Day 17 - YOLO 相关概念说明
Day 17 - YOLO 相关概念说明
如果不说明一下 YOLO 的运作概念,对於如何调整 YOLO 参数将会是一筹莫展,所以今天就来说明一下影像辨识的基础概念一直到 YOLO 的运作概念
人工智慧、机器学习与深度学习
影像识别其实是深度学习的一种应用,而深度学习是机器学习的一个子集,机器学习则是包含在人工智慧这个大范围内。人工智慧当初的发想是希望透过计算机来取代人类的许多能力,可以包含五感,如视觉、听觉、嗅觉、味觉和触-压觉五种感官的感知,在透过大脑的思考来进行判断,广义上可以这样思考。而机器学习则势将这样的想法具体化成
- 监督式学习:已经知道答案(标签),然後透过演算法来训练机器来学习如何从特徵中找出答案,因为知道答案,所以比较容易评估演算法的表现。
- 非监督式学习:不知道答案,所以我们就透过演算法想办法凑出答案,常见的作法就是聚类 (clustering)。
- 强化学习:透过摸索、试误,并根据环境的回馈,来找出最佳答案。
这些学习的目的都是为了让机器可以协助人类进行判断,进而找出最佳答案,那现在问题来了,什麽是答案?简单来分,答案有两种,比方说,明天会不会下雨,可以说 80% 会下雨,或是说会下雨,专业一点的说法是一种是离散,一种是类别。
以下以 BMI 的标准来想像所谓的机器学习,假设我们不知道 BMI 的公式,而我们的到这样一张表格,体重状况就是的答案(标签)也就是我们要预测的目标,而 体重、 身高、 性别、年纪,就是特徵,现在就是要透过这些特徵来找出第四笔资料应该是什麽内容?很明显的,这就是一个监督式机器学习,而且是属於类别形的判断。机器学习的过程希望找出一个函数(模型),让我们将体重、 身高、 性别、年纪等特徵输入进去後,可以得到一个结果,可能是就是正常、过重或过轻。
| 体重状况 | 体重 | 身高 | 性别 | 年纪 |
|---|---|---|---|---|
| 正常 | 70 | 178 | 男 | 50 |
| 过重 | 77 | 165 | 女 | 40 |
| 过轻 | 45 | 170 | 男 | 30 |
| ? | 60 | 168 | 女 | 50 |
於是就有人想出,那能不能把整个判断式想成以下这个方程序,那问题就变得很简单,就是只要找出权重值就好。
$h_w(x)=w_0 x_0 + w_1 x_1 + \dots + w_d x_d=\sum_{i=0}^{D} w_d x_d$
其中:
- $x_0, x_1, \dots, x_d$为特徵,$D$为特徵的总数,以这个例子来说就是4
- $w_0, w_1, \dots, w_d$为权重参数
- $h_w(x)$代表判别式,用於根据传入的特徵预测输出结果
- $x_0$称为偏置项(intercept term/bias term),一般设置为1即可
面对上面这样的问题,很明显的我们需要做很多资料前处理的动作,比方说把男、女,转换成数值,当然,输出的结果(体重状况)也应该是个数值。这就是一个很典型的机器学习的例子,找出特徵,处理标签等等的,相信有很多人都可以发现,年纪似乎不是 BMI 计算的数值内容,性别也不是,这就是所谓特徵的相关性的问题,特徵与标签相关性的问题,把所有搞机器学习的人搞疯了,因为要进行机器学习之前必须先找出特徵,这导致很多机器学习的研究停滞不前了。後来,竟然有人想说,那是不是可以建立一个模型,让这个模型自己找出资料的特徵,於是深度学习就出现了。透过一连串神奇的操作後,特徵就自己跑出来了,而常见的技术就是 CNN, DNN。
关键名词解释
训练模型
卷积神经网路(Convolutional Neural Network, CNN):是 YOLO 应用的主要技术,透过 CNN 先找出符合的物体,之後再判断哪一区域有符合的物体,且机率最高,即将该区域以方框标注。以下大致描述一下 CNN 的内容。
卷积神经网路由一个或多个卷积层 (Convolutional) 和顶端的全连通层 (full-connection)(对应经典的神经网路)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网路能够利用输入资料的二维结构。与其他深度学习结构相比,卷积神经网路在图像和语音辨识方面能够给出更好的结果。下图就是 YOLOv3 用来萃取特徵的 darknet-53 的 53 层 CNN 网路,其中的 Residual 指的是残差层,主要是用来避免网路层数过多而造成的缺点。卷积神经网路(例如Alexnet、VGG网路)在网路的最後通常为 softmax 分类器。微调(fine-tuning)一般用来调整 softmax 分类器的分类数。例如原网路可以分类出 2 种图像,需要增加 1 个新的分类从而使网路可以分类出3种图像。微调可以留用之前训练的大多数参数,从而达到快速训练收敛的效果。例如保留各个卷积层,只重构卷积层後的全连接层与 softmax 层即可。
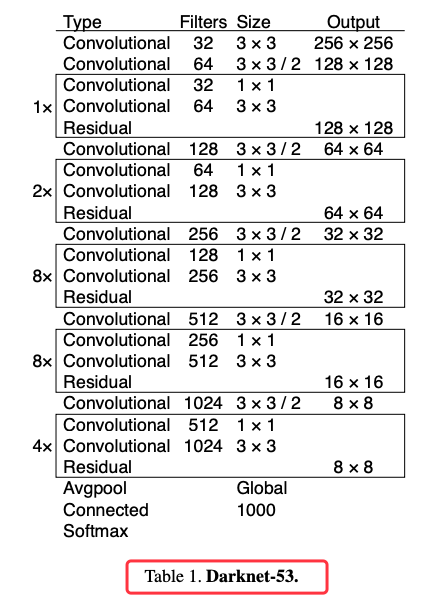
图 1、YOLOv3 的 darknet53
卷积层:是一组平行的特徵图(feature map),它通过在输入图像上滑动不同的卷积核并执行一定的运算而组成。
池化层(Pooling):它实际上是一种非线性形式的降采样。
激励层:线性整流层(Rectified Linear Units layer, ReLU layer),主要可以增强判定函式和整个神经网路的非线性特性,而本身并不会改变卷积层。
完全连接层:最後,在经过几个卷积和最大池化层之後,神经网路中的进阶推理通过完全连接层来完成。
训练过程
期 (epoch):1 个 epoch 等於使用训练集中的全部样本训练一次。
批次尺寸 (batchsize):一次训练的样本数目。
细分 (subdivisions):一次批次可以细分成几次放入记忆体内。
迭代 (iteration):一个 iteration 等於使用 batchsize 个样本训练一次;
epoch=(全部训练样本/batchsize)/iteration
举个例子,训练集有 1000 个样本,batchsize = 10,那麽训练完整个样本集(1次epoch)需要:100 次iteration。
1 = (1000 / 10) / 100
而通常在调整参数时,batchsize 是可以被调整的,考量的基础如下:
1.通过并行化提高记忆体利用率。
2.单次 epoch 的迭代次数减少,提高执行速度。
3.适当的 batchsize,可以使梯度下降方向准确度增加,训练震动的幅度减小。
但明显的是 batchsize 的大小是跟记忆体相关的。
成效评估
下图是根据 YOLOv3 的论文中撷取出来的图片,只能说这是给天才看的,我这个凡人实在无法想像,把关键线条画在图表的左边是什麽意思,执行时间是负的吗?因此,又找了一张图,是 YOLOV4 的作者画出来的,比较人性化了,可以发现 YOLOV3 速度是够快,但精准度似乎有点差强人意,这是在 Nvidia V100 的 GPU 运算速度。现在我们需要理解的就是,何谓 mAP。
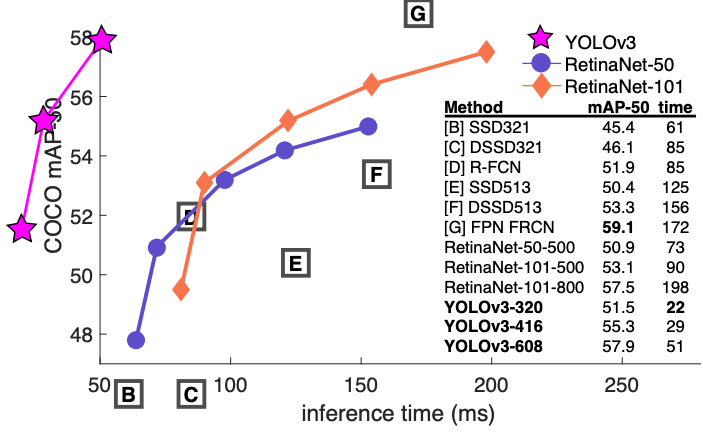
图 2、YOLOV3与多种影像辨识模型在微软的COCO资料集的效能表现
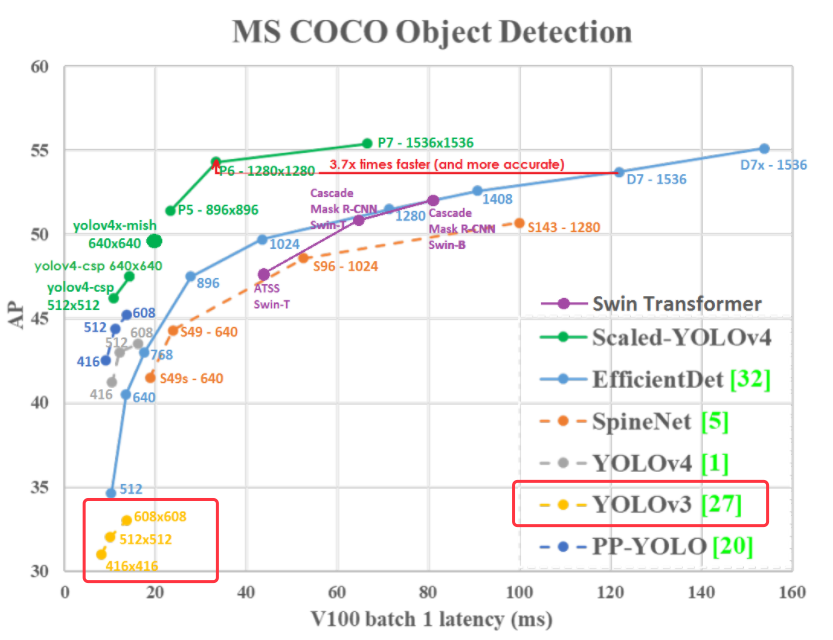
图 3、多种影像辨识模型在微软的COCO资料集的效能表现
预测结果可以细分为:
- True:表示实际结果与预测结果一致(预测正确)。
- False:表示实际结果和预测结果不一致(预测错误)。
- Positive:表示预测为 1。
- Negative:表示预测为 0。
上述各中情况将分别简写为:TP, FP, TN, FN。因此:
- TP:模型预测结果为P(Positive, 1),实际结果为 1,预测正确 (True)。
- FP:模型预测结果为P(Positive, 1),实际结果为 0,预测错误 (False)。
- TN:模型预测结果为N(Negtive, 0),实际结果为 0,预测正确 (True)。
- FN:模型预测结果为N(Negtive, 0),实际结果为 1,,预测错误 (False)。
根据上方情况,定义出以下的衡量指标:
-
正确率:$Accuracy=\frac{#TP+#TN}{#TP+#FP+#TN+#FN}$
- 体现了预测正确的样本数占总样本数的比重
-
精度:$Precision= \frac{#TP}{#TP+#FP}$
- 体现了预测为目标物且实际上也确实为目标物的比例。Precision 有另一个名字称作 Positive predictive value (PPV),它反映 「误报」 程度:精度越高,误报越小。
-
查全率:$Recall = \frac{#TP}{#TP+#FN}$
- 体现了:实际为目标物也确实被预测为目标物的比例,可以得知模型找出目标物的能力。Recall 也有另一个名字称作 Sensitivity。它反映 「漏报」 程度:查全率越高,漏报越少
-
$F1 Score = \dfrac{2 PR}{P+R}$
- 其中,P 为 Precision, R 为 Recall
- 在针对 Validation Data 进行对比时,应选择 F1 Score 最大的那个判别式来作为最优解
物体侦测除了要判断影像中的所有物体各自属於哪个类别之外,还要找出物体的位置。可想而知模型的好坏不能只单靠准确率来做判断,因此我们需要其他评估方式来判定模型的物体侦测能力。
Intersection over Union (IoU)
$IoU = \dfrac{Area of Overlap}{Area of Union}$
IoU 的概念还满简单的,就是评估预测的方块框 (bounding box) 与 真实的方块框 (ground-truth bounding box) 是否重叠的指标。一般情况下,如果预测的方块框被预测为确实有目标物存在,而且 IoU ≧ 0.5 (此 threshold 会依情况有所调整) 我们就认定此 bounding box 为 TP (True Positive),反之则为 FP (False Positive)。根据这个判断可以算出 Precision 跟 recall,而 AP (Average Precision) 就是计算 Precision-recall curve 底下的面积。详细的计算可以参考 mean Average Precision (mAP) — 评估物体侦测模型好坏的指标。
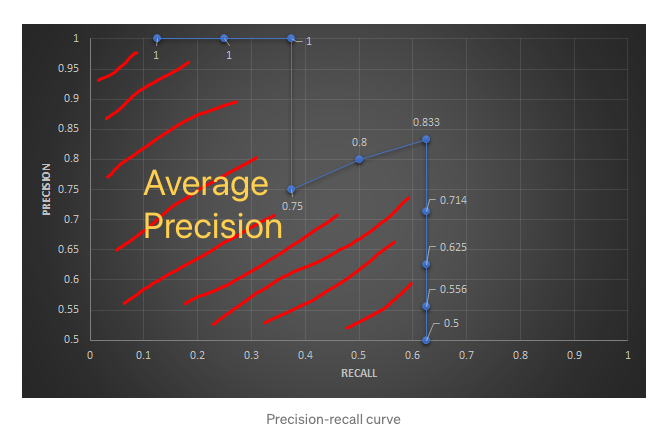
图 4、Average Precision的计算
mean Average Precision (mAP) 指的应该是当我们计算每一个类别的 AP 之後再作平均就会得到 mAP。以coco数据集来说,它有 80 个类别。
参考资料
- 卷积神经网路,https://zh.wikipedia.org/wiki/卷积神经网路
- (深度学习)ResNet之残差学习,https://medium.com/@hupinwei/深度学习-resnet之残差学习-f3ac36701b2f
- 详解残差网络,https://zhuanlan.zhihu.com/p/42706477
- Epoch, Batch size, Iteration, Learning Rate,https://medium.com/人工智慧-倒底有多智慧/epoch-batch-size-iteration-learning-rate-b62bf6334c49
- 神经网路中Epoch、Iteration、Batchsize相关理解和说明,https://codertw.com/程序语言/557816/#outline__3
- mean Average Precision (mAP) — 评估物体侦测模型好坏的指标,https://medium.com/curiosity-and-exploration/mean-average-precision-map-评估物体侦测模型好坏的指标-70a2d2872eb0
- The Confusing Metrics of AP and mAP for Object Detection / Instance Segmentation,https://yanfengliux.medium.com/the-confusing-metrics-of-ap-and-map-for-object-detection-3113ba0386ef
- YOLO v3 物件侦测~论文整理,YOLO v3 物件侦测~论文整理,https://medium.com/image-processing-and-ml-note/yolo-v3-物件侦测-论文整理-11ee909430c8
- 目标检测|YOLOv2原理与实现(附YOLOv3),https://zhuanlan.zhihu.com/p/35325884
- 目标检测|YOLO原理与实现,https://zhuanlan.zhihu.com/p/32525231
<<: [DAY 4] _ 用Keil5直接编写暂存器操控MCU的GPIO口_(建Keil5环境)
>>: Day2 Visual Studio Code 安装与设定
Day 11. slate × Interfaces × Document-Model
接下来的篇章我们会把目光聚焦於 interfaces/ 这个目录底下的内容,想确认 slate p...
Day17 X 初探快取 & HTTP Caching
今天即将进入 Caching & Networking 章节的第一天,快取,是一个非常重要...
Day31 ( 游戏设计 ) 猴子接香蕉
猴子接香蕉 教学原文参考:猴子接香蕉 这篇文章会介绍,如何在 Scratch 3 里使用更换造型、改...
[Day 30] SQLite 下
delete delete(String table, String whereClause, St...
Day20 React的严格模式
严格模式可以想成是React的debug工具,严格模式不会渲染出任何的UI元件,它会检查其包覆下所有...