AI ninja project [day 9] 先验演算法
除了在机器学习与深度学习的演算法,
其实还有一些演算法,可以帮忙做资料整理,
或是进行推导,寻找关联性,
像是这篇介绍的Apriori Algorithm。
也有些演算法像是基因演算法,能用来解决困难的数学问题,
,持续优化寻找更佳的解来解方程序。
那这里使用mlxtend这个套件,进行安装:
pip install mlxtend
接着可以看官网的范例:
http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/apriori/
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
dataset = [['Milk', 'Onion', 'Nutmeg', 'Kidney Beans', 'Eggs', 'Yogurt'],
['Dill', 'Onion', 'Nutmeg', 'Kidney Beans', 'Eggs', 'Yogurt'],
['Milk', 'Apple', 'Kidney Beans', 'Eggs'],
['Milk', 'Unicorn', 'Corn', 'Kidney Beans', 'Yogurt'],
['Corn', 'Onion', 'Onion', 'Kidney Beans', 'Ice cream', 'Eggs']]
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
print(df)
dataset为顾客的购买资料,有客人可能买了五样商品,有人买了七样。

将资料格式使用TransactionEncoder转换成布林值的one_hot_encoder。
from mlxtend.frequent_patterns import apriori
result = apriori(df, use_colnames=True)
print(result)
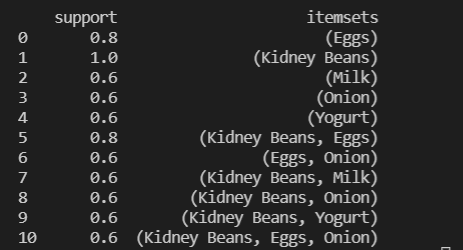
可以发现Eggs、 Kidney Beans,这两个商品的关联度是最大的,
可以考虑是否将两个商品排近一点或是一起买的话祭出优惠。
值得注意的是apriori()这个function能设定最低支持度(min_support)这个参数,都不设定的话,
预设值为0.5。调太高的话,门槛越严格,回传项目越少。
那我们也可以进一步将详细的关联规则,进一步印出。
from mlxtend.frequent_patterns import association_rules
return_association_rule = association_rules(result, metric="confidence", min_threshold=0.7)
print(return_association_rule)
>>: ASP.NET MVC 从入门到放弃 (Day4) -C#运算值介绍
Progressive Web App 推播通知: 网站推播通知用户端实作入门 (24)
什麽是网站推播通知 推播通知不管对 App 或是网站来说都是一种重新吸引用户来使用 App 的方法,...
透过数位逻辑电路学习 Bitwise 操作
本文目标 学习基础的数位逻辑概念 认识撰写系统软件常用的 Bitwise 技巧 位移操作 认识多工器...
Day 21 - canvas 玩拼图 P5.js
今天本来要带大家玩 用 canvas 完成拼图 参考的范例在这里 很可惜又是时间不足 先把目前完成的...
英文能力重要吗?
过去有份工作,在刚进入公司时,在公司内部用不到英文,但是随着组织异动,与外国客户以及跨国团队沟通。而...
Day 07 JavaScript/Rails API
阿修的说文解字 API 的全名是 Application Programming Interface...