DAY15 模型预测评估方法
我们的挑战终於进行一半啦~前面经过漫长的资料前处理、特徵工程、挑选模型进行训练後,我们把一个机器学习的模型建立出来了,接着我们要进行测试,也就是把测试档丢入模型里进行预测,那怎麽样的结果会符合我们的期待呢?我们又要以什麽方法去评估这个结果呢?将会在今天来做介绍,那就废话不多说,累狗 ~
一、回归问题评估方式-MSE、MAE
一般我们在回归问题上预测出来的结果会是数值,而预测值与实际值的差,就是"误差",回归问题用以评估的方法有以下几点:
MSE(均方误差)
所有误差的平方和取平均,越小代表越准确。
因为对误差取平方,较容易看出离群的预测值,此评估方式较在乎误差的大小。
MAE(绝对平均误差)
所有误差取绝对值後取平均,越小代表越准确。
求的是误差离实际值的真实距离,较难看出离群值。
程序码也非常简单,利用Sklearn套件就可以轻松实现。
#MSE
from sklearn.metrics import mean_squared_error
y_true = [3, -0.5, 2, 7] #真实值
y_pred = [2.5, 0.0, 2, 8] #预测值
mean_squared_error(y_true, y_pred)
#MAE
from sklearn.metrics import mean_absolute_error
y_true = [3, -0.5, 2, 7] #真实值
y_pred = [2.5, 0.0, 2, 8] #预测值
mean_absolute_error(y_true, y_pred)
二、分类问题评估方式-混淆矩阵(Confution Matrix)
最常被用来评估分类问题的指标就是混淆矩阵,他简单易懂,可解释力高,我们以好坏分类作为示范,混淆矩阵示意图如下:
(备注:矩阵会随预测的标签数增加,若标签为n个,矩阵大小就为n*n)
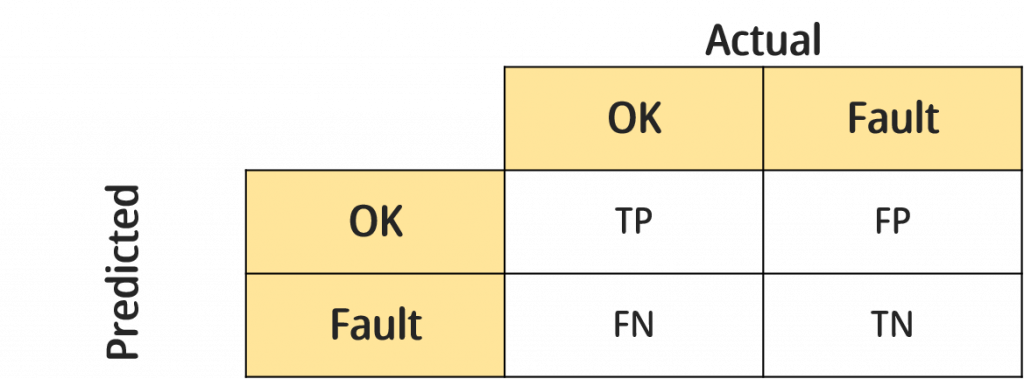
混淆矩阵TP、FP、FN、TN意义
▲True Positive(TP):实际状态为OK且预测状态也为OK。
▲False Positive(FP):实际状态为Fault但预测状态为OK。
▲False Negative(FN):实际状态为OK但预测状态为Fault。
▲True Negative(TN):实际状态为Fault且预测状态为Fault。
由上可知,TP与TN是最好的,因为都属於预测正确,而FP与FN都属於预测错误,但有些许的不同。以下我们用产品的品质管理来举例:
False Positive(FP)又称伪阳性,明明产品是坏掉的,我们却没有检验出来,反而说它是好的,这在统计学的假设检定中又称为型一错误,品管中我们称之为消费者风险(因为消费者会拿到坏的产品)。
False Negative(FN)又称伪阴性,产品是正常的,我们却说他是坏的,统计学的假设检定中称为型二错误,品管中称为生产者风险(因为把好的产品挑出来浪费掉了)。
在品管或生管我们会比较看重型一错误,毕竟你产品自己浪费了没关系,但如果送到消费者的手中就会影响产品的品质问题,这就是宁可错杀,不愿放过的概念,我们也可以用混淆矩阵来修正这几个指标。
延伸指标
Accuracy:最单纯的准确率,预测正确的比例。
计算方式:(TP+TN) / (TP+FP+TN+FN)
Precision:所有负样本中,成功预测出负样本的比例。
计算方式:TP / (TP+FP)
Recall:所有正样本当中,成功预测出正样本的比例。
计算方式:TP / (TP+FN)
F1-score:Recall以及Precision的调和公式
计算方式:2 * recall * precision / (recall+precision)
程序码范例
我们一样使用Sklearn的套件来实作
混淆矩阵
from sklearn.metrics import confusion_matrix
y_true = [0, 0, 1, 1, 0, 1] #真实值
y_pred = [0, 1, 0, 0, 0, 1] #预测值
confusion_matrix(y_true, y_pred)
其他指标
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
y_true = [0, 0, 1, 1, 0, 1] #真实值
y_pred = [0, 1, 0, 0, 0, 1] #预测值
# Accuracy
accuracy=accuracy_score(y_true,y_pred)
# Precision
precision=precision_score(y_true,y_pred)
# recall_score
recall=recall_score(y_true,y_pred)
# f1_score
f1_score=f1_score(y_true,y_pred)
三、结论
今天介绍了一些评估模型的指标,到了这个步骤也代表整个资料分析的流程都Run过一遍了,明天开始会完整的呈现一个在Aidea上的专案,从头带大家复习一遍利用机器学习来做资料分析的过程,如果前几个步骤的说明不够详细或是没有实作的感觉,也欢迎试着一起来挑战明天的专案喔~希望对大家有所帮助,再会啦!
>>: Day 13-制作购物车系统之安装及资料夹结构(二)
Gulp 压缩优化程序码(2) DAY89
上一篇有介绍压缩的一些套件了 不过有时候 我们在开发的时候 有时压缩 有时不压缩 那要怎麽解决 所以...
[机派X] Day 13 - 希望是最後一次,动手组装无人机罗
引言 今天是机派X系列文章的第十三天。 昨天终於介绍完无人机上的重要部件,从今天开始会动手组装无人机...
【Day10】Flutter环境设定 ( windows )
在拖延症的影响下,周日原本打算多备点稿的我又变成只有当日更新。 可能以後要强制自己每天多写一篇比较实...
学习Python纪录Day27 - Regular Expression正规表达式
正规表达式(Regular Expression) 一个范本的字串,在范本字串的每一个字元都有特殊意...
[DAY 02] Google Apps Script
要操控google 的档案如google drive, google sheet, ...等 你除了...