Day 15 - 说明 YOLO 相关设定
Day 15 - 说明 YOLO 相关设定
先前在 介绍影像辨识的处理流程 - Day 10 有提到,整个影像辨识的流程如下:
- 取得数据集。
- 将影片转换成图片,并调成 YOLO 可以处理的大小。
- 资料增量。
- 影像分割与标注。
- 安装合适的影像辨识模型。
- 分成训练、验证与测试数据集
- 分析测试结果
- 进行优化
- 布署到後端服务器
我们已经完成前 5 项工作,现在要进行的是调整影像辨识模型的参数,这些参数的功能主要分成
- 针对数据集:需要设定的是训练集与验证集的文件夹、要辨识的鱼类有多少种、每种鱼类的名称、训练後的模型的文件夹等等。
- 针对影像辨识模型:这是针对辨识模型的参数设定,这个内容很多,而且需要对於深度学习,以及 YOLO 模型有一定程度的了解,才会比较容易设定。
在进行 YOLOV3 影像辨识训练前需要准备的有
- 安装 YOLOV3。
- 下载 YOLOV3 权重档 darknet53.conv.74。
- 准备影像数据集,包含影像跟标签文件。
- 数据集设定档。
- 影像辨识模型设定档。
下图显示在 AWS EC2 上的文件夹配置,最上面一层的 fishRecognition 是 python 的虚拟环境,而在这个虚拟环境中包含了一个 Django 专案 (./fishsite),还有它的应用 (./fishsite/fishsite),此外还有先前安装的 YOLOV3 系统,而为了让我们的影像辨识系统具体一点,我们另外建立了一个文件夹 FishRecognition ,在这个文件夹里进行影像辨识的工作。
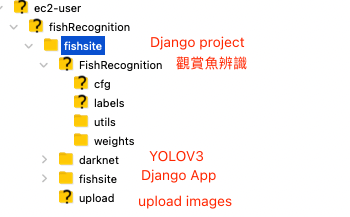
图 1、AWS EC2 的文件夹配置
以下是 FishRecognition 文件夹的结构,darknet53.conv.74 是 YOLOV3 权重档,在终端集中透过以下指令就可以下载,统一摆在 weights 这个文架夹中, labels 这个文件夹用来存放影像数据集,包含影像跟标签文件,这样一来前三项工作就完成了。
wget https://pjreddie.com/media/files/darknet53.conv.74
├── cfg
│ ├── obj.data
│ ├── obj.names
│ ├── test.txt
│ ├── train.txt
│ └── yolov3.cfg
├── labels
│ ├── 00-frame-608x608-0001.jpg
│ ├── 00-frame-608x608-0001.txt
...
│ ├── 02-frame-608x608-0093.jpg
│ └── 02-frame-608x608-0093.txt
├── utils
│ └── generatetrain.py
└── weights
└── darknet53.conv.74
数据集设定档
obj.data 是主要的数据集设定档,内容如下:
obj.data
classes = 3
train = cfg/train.txt
valid = cfg/test.txt
names = cfg/obj.names
backup = weights/backup
参数说明:
- classes:辨识的种类数量
- train:训练数据集
- valid:验证数据集
- names:辨识的种类名称
- backup:在训练过程为避免中途中断,所以每 100 次叠代,就会存一次权重档,可以重中断的地方继续训练。
train.txt 跟 test.txt 的内容其实就是 labels 文件夹内的档案,我们要从 labels 文件夹内的档案来产生 train.txt 跟 test.txt,於是我们写一个简单的程序,来自动生成这两个档案,放在 utils 文件夹中。
generatetrain.py
#!/usr/bin/env python3
import glob
import os
from os import listdir, getcwd
import random
import numpy as np
# 影像数据集的文件夹
input_path = './labels/'
# 生成训练跟验证文件的文件夹
cfg_path = './cfg/'
# 设定训练与验证的比例为 0.8, 0.2
train_ratio = 0.8
if os.path.isdir(input_path):
types = os.path.join(input_path,'*.jpg'), os.path.join(input_path,'*.jpeg'), os.path.join(input_path,'*.png')
files_grabbed = []
for files in types:
files_grabbed.extend(sorted(glob.iglob(files)))
elif os.path.isfile(input_path):
files_grabbed = [input_path]
else:
raise ValueError("File PATH is NOT Valid")
train_file = open('%s/%s.txt' % (cfg_path, 'train'), 'w')
test_file = open('%s/%s.txt' % (cfg_path, 'test'), 'w')
trainNum = int(len(files_grabbed) * train_ratio)
random.shuffle(files_grabbed)
train_file.write("\n".join(files_grabbed[:trainNum]))
test_file.write("\n".join(files_grabbed[trainNum:]))
下图是 cfg/test.txt 的内容

图 2、验证集文件的内容
以下是要辨识的观赏鱼名称,请特别注意顺序,以上图来说 02-frame-608x608-0038.jpg 就是 Cichlasoma var. Kilin Parrot (麒麟鹦鹉)观赏鱼,因为依照顺序 0, 1, 2 下来,对应到的就是编号 2 。可能有人会觉得 YOLOV3 是依照档名来得知编号吗?不是的,最上面的档案结构中就有显示,每个图档都会对应一个 YOLO 标签文件档,这个文件档中就有显示方块框中的物件编号
cfg/obj.names
Altolamprologus compressiceps
Chilotilapia rhoadesii
Cichlasoma var. Kilin Parrot
02-frame-608x608-0038.txt
2 0.264803 0.469572 0.180921 0.097039
2 0.098684 0.523849 0.177632 0.083882
2 0.513158 0.471217 0.177632 0.083882
2 0.754934 0.478618 0.167763 0.088816
2 0.833882 0.612664 0.134868 0.110197
2 0.735197 0.585526 0.072368 0.131579
2 0.571546 0.622533 0.205592 0.097039
2 0.591283 0.539474 0.156250 0.072368
2 0.386513 0.593750 0.085526 0.131579
2 0.173520 0.603618 0.077303 0.141447
2 0.235197 0.586349 0.062500 0.143092
2 0.069079 0.634046 0.128289 0.106908
影像辨识模型设定档
影像辨识模型设定档可以根据需要,可以使用 coco,yolo3-tiny,或是 yolov3 都可以,都有已经调适到最佳参数的设定档,下图就是安装 darknet 套件所附的相关设定档,我们选择 yolov3.cfg ,并修改部分设定以适合我们的配置。
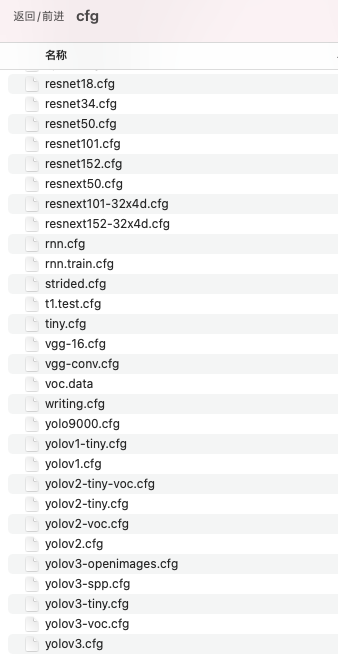
图 3、影像辨识模型设定档
确认图片大小,batch 参数是指每批次取几张图片进行训练,subdivisions 参数是指要将每批次拆成几组,这样的设定是每次处理 4 张图片,要考虑速度与避免 GPU 记忆体不够两者来权衡。
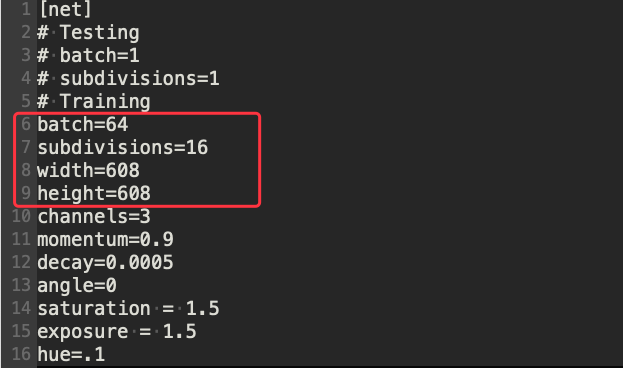
图 4、YOLO 影像辨识模型设定档 1
设定要判别的观赏鱼种类数量,因为我们只有提供 3 种,所以在 610 行的 classes 要改成 3 ,而上面卷积层的过滤器(603 行)也要相对应的改成 filters=24 这是因为公式如下:
(classes + 5)*3 = >(3+5)*3
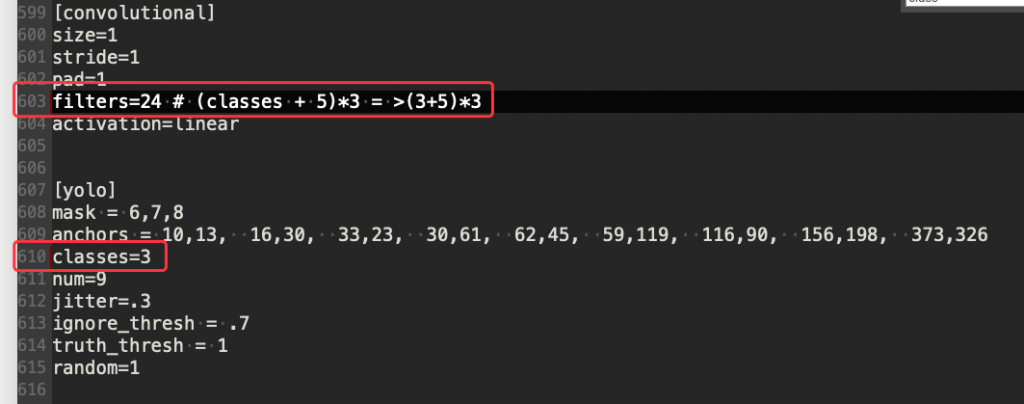
图 5、YOLO 影像辨识模型设定档 2
总共有四个地方要改,分别是行 689, 696, 776, 783,修改内容如上,所以就不一一截图。
设定完毕後就可以进行训练,输入下列指令进行训练,後面的 tee 指令是用来将训练时的输出结果储存在 trainRecord.txt 这个档案,好作为後来检查训练时的收敛程度。
../darknet/darknet detector train cfg/obj.data cfg/yolov3.cfg weights/darknet53.conv.74 | tee -a trainRecord.txt
下图是训练时的输出结果,我们需要根据这个结果来观察何时需要停止训练,1278 是叠代的次数,通常需要训练 6000-9000 次左右,avg. 前面的数字是平均损失,也就是所有机器学习或是深度学习用来判断是否贴近实际值的一个判断依据,越小表示越贴近实际值,越大表示还没有收敛,通常是 0.06-0.6 之间就表示已经训练的差不多了。後面表示一次叠代使用了多少训练时间以及图片。
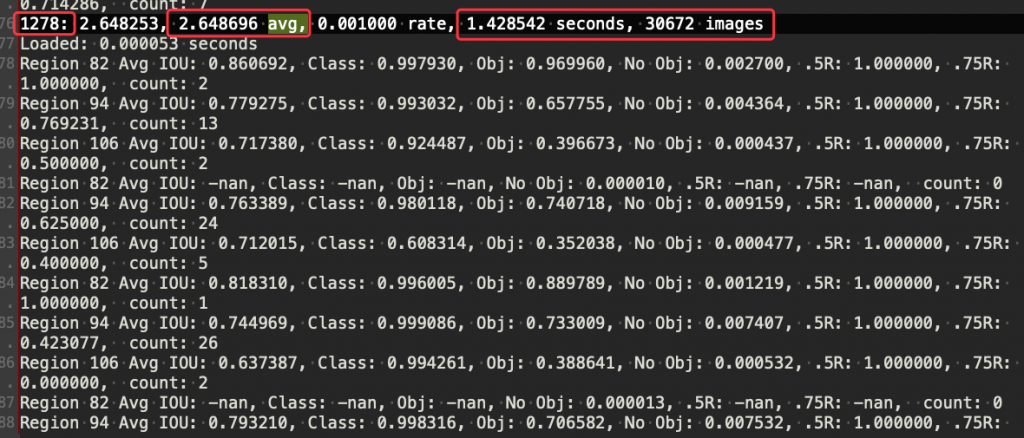
图 6、训练影像辨识模型的输出
参考资料
- 深度学习-物件侦测YOLOv1、YOLOv2和YOLOv3 cfg 档解读(一),https://chih-sheng-huang821.medium.com/深度学习-物件侦测yolov1-yolov2和yolov3-cfg-档解读-75793cd61a01
- 【采果辨识】建立自己的YOLO影像辨识模型 — 以柑橘为例, https://makerpro.cc/2019/08/build-your-yolo-recognition-model/
- Image markup for darknet machine learning, https://www.ccoderun.ca/darkmark/DataAugmentationColour.html
<<: 重新学习JavaScript#JavaScript能做甚麽?
[07] [Flask 快速上手笔记] 06. Cookie and Session
Cookies 要使用 cookies 可以使用 cookies 属性 设定 cookie 透过 s...
【Day29】谈谈软件工程师 - 8 大战略角色及 7 大能力对应的 26 项指标 (3) 案例分享
30 天 redesign 心目中的 LINE 的章节已经结束罗,有兴趣的话可以点此看看总回顾,现...
企业培训及顾问服务 Corporate Training & Consultancy
心理学专家主理企业培训 运用科学解决不同企业与组织问题,包括团队协作、客户关系,助你达成业绩目标。 ...
第一次的爬虫
老实说我就是一菜鸟小白,学习程序设计也不过一年多吧,而且也不是特别拿手,就是希望能透由这次的自主学习...
GitHub Wiki - 为你的 Repository 加入文件管理功能
今天我们来谈一点轻松的功能 - GitHub Wiki 身为开发人员,多多少少接触一些文件,可能是与...