[自然语言处理基础] Regular Expression (II): 文本清理
前言
今天我们将继续介绍正则表达式,这次的任务围绕在自然语言处理中流程的文本清理(text cleaning)。我们或许都曾听过Garbage in, garbage out这谚语:错误、无意义的数据会诱导电脑做出错误的决策,其後果往往比没有数据而不作为更具有毁灭性。在大数据时代,我们不再比照过去手刻有限的规则来建构一套专家系统(expert system),而是仰赖资料的特性,让电脑学习其规则後做出决策。正因为如此,资料是某具有代表性(洁净度)就成了至关重要的议题。

Garbage In, Garbage Out
图片来源:David Dibert Photos
用正则表达式来清理资料
在序章我们见识到语料库中含有HTML标签,另外如藉由网路抓取(web scraping)而得到的原始文字资料也经常夹杂着大量无意义的字符:
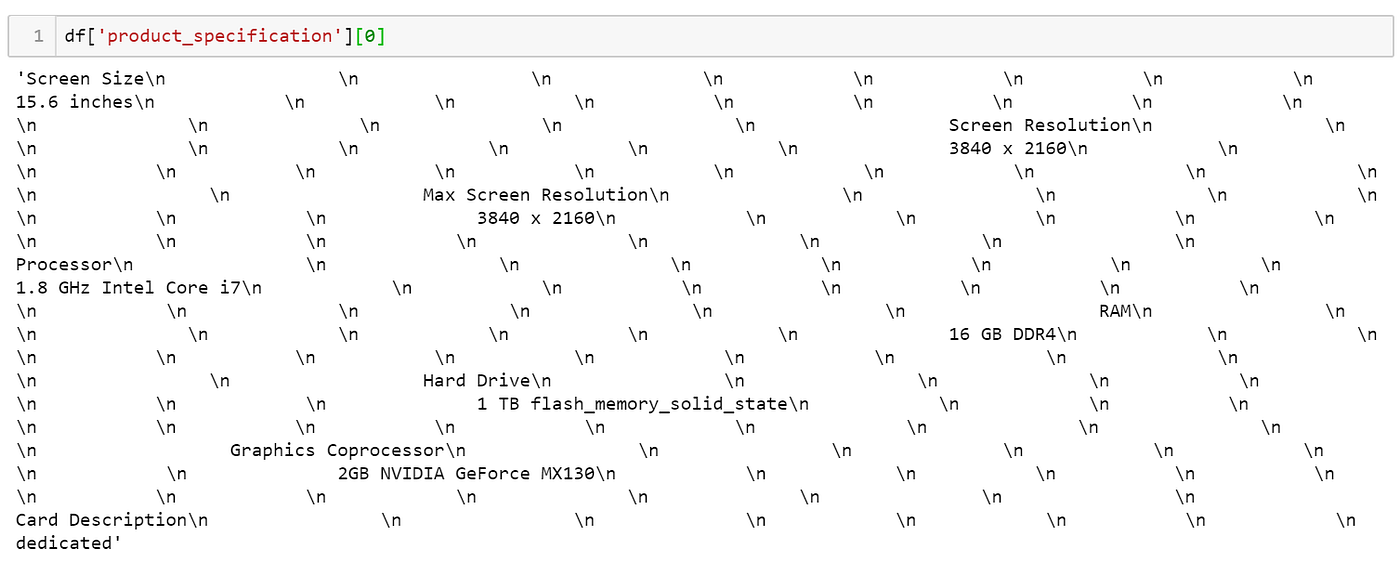
以下是常见的无意义字符分类:
- 标点符号:如 , . ! ' "
- 特殊字符:如Unicode字元 @ & # &
- 数字:如标示引述文献编号 [1]
- 空白:出现在行首、行尾及行间
- HTML标签:如 <html> 、 </body> 、 <img src="http://www.TheSiteDoesNotExist/images/my-puppies-01.jpg" alt="my puppies" />
就让我们来看看如何清理以下HTML代码:

为了运用正则表达式来制造pattern,我们先引入模组 re 。这时候我们使用 re.sub() 这个函式,并且传递三个必要引数(required arguments):
- pattern: 正则表达式,在这里我们可以设计为 r"<.*?>"
- replacement_text: 符合pattern的字串将被更换为之,在这里直接换成空字串 ''
- input: 待比对之字串
import re
raw_text = """
<html>
<head>
<title>My Garden - Tomatoes</title>
</head>
<body>
<h1>Garden Tomatoes</h1>
<p>I decided to plant some tomatoes this spring. They're really taking off and I hope to have lots of tomatoes to give to all my friends and family this summer!</p>
<p>Here are a few things I like about tomatoes:</p>
<ol>
<li>They taste great.</li>
<li>They're good for me.</li>
<li>They're easy to grow!</li>
</ol>
<p>Here's a picture of my garden:</p>
<img src="http://www.mygardensite.com/images/my-garden-001.jpg" alt="a picture of my garden" />
<p>Here's a <a href="http://www.welovetomatoes.com">link</a> to check out more interesting things about tomatoes!</p>
</body>
</html>
"""
text_no_tags = re.sub(r"<.*?>", '', raw_text)
print(text_no_tags)
来看看执行结果:
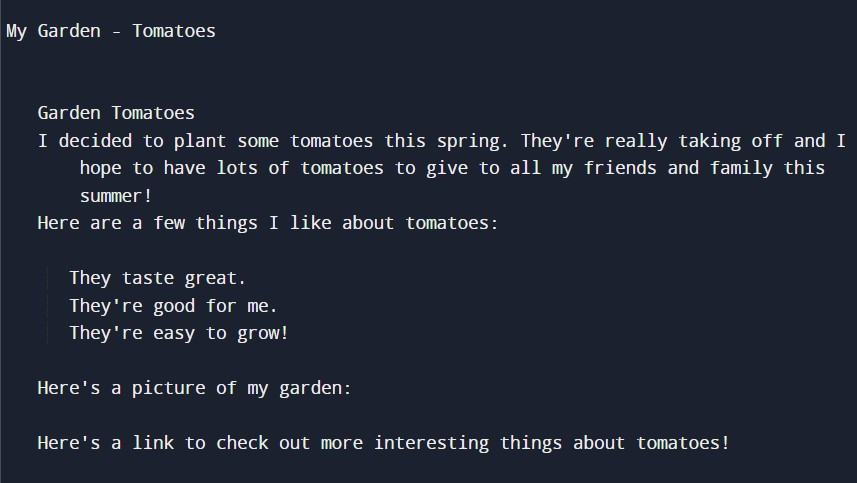
是不是将标签都清除了呢?接下来我们将字串中多余的空白一并去除!
这里我们使用了代表 whitspace、tab、换行的元字元(metacharacter) \s。由於无意义空格占了两个半格以上的空间,因此pattern可以设计为 \s{2,},程序码如下:
# to remove redundant whitespaces
text_no_whitespace = re.sub(r"\s{2,}", ' ', text_no_tags)
print(text_no_whitespace)
我们来检视一下清除空白的文件:

关於正则表达式如何进行资料清理就先介绍到这里,明天我们将介绍文本前处理的步骤,bis morgen!
阅读更多
- How to Clean Web Scraping Data Using Python BeautifulSoup
- Python re: Documentation
- Meta Characters in Regular Expressions
每个人都该学的30个Python技巧|技巧 11:回圈二部曲—while回圈(字幕、衬乐、练习)
昨天教完了第一种回圈,也就是for回圈,那今天当然就要讲第二种罗。while回圈的条件式通常都会是关...
【DAY 8】SharePoint 的应用五花八门,什麽最适合你?(上)
哈罗 ~ 大家好,希望昨天的文章有让大家更认识 SharePonit 这个工具到底可以用来做什麽。昨...
官方介绍的Bluetooth
https://developer.android.com/guide/topics/connect...
[Golang] Map
A map is an unordered collection of key-value pair...
容器化的安全原则(the security principles of containerization)
-容器技术架构 容器映像是由开发人员创建和注册的包,其中包含在容器中运行所需的所有文件,通常按层组...