DAY09 资料前处理-异常值处理方法
昨天简单的介绍了缺失值的处理,今天来探讨异常值的处理方式,资料在蒐集的过程中除了有遗失的状况,当然也有记错的可能,这些值可能会影响模型的判断,造成准确度不佳,因此这些状况的处理也是资料预处理中的一个步骤。
一、异常值
一般来说,异常值就是偏离样本整体数据的值。包括离群值(Outlier)、噪音(Noise)...等。
噪音是一个观测值中出现的随机错误或是偏差;而离群值的发生原因有可能是真实资料所产生的,也有可能是噪音所造成的,因此对异常资料进行处理前,需要先辨别出到底哪些是真正的资料异常。
二、异常值发生原因
●人为失误:在记录数据时,可能多计或少计一个0而造成异常值。
●测量误差:测量仪器或工具所造成的异常。
●抽样错误:在抽样时不小心抽到不同族群的资料而造成的异常。
●自然异常值:异常值的发生非人为错误,而是数据使然,这类的异常值就需要单独挑出来做分析。
三、异常值判别方法
1. 常识判断:根据资料的特性去做判断
Ex: 健康检查的体温资料中出现不合常理的人类体温(69度、负值...)就可以判定为明显的异常。
2.基本统计方法:对资料进行描述性统计
利用资料的平均值、四分位距、标准差...等统计方法判断资料异常
Ex: 品质管理中的3σ 原则
3. 盒须图判别法
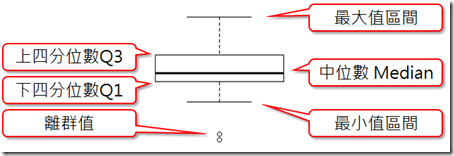
四、程序范例
我们一样使用铁达尼号资料集来做程序示范,资料集可以参考前一天的资料。
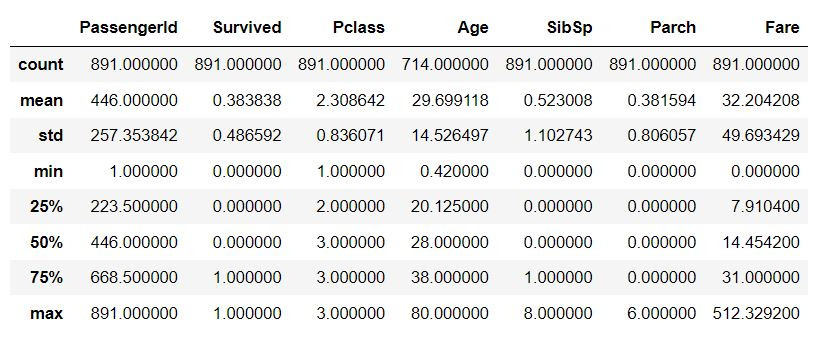
使用describe功能对资料进行叙述性统计
train_df.describe()
标准差原则的计算
import numpy as np
# 创建一个函数,计算在这个资料中, x:资料,times : 几倍标准差,找出在这样条件下的异常值。
def outliers_z_score(x,times):
mean_x = np.mean(x)
stdev_x = np.std(x)
z_scores = [(i - mean_x) / stdev_x for i in x]
return np.where(np.abs(z_scores) > times)
out_index=outliers_z_score(train_df['Age'],3)
print(train_df.loc[out_index[0],'Age']) #列出异常值以及index

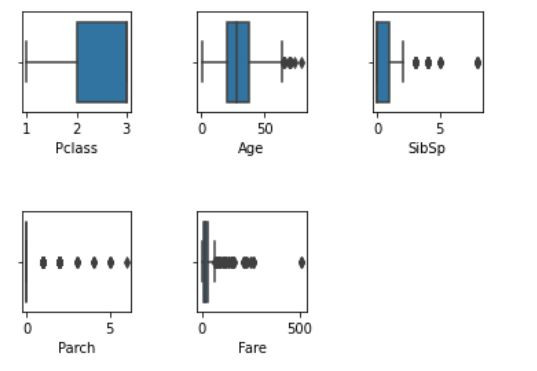
画出盒须图观察
import seaborn as sns
import matplotlib.pyplot as plt
features=["Pclass","Age","SibSp","Parch","Fare"] #要观察的特徵
fig , ax = plt.subplots()
fig.subplots_adjust(hspace=1, wspace=0.6)
location=1
for i in features:
plt.subplot(2, 3, location) #画布位置
sns.boxplot(data=train_df,x=i) #盒须图
location+=1
五、结论
异常值的出现,对於是否该删除或是保留,要根据应用性质与领域知识而定,举个例子来说,我们可以看到上面的范例中,"Fare"的异常值看似很多,但票价的范围可能本来就是这麽大,我们没有可辅助的资讯去判断这个异常值是否正常,但假如我们能够取得"Pclass"(舱等)个等级的票价范围,我们就可以用这个资讯当辅助去判断,假如一位客人买的是低等舱,但他的票价却是高等舱的票价,这笔资料可能就会有所问题,因此异常值判断并不是程序coding出来就好,更重要的是判断资料以及找到支持自己立场的佐证!
Day04:资料结构 - 阵列(Array)
闲话家常 今天来到了铁人赛的第四天了,我们继续来聊聊资料结构,秉持着一天弄懂一个观念,相信30天的铁...
Day 19 上传图片
在大部分的网站中,上传图片也是很重要的功能,今天我们就来实作。 (注:这是用 Blazor Serv...
Day 13 懒得想变数吗? RSpec 有提供你啦
该文章同步发布於:我的部落格 还记得我们使用 let 方法来实作一个物件来让我们可以快速使用! 但...
[Day15] 学 Reactstrap 就离 React 不远了 ~ 用 Tooltips 熟悉 useState
前言 对刚接触到 useState 的人来说, 应该要多点练习机会, 就跟学语言一样, 多用多练习就...
【Day 15】 为何要进行资安攻击的分析
大家早安~ 接下来就是到了我们实作二 - 资安攻击分析 on AWS,在那之前想先跟大家讨论 Q:『...