[Day 6] 资料产品第三层 - 描述性模型
这边指的模型不只是最近很潮的机器学习或深度学习,而是广泛指透过资料建立用来代表现实的抽象概念(白话来说就是一堆数学)。模型并不是资料本身,但好的模型会能表现资料展现的特质。就像钢弹模型不是钢弹,但会充满真正钢弹的细节。

(图1: RX-78F00)
描述性模型
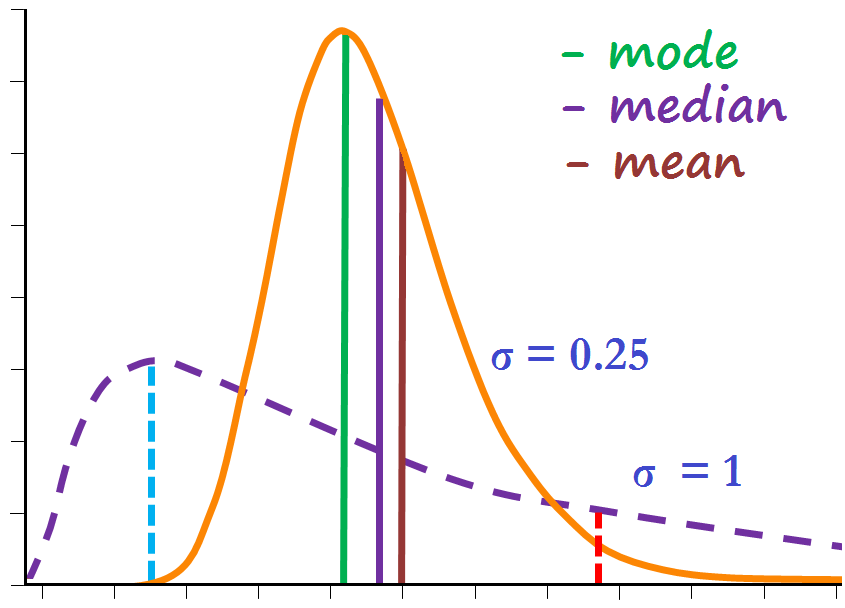
(来源:https://www.datavedas.com/descriptive-statistics/)
描述性模型重点在於用简单的方式来解释手上的资料。例如当你在自我介绍时,很容易就能讲出自己的身高体重,但如果要描述一个班级甚至一个城市的人的身高体重,就没办法用这种方式,因此需要一些描述性的模型来帮助我们补捉个轮廓,例如常听到的平均数、常态分配就属於这类。
资料类型
不同类型的资料可以用的描述方式不同,在做分析之前一定要先辨识资料的类型。
- 类别型资料(Nominal): 只能数个数,但是不能直接进行数值运算,像是颜色、品牌、性别。
- 等序资料(Ordinal): 像是等第(A、B、C)、喜欢程度(1-5 分),数值之间可以比大小但是没办法运算的资料。
- 等距资料(Interval): 数值型资料,没有绝对的零(例如温度)。
- 等比资料(Ratio): 也是数值型资料,但有绝对的零(例如速度、距离等)。
集中趋势
集中趋势指的是资料往哪集中,如果数列是 [1, 2, 2, 3, 4, 5, 6]
- 众数 - 相同资料最多的地方,也就是 2
- 中位数 - 资料由小大到排序後的中心点,也就是 3
- 平均数 - 资料的重心,数字加总後除以个数,等於 3.28
集中趋势用来描述资料很方便,但也会丧失许多精准度,最常见的例子就是「台湾平均每个人有 1.1 个睾丸」。因此在使用上也需要注重集中趋势的特性以及资料的脉络才能避免误用。
离散程度
离散趋势和集中相反,描述的是资料散乱的程度。常用的像是:
- 全距: 很单纯就是用最大值减去最小值,可以概括知道资料的状况。
- 标准差: 自己看了,有点难文字描述 https://zh.wikipedia.org/zh-tw/%E6%A8%99%E6%BA%96%E5%B7%AE, 由於是个标准化的计算方式,所以不同单位的资料都可以用标准差来衡量离散程度。
分布型态
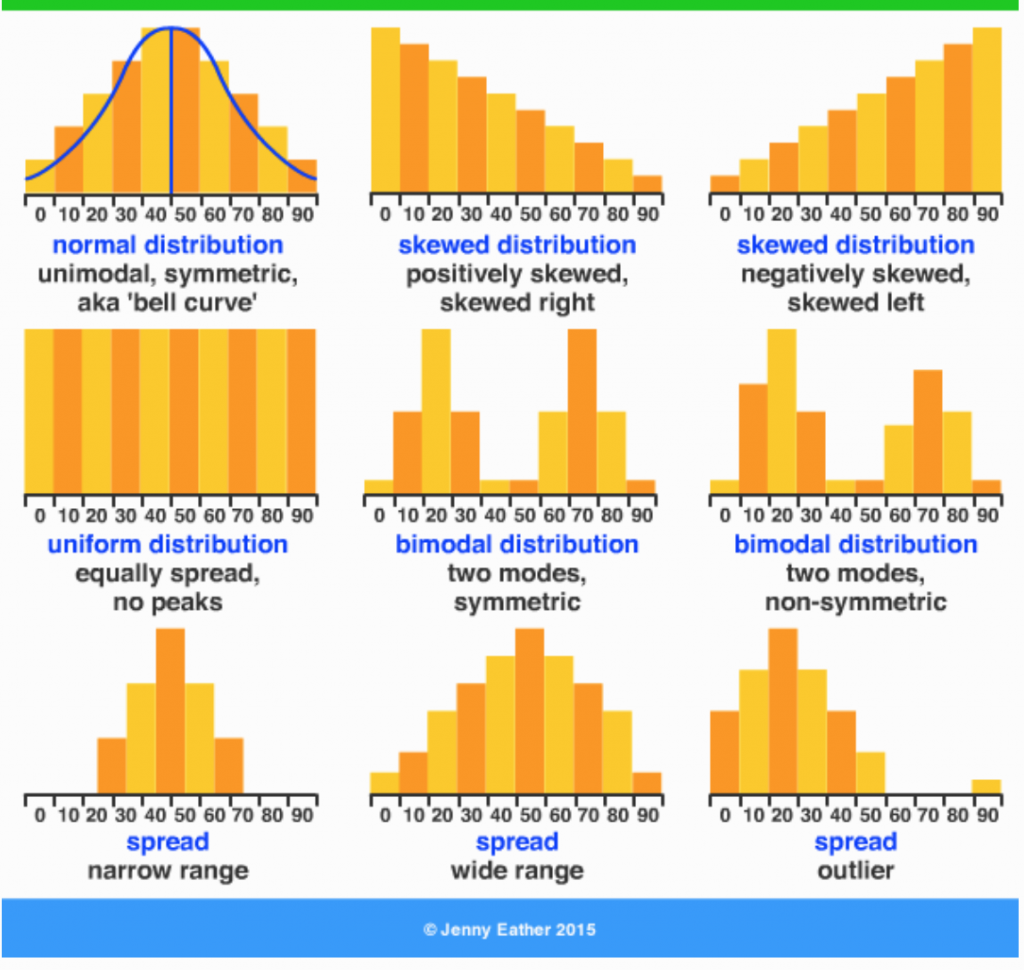
(https://jackrowansflightlogs.blogspot.com/2020/04/uniform-data-distribution.html)
通常资料实际上的长相不会是一两个数字能够完整描述的,像上图这些资料集中和离散程度可能都差不多,但是样貌天差地远。
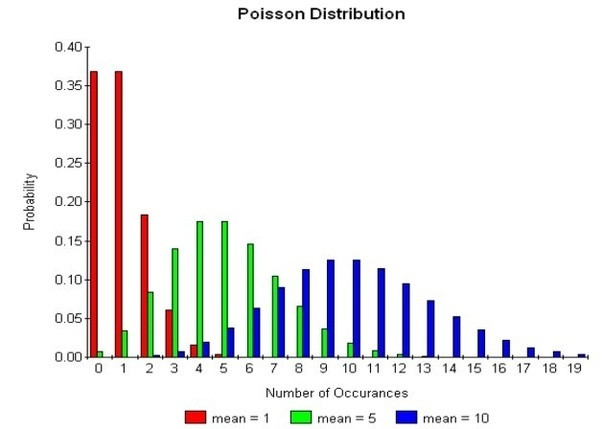
(https://www.quora.com/How-is-Poisson-distribution-the-limit-of-binomial-distribution)
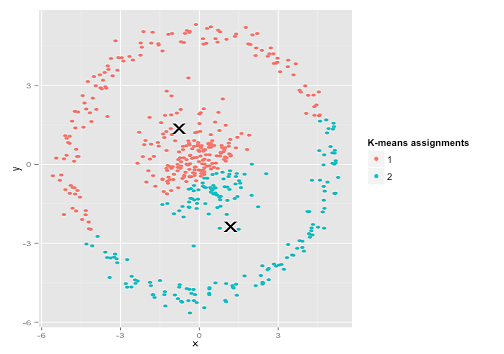
由於资料分布会有常见的模式,因此我们也会使用一些数学公式来描述资料分布状况(像上图的 Possion 分布)。而资料的分布型态也会直接影响可以用的分类模型,像是下图这种同心圆的资料分布就不适合使用 K-Means 演算法。
探索型资料分析 EDA(Exploratory Data Analysis)
一般来说,在正式进资料分析或建模前都会透过这样的探索型分析来了解资料的样貌。由於资料量通常很多,没有办法一个一个检查,因此会透过这篇介绍的描述性模型来将资料做摘要,方便分析人员可以更快了解资料的样貌、找出资料异常。这里分享一下我常用的起手式:
- 为每个栏位进行描述统计,了解每个栏位的集中与分散状况,抓出特别的 Outlier 和 Null 值。
- 为每个栏位画分布图,了解资料样貌。
- 将栏位画交叉散布图,了解两两资料之间的关联。
- 以时间为 X 轴了解每个资料在时间上的变化。
References
https://wiki.mbalib.com/zh-tw/%E6%A8%A1%E5%9E%8B
https://www.sciencedirect.com/topics/computer-science/descriptive-model
https://towardsdatascience.com/exploratory-data-analysis-eda-a-practical-guide-and-template-for-structured-data-abfbf3ee3bd9
Day 19 Docker Compose 操作指令
使用 docker compose 来串起一连串的 Container 服务前,这边先笔记下一些在过...
Day26,Kubecost 体验,算钱好难......
正文 kubectl create ns kubecost wget https://raw.git...
为了转生而点技能-Java难题纪录 (作业:染病接触之人员追踪链
前言: 本篇是参加学校开设的java资讯班的作业,由於对於笔者来说花蛮多时间的,所以想记录下来解题的...
[Day2] 资讯安全的攻击与威胁-社交工程
今天纪录资讯安全的攻击与威胁里的社交工程。 社交工程 社交工程是一种透过沟通、欺骗的手法,取得他人的...
[Day 3] 前後端技能这麽多,要选哪个呢?
本来打算一篇写完的,结果居然要分成三篇 XD 前端工具挑选 前端的部分可以搭配框架来建立 比较有名的...