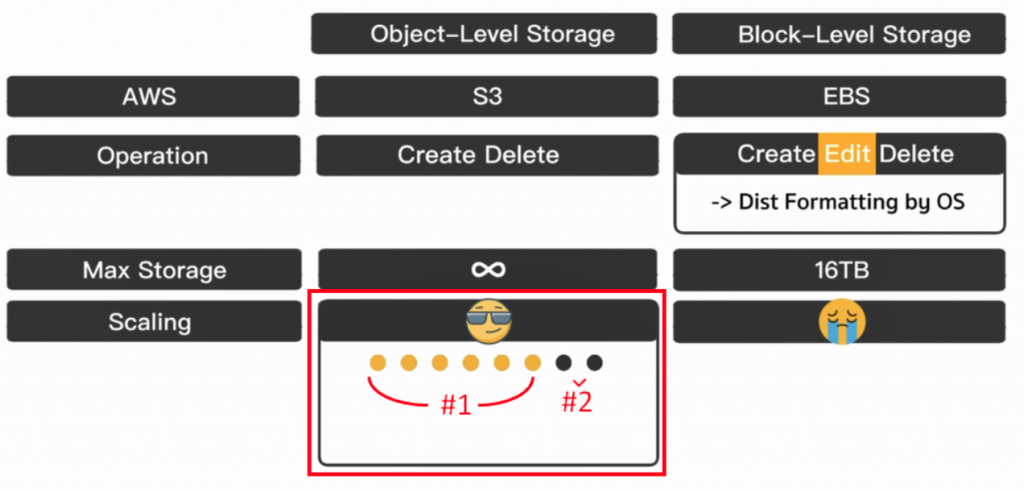
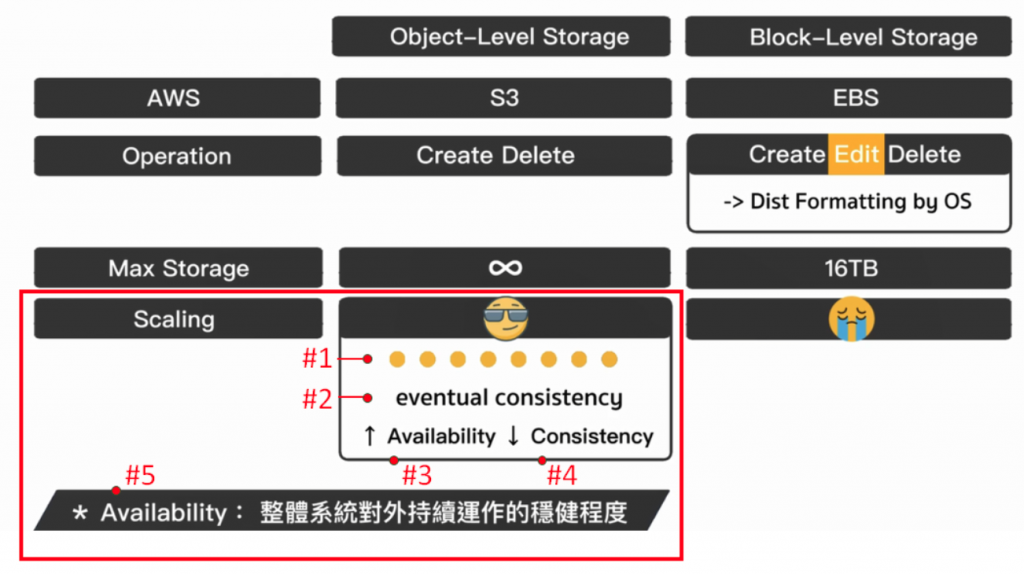
如果等得够久,最後 8 台 Server 都会同步拥有最新档案的版本(下图#1),而这样的特点有一个特别的词叫做 Eventual Consistency (下图#2),即最後会同步的意思。
在 Eventual Consistency 这个概念下所做的(下图#2),即是为取得更高的 Availability (下图#3),就算是牺牲一点资料的一致性也在所不惜(下图#4)。此处的 Availability,指的是整体系统对外持续运作的稳健程度(下图#5)。
举例来说,假设有 8 台 Server,我们不那麽在意资料是否永远一致(下图#4),我们更在意的,是客户端有请求来的时候,是否能够去回应它(下图#3),这个就是我们所说的 Availability (下图#5)。
小结
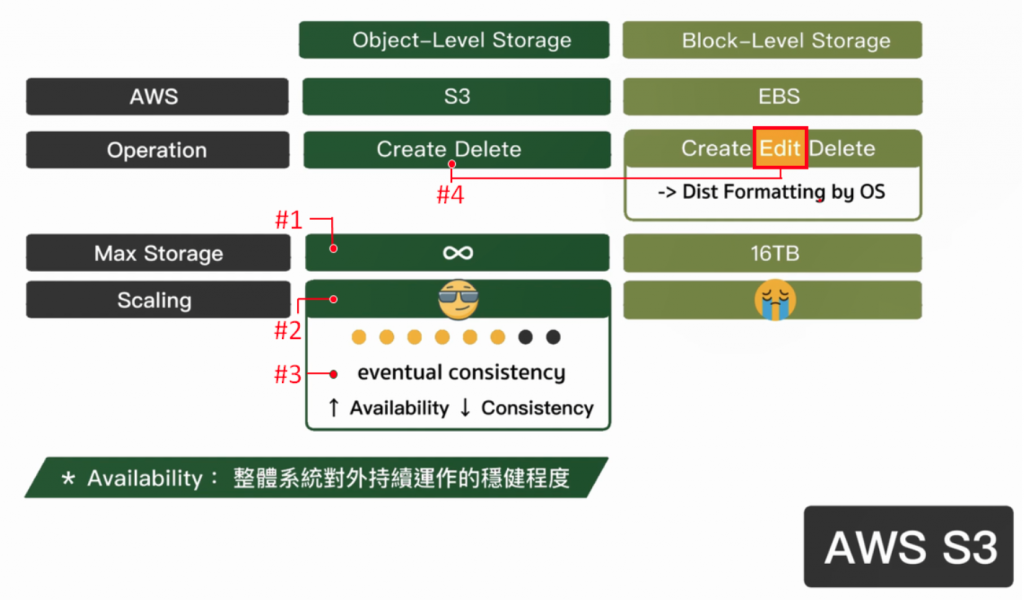
下图为本单元推导出的架构图,从中可以看到 S3 的优点,就在於最大的储存空间无限(下图#1)、Scaling 很强(下图#2),但带来一个小副作用叫做 Eventual Consistency (下图#3),并且还有一个小缺点,那就是 S3 不能对档案进行内部的修改(下图#4)。
What's Next?
那麽明天,我们将接着介绍「储存宝石:S3 架构 & 版本控管 (Versioning)」!
<<: Day4 用MR体验现实世界中办不到的事情或是事先体验将要做的事情
模型架构--2
SphereFace 在2017年发表在CVPR的文章,改进原先使用softmax作为loss fu...
【第二十天 - Graph 介绍】
Q1. Graph 是什麽 Graph 定义:一个 graph 由 数个点( vertex )与数个...
Day 11 运算宝石:EC2 储存资源 EBS Types 方案比较
今天我们要来介绍 EBS Type方案比较,那我们开始吧! 在之前的文章中我们有提过,EBS 相对...
人脸辨识的流程--特徵撷取
人脸辨识系统有三个步骤,人脸侦测、特徵撷取、人脸识别。 特徵撷取(Feature extractio...
【LeetCode】当初的 LeetCode 学习
有点受不了没什麽演算法底子还要掰出 Leetcode 文章QQ 今天来记录当初学习的过程和後来的想法...