[Day11] 文本/词表示方式(二)-BOW与TFIDF
一. BOW
BOW的全名为Bag-of-words,中文是'一袋文字',意思就是将词都丢进一个袋子里,所以又称'词袋'模型,假设有n个句子(或文章),总共有m个词,最後会形成nxm的矩阵,如下图:

每个句子会有m个元素,若有出现在这个句子的词,该词的位置的地方会加1,以上图为例,S1这个句子中出现1次W1,W2出现0次,W3出现3次,以此类推。
虽然这样的表示方式非常简便且快速,但缺点也是满多的:
- 无法取得前後文的关系
- 无法解决一词多义的问题
- 形成稀疏矩阵,0的元素过多
二. TF-IDF
全名为 Term Frequency - Inverted Document Frequency,其实就是由两个部分相乘。分别为'Term Frequency(词频)'与 'Inverted Document Frequency(逆词频)',通常表示文本/句子中的每个词的重要程度为何,也满多人利用BOW与TFIDF的方式来表示文本/句子。
-
词频(TF):
这个代表的意思就是词出现的频率,越多代表越重要,公式为: 一个词出现在某一文件的次数/该文件中所有单词的数量,如下图,该图为维基提供的图,i表示第i个词,j表示第j篇文章,k表示第j篇文章的所有词,举一个例子,若'优秀'在一篇文章文章出现20次,但这篇文章有5000个字,另一篇文章'优秀'出现10次,但这篇只有100个字,所以 tf('优秀', '文件一'): 为 1/250,tf('优秀', '文件二'): 为 1/10
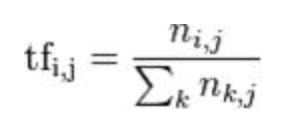
-
逆词频(IDF):
这个是用来制衡词频带来的一些负面影响,像是'的'这个词出现非常多次而且每篇文章都有,但这个词本身比不重要。用idf来抑制刚刚的情况,每个「词」在所有「文件」站的重要性为何,公式如下该图为维基提供的图,D表示所有的文件,分母表示这个词出现在几篇文章当中,这样像是'的',他的IDF都很低
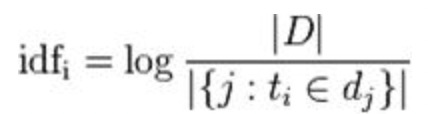
-
TF-IDF
将上述2者相乘即可~~
明天会利用python来实作TFIDF~
>>: Day11:插入排序法(Insertion Sort)
Day8 - pandas(3)DataFrame索引与loc、iloc
DataFrame索引: DataFrame在使用索引时,必须填入栏位名称 那我们如果只想选取某个r...
仓库进出货管理
电子化的库房管理,有助於进货、退货、取货等流程的简化,但在不同产业,繁简各有不同,通常在汽车、水电瓦...
Day02 线上金流再做什麽?
现在时代线上金流其实已经与各位的生活密不可分, 小吃、直播、实体商店、大小型电商等等族繁不及备载, ...
我们的基因体时代-AI, Data和生物资讯 Day07- 蛋白质结构和机器学习02:AlphaFold2 和 RoseTTAFold
上一篇我们的基因体时代-AI, Data和生物资讯 Day06-蛋白质结构和机器学习01我们继续分享...
Day28-让Xcode与模拟器并排显示在同画面
用文字说明可能有点模糊,我用图片举例说明,具体效果就像这张图片: 这样的效果在调试App时,有很大的...