案例:MLOps在医疗产业(下) - 3个局限性与4个学习要点
跟AI/ML 有关的监管考量
在前一篇的文章指出,在医疗产业中的监管文献有两篇。然而这两篇的内容其实都不是针对ML的案例而写的。在MDCG的另一个规范MDR/IVDR 框架下的指南当中,才有纳入ML的考量。
从ML系统可以利用现有的医疗资料替病患提供更有效、更有见解的医疗协助。但模型本身的决策则需要能够被医师或其他从业人员所理解。因此医疗器材制造商应该加强可解释度以及专案的透明度。并且让临床评估当作是模型、医疗器械开发的过程之一,在上市之後也持续监督资料与使用者回馈。
Oravizio案例概述
Oravizio是一种医疗设备软件服务,是一间芬兰公司,可提供与髋关节(全髋关节置换术,THA)和膝关节(全膝关节置换术,TKA)置换手术相关的患者级别风险的讯息。尽管 THA 和 TKA 是成功率高的高效外科手术,但它们存在一定的不良事件风险。THA 和 TKA 手术後最常见的不良事件包括再次手术、假体关节感染和其他可能导致死亡的严重医学并发症。成功的手术可以显着提高患者的生活质量并降低社会成本。
在这个背景设定下,Oravizio有三个模型进行相关的预测:(1)手术後 1 年内有感染风险。(2)手术後 2 年内再次手术的风险。(3)手术後 2 年内有死亡风险。透过这三个模型,患者可以更好的理解手术风险和预期结果。
在第一个版本当中资料包括30,000 多笔患者记录。然而在这些资料当中,还需要合并、判断是否失效等等。光是第一个阶段就需花非常大的力气来整理这些资料到资料湖(data lake)当中。
在特徵的挑选上,资料包含从2008年开始收集的750 多个操作前变量。例如:一般客户背景(年龄、性别、BMI)、药物、实验室值、诊断、患者报告和衍生变量。在这部分则需要结合医师的专业知识,以及过去的研究文献和计算方法,来挑选适当的特徵变量。这些资料当中,2008-2015年的资料用於训练,2016-2018年的资料用於测试。
使用的挑选方式:LASSO, Ridge regression, 以及Elastic net。而建置模型的部分则使用了:Logistic regression, Decision tree-based methods (Random forest)., Gradient boosting methods (XGBoost), Weibull/Cox survival mode。整个开发流程也获得 ISO 13,485、 IEC 62304、ISO 14971 和 IEC 62366-1的合格认证。
关於软件开发与合规审核的合作流程可以参考这份流程图:
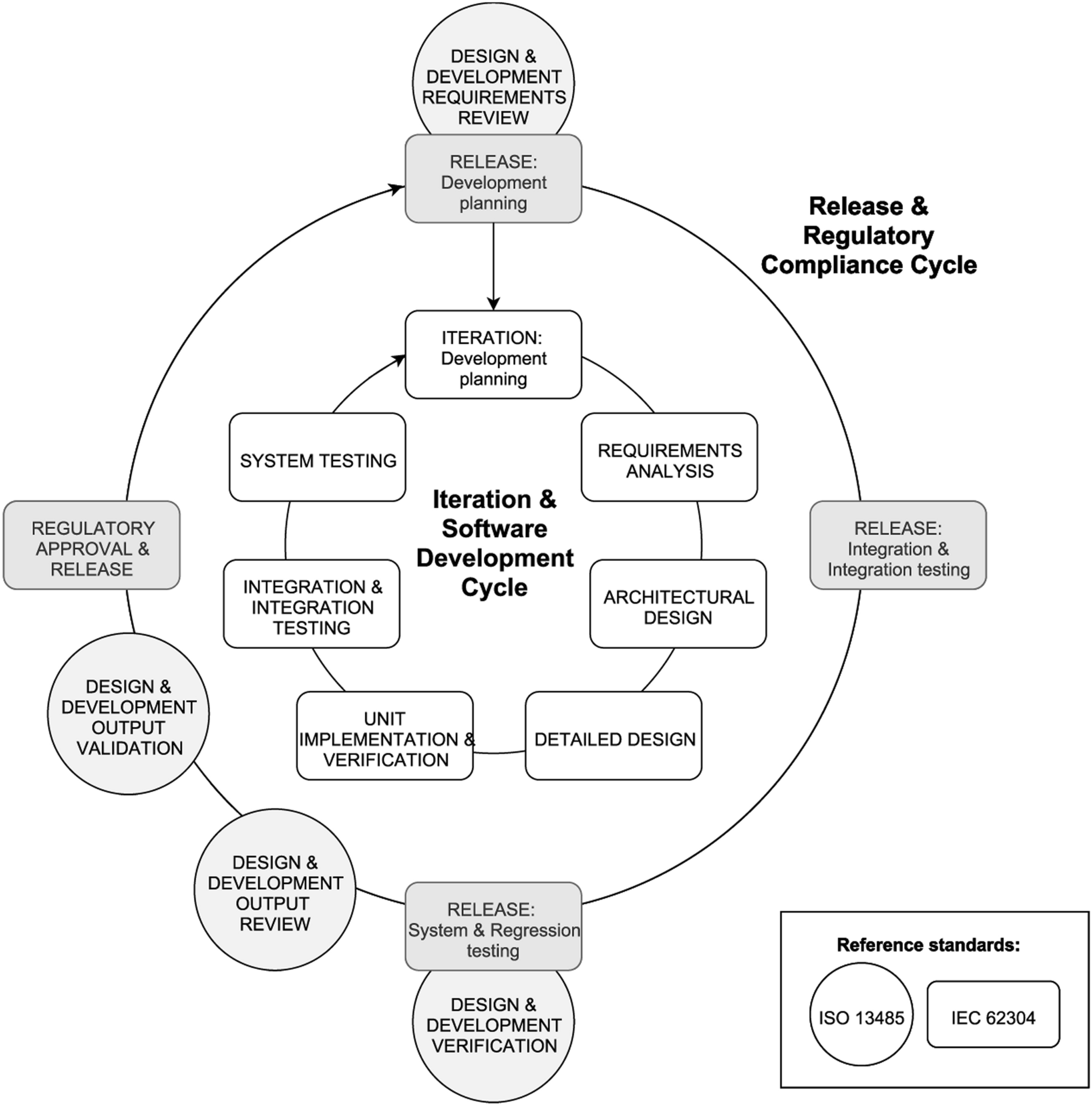
*图片来源:Towards Regulatory-Compliant MLOps: Oravizio’s Journey
专案的局限性
理想与现实总是有一些差距,然而在专案的实作当中,跟理论上的差距,可以整理成以下三点:
(1)与技术实施无太大关连,主要与组织设置和资料所有权有关。只有少数经过挑选和认可的资料科学家才可以拜访医院的计算环境。该环境也是受到严格限制与隔离的,而其他的开发人员则在外部工作,之後才串在一起的。在开发过程有些部分为手动处理:资料整合、预处理、新增资料湖、变量选择、ML 方法选择、模型训练和验证等步骤都是手动完成的。之後内容固定才有一些自动化脚本在本地跑,但仍然称不上符合CI/CD。以及上线之後,要去哪里收集的资料才能把新的资料收集、整理到可以重新训练的资料集。因为病患的资料并不都在Oravizio系统上。
(2)研究相关的有效性。对个案例研究其中一个明显的考量包含,整个流程当中,经验和专业知识的依赖程度多大,可以怎麽样被量化跟验证。相关组织在确保实施和相关流程的合规性方面投入了大量精力。如何让工程团队、资料团队大家都能够理解,在专案里面的指标以及降低可能在沟通上的误解。
(3)这个服务是否能够被广泛的使用,可能会质疑案例研究设置是否具有典型性,因为该手术是与一家医院和一家私营公司合作进行的。因此也需要跟外部证明,资料的采样能否同样被其他更广大的使用者族群采用。
案例结论
总结一下该专案的学习点:
(1)反覆试验、迭代:研究总是存在一定程度的不确定性,结果通常是通过反复试验来实现的。例如,使用 45,000 笔患者资料进行第二次迭代,重新训练後在一定程度上提高了模型的性能。
(2)及早加入监管策略:Oravizio 开发存在一些特殊的挑战是与该产业规范有关。在开发医疗器械产品时,必须一开始就清楚地了解适用的监管要求并相应地确定监管策略。
(3)自动化是可实现的:根据Oravizio的案例,MLOps 自动化目标是可以实现的。自动化持续训练管道设计,必须包括在第一次开发迭代中不存在的特定新步骤。一旦持续训练管道自动运行,少数的手动更新是唯一需要资料工程师和资料科学家参与的流程步骤。
(4)开发交接:刚刚讲到开发环境的交接,一旦模型被打包并生成一份验证报告,这些工件就可以从受限的环境当中,交付给另一个开发团队。整个开发流程也会更顺畅。而有pipeline的导入之後,开发团队也可以透过自动化设置,在不同的临床环境,例如医院或者相关医疗环境可以进行相关的开发跟研究。
结论
希望者两篇的案例讨论,可以让大家更认识医疗产业的用户案例。
Reference
[1]. MLOps in Healthcare | Major Use cases of MLOps in Healthcare
[2]. Machine Learning Trends to Watch Out in 2020 and 2021
>>: Day 3 [Python ML] 选择建模用的资料(DecisionTree)
日月千禧酒店 Soluna - All Day Dining 飨乐全日餐厅 - 午餐 Buffet at Millennium Hotel Taichung
我还是对日月千禧恢复供应「龙虾吃到饱」充满着期待... 第一次走进日月千禧,已经是好几年前的事情了,...
Day2 专案成立,来谈谈花钱的艺术
再来,谈到专案终於成案,老板放行以後,当然是很想好好大展身手。但是各路英雄好汉啊,有一个天敌,叫做一...
30天学会 Python: Day 15-用文字才好懂
档案类型 电脑中的档案可以分成纯文字档案和二进位档案两种: 纯文字档案: 虽然纯文字档案也是由二进位...
大共享时代系列_025_迷你仓(共享仓储)
仓库被堆放了哪些遗忘的记忆呢? 哪些人在使用迷你仓呢? 对於地狭人绸的城市来说,这样的存放空间是必要...
LeetCode 双刀流:144. Binary Tree Preorder Traversal
144. Binary Tree Preorder Traversal 今天挑选的是一题「二元树(...