Day 27 - 强化学习 Reinforcement Learning(1)
马可夫决策过程 Markov decision process MDP
-
在概率论和统计学中,马可夫决策过程(英语:Markov Decision Processes,缩写为MDPs)提供了一个数学架构模型,用於面对部份随机,部份可由决策者控制的状态下,如何进行决策,以俄罗斯数学家安德雷·马尔可夫的名字命名,是马尔科夫链的一种扩展。link
-
在经由动态规划与强化学习以解决最佳化问题的研究领域中,MDP是一个有用的工具。广泛应用於机器人学,自动化控制,经济学和制造业的一种工具。
-
MDP的一个重要观念:”未来只取决於当前” link
-
为什麽强化学习会跟MDP有关呢?我们先看什麽是State(状态)
-
因为我们的大脑一开始并不知道环境的状态是怎麽样,所以只能从以前所经历的observation,action,reward跟现在所得到的observation, reward来去当作现在的状态
-
那如果我们要去估计下一个状态(St+1)是怎麽样的,是不是就要把S1~St的所有状态给考虑进去,这样模型便会非常的大,这时候Markov假说就有用了,Markov说的:未来只取决於当前,所以我们可以假设 下一个状态只跟现在这个状态有关,有这个假设就可以把模型给缩小,不过这个假设也只是理想的状况下。
因此我们可以把强化学习想像成是MDP的一种模型,因为我们从现在的状态来知道未来的状态,未来知道了,相对的,我们要找到最好的动作也变得有可能了。所以RL就变成是解MDP的一种模型了。
-
强化学习 Video
强化学习(英语:Reinforcement learning,简称RL)是机器学习中的一个领域,强调如何基於环境而行动,以取得最大化的预期利益。 其灵感来源於心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
强化学习和标准的监督式学习之间的区别在於,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注於在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。
强化学习其实就是训练一个AI 可以通过每一次的错误来学习,就跟我们小时候学骑脚踏车一样,一开始学的时候会一直跌倒,然後经过几次的失败後,我们就可以上手也不会跌倒了。
应用
- Robot 学习:
- Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization
https://www.youtube.com/watch?v=hXxaepw0zAw
- Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization
- Game
- AlphaGo围棋
- Tetric (俄罗斯方块)
- 五子棋
- 对话系统:
- 有些已经把RL用在对话系统上,利用互动式学习,随着时间不断的提升对话系统
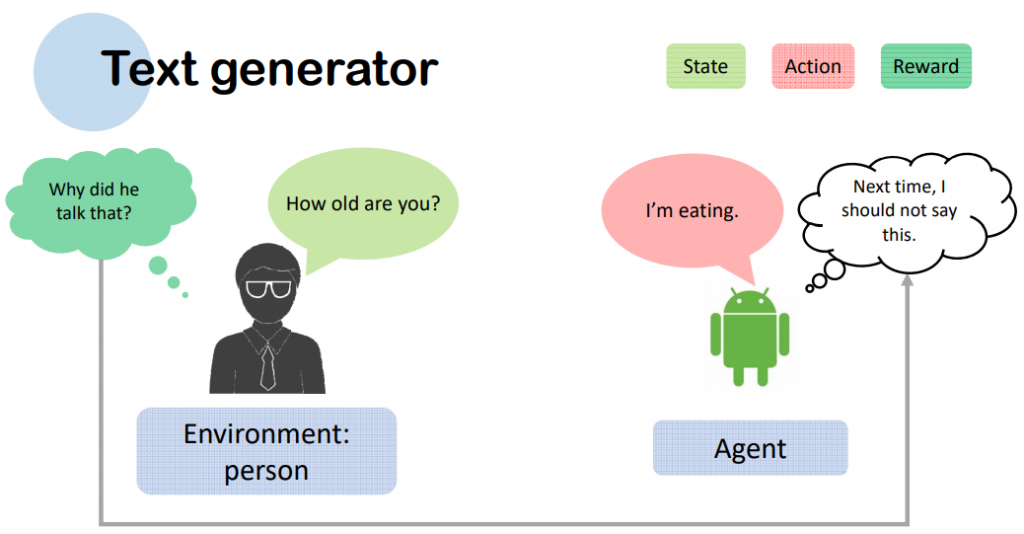
- 有些已经把RL用在对话系统上,利用互动式学习,随着时间不断的提升对话系统
- 医疗:
- 利用RL来寻找最佳的治疗方案
- Google auto ML:
- 使用RL来为计算机视觉和语言建模生成神经网路架构
- 自动驾驶
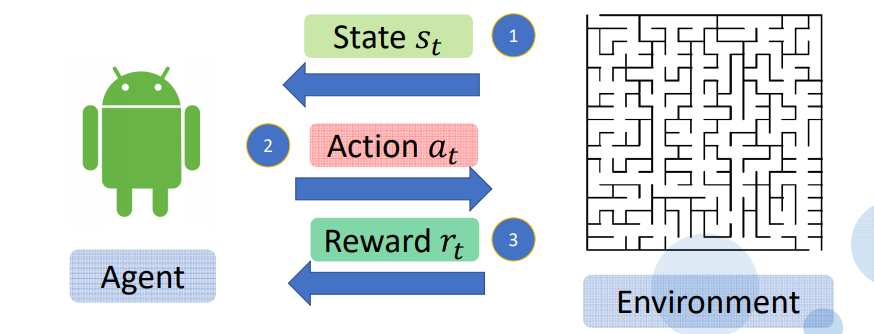
State / Action / Reward
例如走迷宫, Agent 尝试在迷宫, 训练Agent 取得最多的奖 total rewards
1.Agent 取得目前状态 State St 或 Obersavation
2.Agent 采取行动 Action At
3.Enviroment (环境) 反馈 Rewards rt
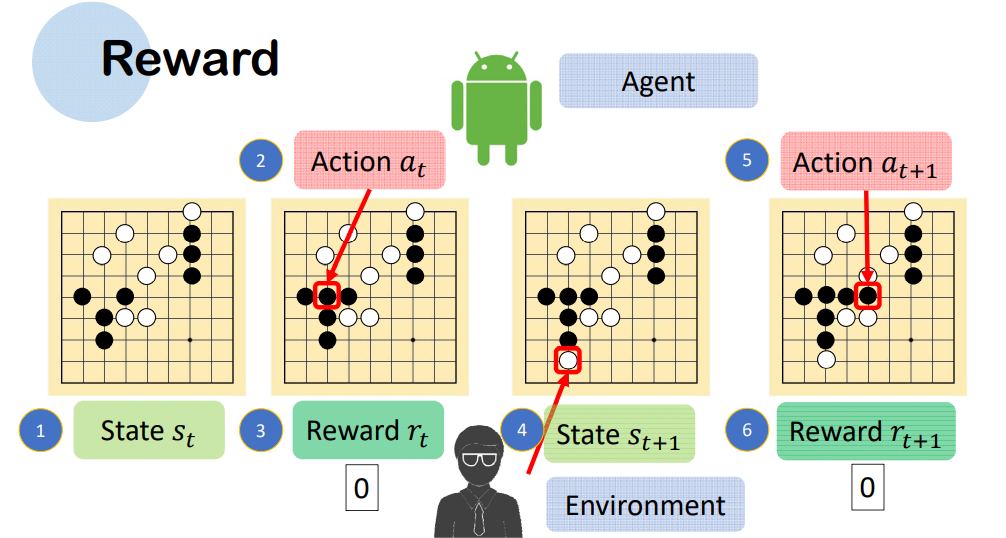
例如五子棋
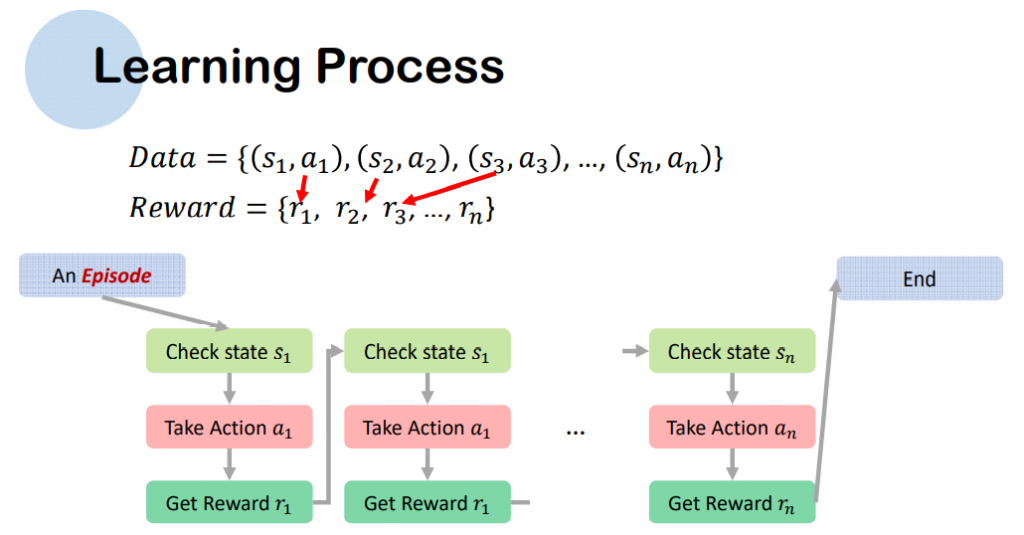
强化学习常用算法
- 蒙地卡罗方法 Monte-Carlo Learning
- 时差学习Temporal-Difference Learning
- SARSA (State–action–reward–state–action)
- Q-Learning
注:本文是搜寻数个网站及各种不同来源之结果,着重在学习,有些内容已难办别出处,我会尽可能列入出处,若有疏忽或出处不可考,请联络我, 我会列入, 尚请见谅。
<<: 【图解演算法教学】Bubble Sort 的大队接力赛
>>: iOS APP 开发 OC 第五天, OC 数据类型
Day 23-制作购物车之设计SideDrawer&Backdrawer
设计的部分就不多做分析,主要呈现实作成果。 以下内容有参考教学影片,底下有附网址。 (内容包括我的不...
第 58 天 - 理解 hardlink 跟 softlink
今天进度 : unix - What is the difference between a sym...
Day 03-不用写程序也可以建立简单的聊天机器人
前言 上一篇我们建立好了一个Messaging API的channel 那接下来我们就要开始写程序了...
网路架构检视 - 连线存取、防火墙
网路基础架构做完上一篇的分区与 IP 分配後,下一步就要开始针对每一个区域的性质调整各项防护措施,以...
Day18 vue.js新增文章
延续昨日 今天我们来新增专案 首先需要先新增一个Addproject.vue 新增path 以及修改...