树选手2号:random forest [python实例]
今天来用前几天使用判断肿瘤良性恶性的例子来执行random forest,一开始我们一样先建立score function方便之後比较不同models:
#from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score
def score(m, x_train, y_train, x_test, y_test, train=True):
if train:
pred=m.predict(x_train)
print('Train Result:\n')
print(f"Accuracy Score: {accuracy_score(y_train, pred)*100:.2f}%")
print(f"Precision Score: {precision_score(y_train, pred)*100:.2f}%")
1. 1. print(f"Recall Score: {recall_score(y_train, pred)*100:.2f}%")
print(f"F1 score: {f1_score(y_train, pred)*100:.2f}%")
print(f"Confusion Matrix:\n {confusion_matrix(y_train, pred)}")
elif train == False:
pred=m.predict(x_test)
print('Test Result:\n')
print(f"Accuracy Score: {accuracy_score(y_test, pred)*100:.2f}%")
print(f"Precision Score: {precision_score(y_test, pred)*100:.2f}%")
print(f"Recall Score: {recall_score(y_test, pred)*100:.2f}%")
print(f"F1 score: {f1_score(y_test, pred)*100:.2f}%")
print(f"Confusion Matrix:\n {confusion_matrix(y_test, pred)}")
在random forest的模型里,重要的参数包括:
- n_estimators:想种几棵树
- max_features:要包括的参数数量,可以输入数量或是“auto”, “sqrt”, “log2”
- “auto”>> max_features=sqrt(n_features).
- “sqrt”>> then max_features=sqrt(n_features) (same as “auto”).
- “log2”>> then max_features=log2(n_features).
- max_depth(default=None): 限制树的最大深度,是非常常用的参数
- min_samples_split(default=2):限制一个中间节点最少要包含几个样本才可以被分支(产生一个yes/no问题)
- min_samples_leaf(default=1):限制分支後每个子节点要最少要包含几个样本
随後我们先来建一个最简单的random forest,并看看testing後的结果:
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=1000, random_state= 42)
forest = forest.fit(x_train,y_train)
score(forest, x_train, y_train, x_test, y_test, train=False)

接下来试试看tuning,这里我们用cross validation来寻找最适合的参数组合,使用的function为RandomizedSearchCV,可以把想要调整的参数们各自设定区间,接下来会随机在这些区间里选出参数组合去建模,用cross validation来衡量结果并回传最好的参数组合,RandomizedSearchCV重要的参数有:
- n_iter:想要试几种参数组合,
- cv: cross validation的切割数量
数字越大当然可以获得更好的参数组合,但选择的同时要考量运行效率,机器学习最大的两难就是performance VS time!
from sklearn.model_selection import RandomizedSearchCV
#建立参数的各自区间
n_estimators = [int(x) for x in np.linspace(start=200, stop=2000, num=10)]
max_features = ['auto', 'sqrt']
max_depth = [int(x) for x in np.linspace(10, 110, num=11)]
max_depth.append(None)
min_samples_split = [2, 5, 10]
min_samples_leaf = [1, 2, 4]
bootstrap = [True, False]
random_grid = {'n_estimators': n_estimators, 'max_features': max_features,
'max_depth': max_depth, 'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf, 'bootstrap': bootstrap}
random_grid

forest2 = RandomForestClassifier(random_state=42)
rf_random = RandomizedSearchCV(estimator = forest2, param_distributions=random_grid,
n_iter=100, cv=3, verbose=2, random_state=42, n_jobs=-1)
rf_random.fit(x_train,y_train)
rf_random.best_params_

接下来使用回传的参数组合来建最後的model罗!
forest3 = RandomForestClassifier(bootstrap=True,
max_depth=20,
max_features='sqrt',
min_samples_leaf=2,
min_samples_split=2,
n_estimators=1200)
forest3 = forest3.fit(x_train, y_train)
score(forest3, x_train, y_train, x_test, y_test, train=False)
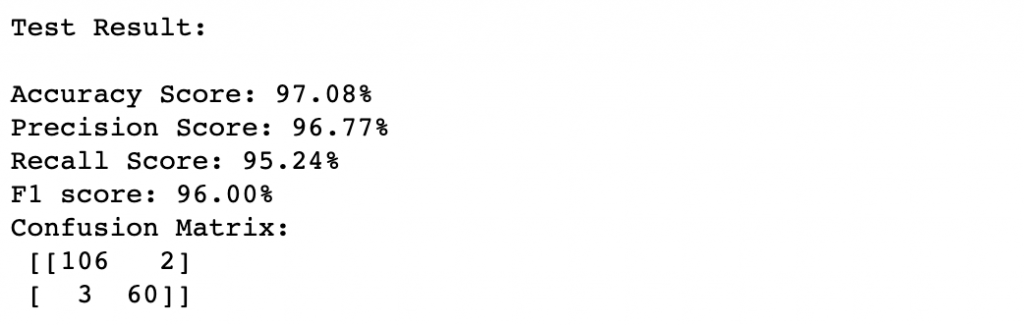
比较一下turning前後其实发现结果相差不大,我们可以再调整参数区间重复尝试,但这里想要说的是:很多时候比起去不停调整model参数,在建立model之前的feature engineering以及EDA过程,通常会对model表现带来更大的影响呦!
>>: Day 19 - Rancher App(v2.5) 介绍
Day 27 实作 user_bp (5)
前言 今天会完成 user_bp,也就是要完成看贴文跟留言的部分。 /posts 首先来看看可以看到...
Excel VBA 巨集设计问题 不同表格中VLOOKUP找资料
现在做了一个表格 内容如图下分了商品编号, 仓库号和仓库名 希望能输入商品编号後能自动带出仓库号和仓...
招募
今天来讨论一个很多新手主管都该不熟悉的题目:招募。 如果你是在大企业工作,你可能有专属的人资团队来...
软件开发 五层次的用户体验
软件开发中,产品经理在规划产品方案时,都会注意用户体验的部分,其实关於用户体验的部分 James G...
Day 21:非 GUI 类工具之三
JUCE 提供 juce::var 类别,可用来储存多种资料型别,如 int, int64, flo...