AI ninja project [day 11] 图片分类(1)
我想先回来介绍一些深度学习框架好了,
非类神经的演算法也可以被归为AI,
但是神经网路的深度学习算是兵家必争之地。
假设去应徵要当一名AI软件工程师,应该不会pytorch,也要会tensorflow吧。
图片分类算是学深度学习时,
一定会碰到的基础功能。
下面先分享tensorflow官网基础教学的使用方法:
参考网站
https://www.tensorflow.org/tutorials/images/cnn?hl=zh_tw
安装
pip install tensorflow
引入模组
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
资料集为cifar10,总共有10个类别,有卡车、船、飞机、马、青蛙、狗、鹿、猫、鸟、汽车、飞机,
每个类别有6000张图片,在load_data的时候,就帮我们切分好了训练集及测试集,
而每一张图,为numpy array的格式
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
用list来对应答案与顺序
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
将像素 Normalize变成介於0-1的数值,以降低计算复杂度
train_images, test_images = train_images / 255.0, test_images / 255.0
建设模型之前,也可以先查看一下原始资料
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

再来是model的建立,采用的是官网使用的CNN:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
开始训练,设定为5个epoch:
history = model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
评估模型,查看损失函数与准确度:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(test_loss)
print(test_acc)
作图看,可以查看训练状况,以及有没有过拟合的情形:
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
可以发现在这样的设定之下,准确度不超过70,
因此我想使用autoML的套件autokeras来测试看看,
如果让程序以往格搜寻的方式自行搭建模型,是否能提升准确度。
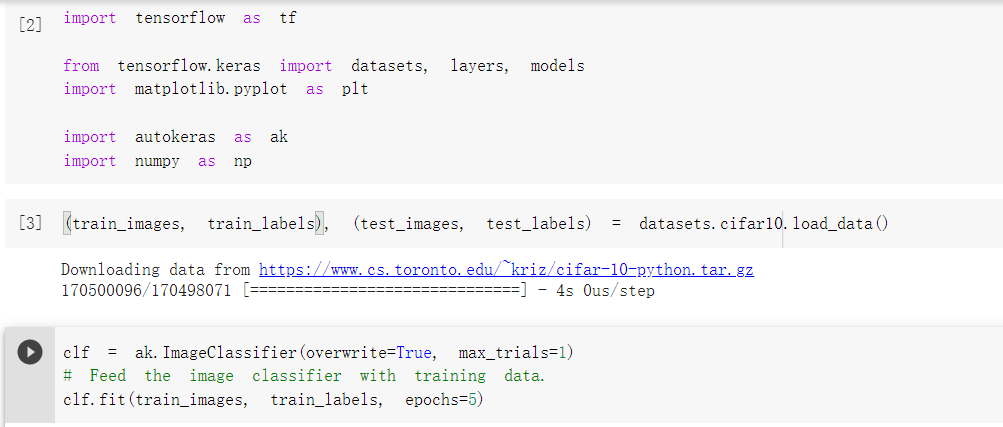
由於autokeras使用的是tensorflow 2.5,
所以我使用colab来执行程序(可以在工具区 键盘快速键设定喜好的快捷键):

使用依样的资料集,一样用5个epoch
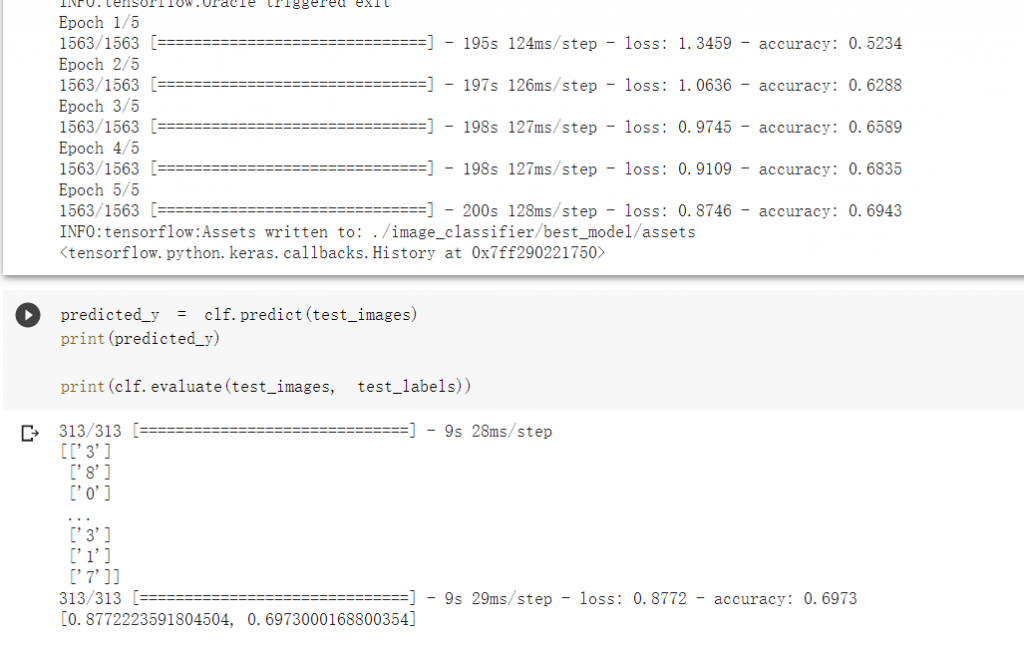
可以发现运行了很久,可惜准确度无法有效提升:
我还记得我毕业专题是用几百张 积雨云、层云、卷云来做分类,
是希望以云的形状来即时预测天气,准确度是还可以,是因为一开始挑选的图片差异就很大。
但是如果将模型放入树梅派,然後放入温室来拍摄天空就不知道效果如何(先不说准确度了,树梅派耐的了高温吗?)。
有机会的话,大家也可以搭建看看图片分类的模型,
看能不能有人能搭建出查看牛排几分熟的模型。
(不确定用物件辨识会不会更好做,但我从外观来看,主要是颜色的差异)
<<: Spring Framework X Kotlin Day 6 Unit Test
>>: .NET Core第11天_Controller定义_附加属性_资料接收方式_返回View方式
[DAY 4] _ 用Keil5直接编写暂存器操控MCU的GPIO口_(建Keil5环境)
我今天来讲下如何看手册操作暂存器好了,就以简单的GPIO口hi low就好,我手边刚有STM32F4...
[Lesson19] View Binding
build.gradle (app): //Android Studio 4.0 或更高版本 and...
Day23 | Livewire 实作 购物网站(二): 建立商品细节页面
有了商品列表,那应该要能点进去看商品的细节吧。所以今天就是来做点进去後的商品细节页! 今日目标:商品...
疫後数位未来想像
在未来的疫後世界当中,所有的事物都需要靠科技网路来维持,不论是工作还是娱乐都需要网路来帮助,也因此在...
30天零负担轻松学会制作APP介面及设计【DAY 11】
大家好,我是YIYI,今天我要利用MARVEL将前面三个介面做出连结。 制作介面连结 首先,先进入昨...