AI ninja project [day 15] 文字处理--BERT分类
参考页面:
https://www.tensorflow.org/text/tutorials/classify_text_with_bert?hl=zh_tw
以及colab:
https://www.tensorflow.org/tutorials/images/segmentation?hl=zh_tw
首先,建议使用colab 开启GPU的环境来运行,
本地端在只有CPU的情况运行,非常缓慢。
资料集使用的是IMDB影评的电影评论分成正向的评论及负面的评论,
未来希望能以未知的评论来预测,该评论是正面的还是负面的。
在使用tf.keras.preprocessing.text_dataset_from_directory(),请记得要把与训练集与测试集档案、资料夹等不相关的资讯移除,避免训练错误。
可以发现资料集有train、test两个资料夹,来区分训练集与测试集,
个别又有pos、neg两个类别,放置正向评论以及负向评论。
由於会对文字输入资料进行处理,所以安装tensorflow-text这个套件:

相对於过去我们只使用adam优化器,
这次我们想使用adamw优化器,所以安装套件,如果改回使用adam也能正常使用:
引入套件:
下载资料集,去除不相关的unsup资料夹:
切分训练、验证、测试集(使用缓存来增加训练速度):

後面我们会用tf hub套件来载入前处理层(tfhub_handle_preprocess )及BERT模型(tfhub_handle_encoder),
这里先设定要载入的url:
tfhub_handle_encoder = 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1'
tfhub_handle_preprocess = 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3'
如果想要使用中文的模型:
tfhub_handle_encoder = "https://hub.tensorflow.google.cn/tensorflow/bert_zh_L-12_H-768_A-12/4"
中文前处理:
import tensorflow_hub as hub
import tensorflow_text as text
tfhub_handle_preprocess = "https://hub.tensorflow.google.cn/tensorflow/bert_zh_preprocess/3"
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess)
text_test = ['我来自长庚大学']
text_preprocessed = bert_preprocess_model(text_test)
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')

可以看到前处理层有三个输出input_words_id, input_mask and input_type_ids以及他们的格式。
如果有更中意的BERT模型或是前处理层也可以从tf hub页面搜寻BERT来寻找。
BERT模型输出格式查看(还没训练,所以数值没有意义):
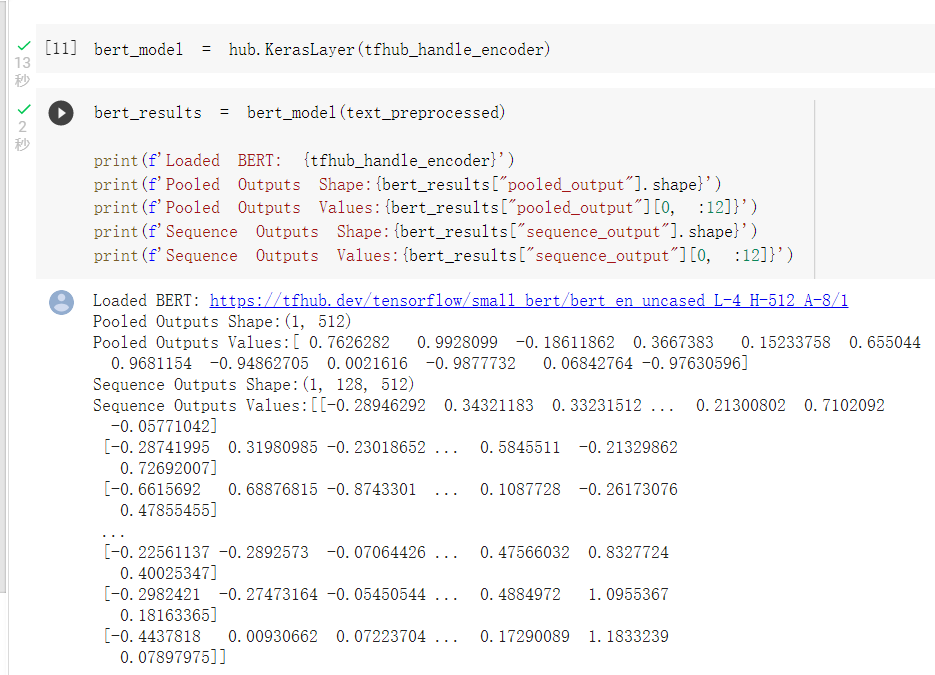
建立model:

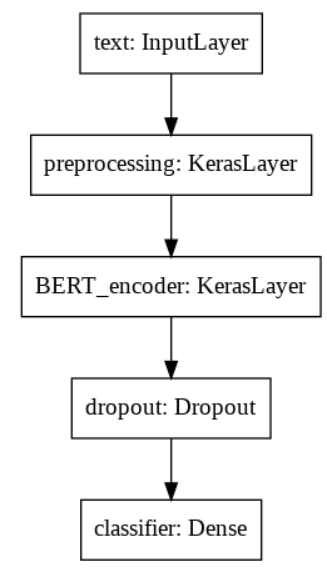
模型结构:
损失函数,由於类别只有两类所以使用tf.keras.losses.BinaryCrossentropy(from_logits=True),而不是使用之前多个类别的losses.SparseCategoricalCrossentropy(from_logits=False):

设定adamw优化器:

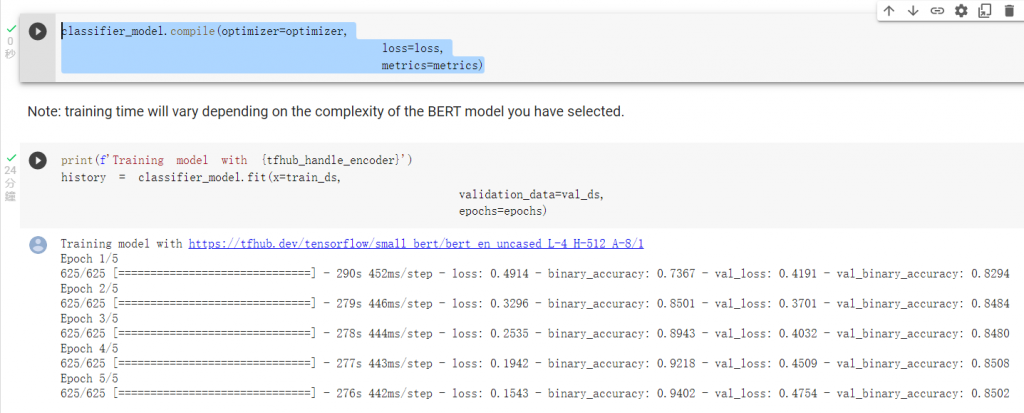
compile以及训练:
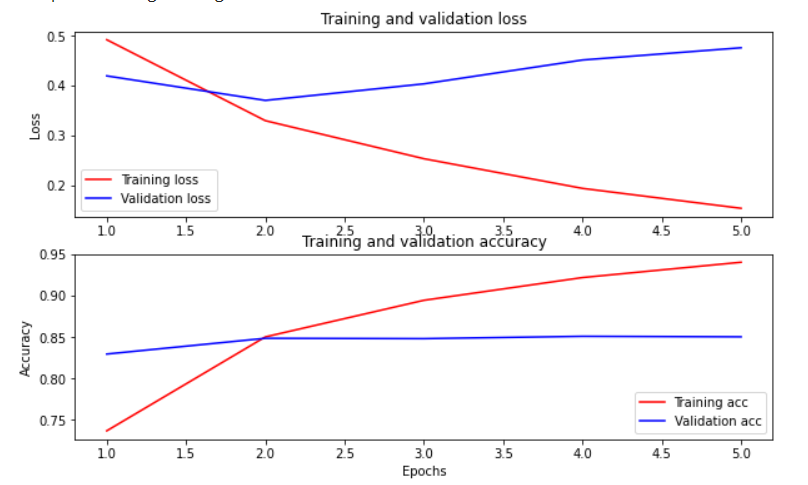
那可以以损失函数及准确度作图:
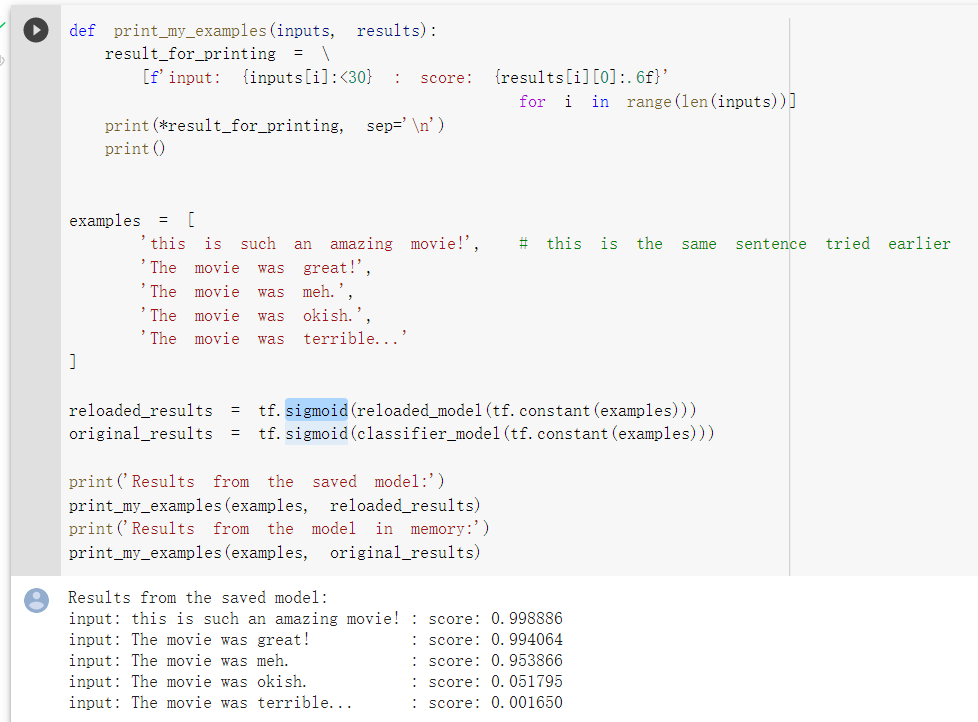
可以将模型进行保存及载入:

未来将文字进行预测:
[FGL] Error: Invalid hello message
出现频率:极少数客户 (但是若有,该主机就会常常出现此讯息) 成因:目前未能完全确认原始成因,但是...
Reactive programming
在上一篇中我们完成了 StickyNote 的 UI 跟 Model 的部分,後面的章节将有很大的一...
Day07 Kibana - Query DSL 语法结构
上一篇我们已经学会了使用kibana来查询Elasticsearch资料,但有时候这种简单预设的查询...
110/16 - 整合Android 6到Android 11
都把权限写完了,该来做个小整理,这次我们整合Android 6到Android 11,没有Andro...
Day10 - 除噪模型
在 Day01 的时候我们有提到过资料可能会有杂讯、噪音,因此所使用的模型架构可以分为两个阶段:除噪...