Day 23 - 天眼CNN 的耳朵和嘴巴 - Transformer
RNN问题及解法
RNN 有字数限制, 最多到200字, 超过效果不好。The fall of RNN / LSTM
针对基於CNN和RNN的Seq2Seq模型(注)存在的不足,2017link 《Attention is all you need》这篇论文提出了一种完全基於Attention Mechanism(Self Attention)的Transformer架构:抛弃CNN和RNN,基於Attention来构造Encoder和Decoder ,搭建完全基於Attention的Seq2Seq模型。Attention机制详解
- Attention Mechanism: Take outputs of all steps into account.考虑所有步骤的输出。

当我们完成实作并训练出一个 Transformer 以後,除了可以英翻中以外,我们还能清楚地了解其是如何利用强大的注意力机制(Encoder-Decoder 模型 + 注意力机制)来做到精准且自然的翻译。浅谈神经机器翻译 & 用 Transformer 英翻中
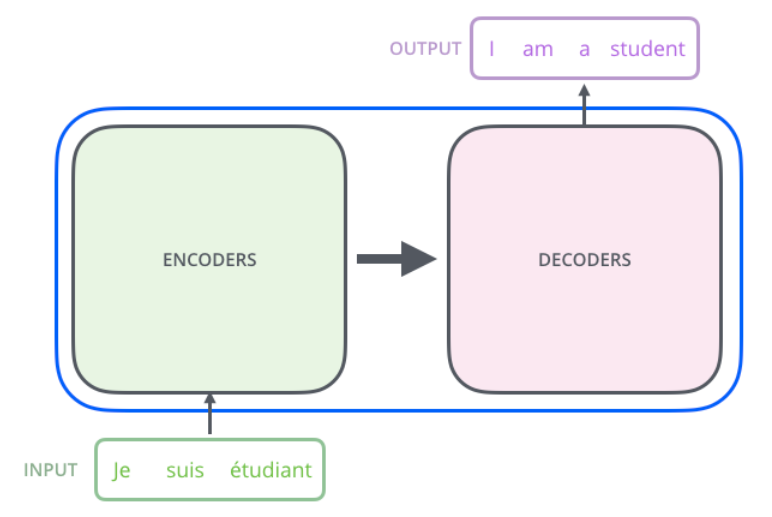
Encoder-Decoder:
-
根据不同的任务可以选择不同的编码器和解码器(可以是一个 RNN ,但通常是其变种 LSTM 或者 GRU )
-
具体实现 Encoder-Decoder 的时候,编码器和解码器都不是固定的,可选的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由组合且各自独立。比如说,你在编码时使用BiRNN,解码时使用RNN,或者在编码时使用RNN,解码时使用LSTM等等。
-
例如语言翻译,Encoder 把输入的句子做处理後所得到的隐状态向量交给 Decoder 来生成目标语言。link
-
你可以想像两个语义相同的法英句子虽然使用的语言、语顺不一样,但因为它们有相同的语义,Encoder 在将整个法文句子浓缩成一个嵌入空间(Embedding Space)中的向量後,Decoder 能利用隐含在该向量中的语义资讯来重新生成具有相同意涵的英文句子。
-
这样的模型就像是在模拟人类做翻译的两个主要过程:
- (Encoder)解译来源文字的文意
- (Decoder)重新编译该文意至目标语言
-
当然人类在做翻译时有更多步骤、也会考虑更多东西,但 Seq2Seq 模型的表现已经很不错了。
-
Transformer
- Encoder-Decoder 模型 + 注意力机制 link
基本款的 Seq2Seq 模型表现得不错,但其实有可以改善的地方。
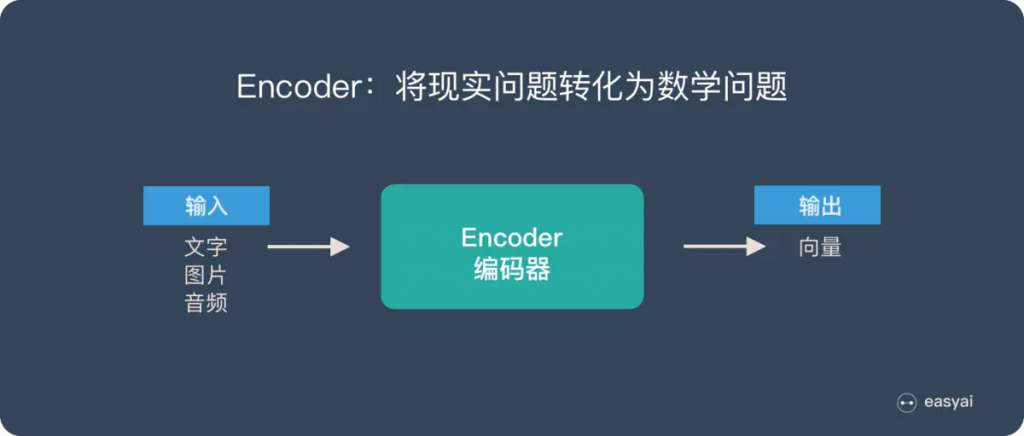
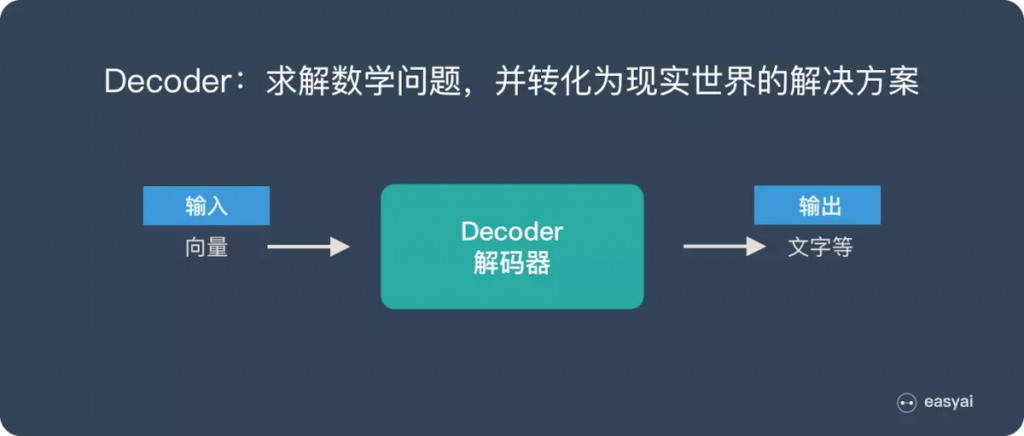
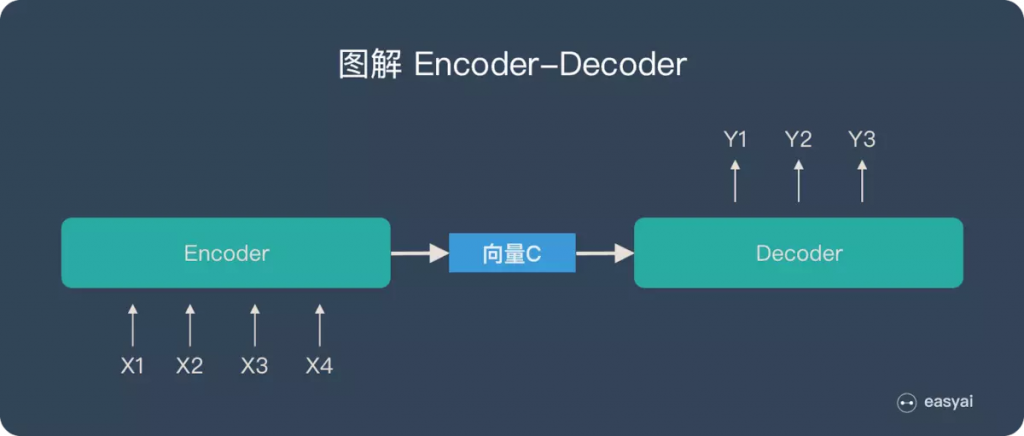
我们前面曾提过 Seq2Seq 模型里的一个重要假设是 Encoder 能把输入句子的语义 / 文本脉络全都压缩成一个固定维度的语义向量。之後 Decoder 只要利用该向量里头的资讯就能重新生成具有相同意义,但不同语言的句子。
但你可以想像当我们只有一个向量的时候,是不太可能把一个很长的句子的所有资讯打包起来的。
"与其只把 Encoder 处理完句子产生的最後「一个」向量交给 Decoder 并要求其从中萃取整句资讯,不如将 Encoder 在处理每个词汇後所生成的「所有」输出向量都交给 Decoder,让 Decoder 自己决定在生成新序列的时候要把「注意」放在 Encoder 的哪些输出向量上面。"
这事实上就是注意力机制(Attention Mechanism)的中心思想:提供更多资讯给 Decoder,并透过类似资料库存取的概念,令其自行学会该怎麽提取资讯。两篇核心论文分别在 2014 年 9 月及 2015 年 8 月释出,概念不难但威力十分强大。
"多数以 RNN 做过的研究,都可以用自注意力机制来取代;多数用 Seq2Seq 架构实现过的应用,也都可以用 Transformer 来替换。模型训练速度更快,结果可能更好。"
事实上只要是能用 RNN 或 Seq2Seq 模型进行的研究领域,你都会看到已经有大量跟(自)注意力机制或是 Transformer 有关的论文了:
- 文本摘要(Text Summarization)
- 图像描述(Image Captioning)
- 阅读理解(Reading Comprehension)
- 语音辨识(Voice Recognition)
- 语言模型(Language Model)
- 聊天机器人(Chat Bot)
- 其他任何可以用 RNN 的潜在应用
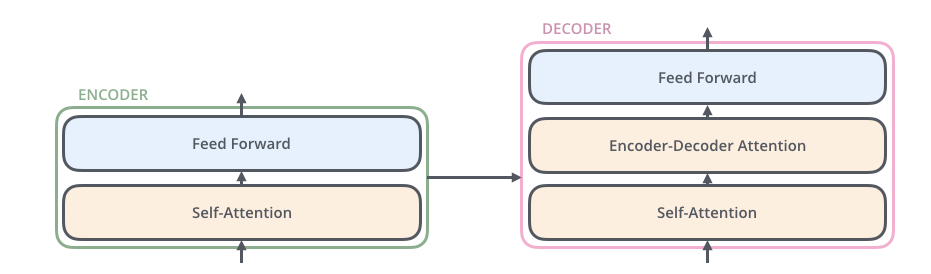
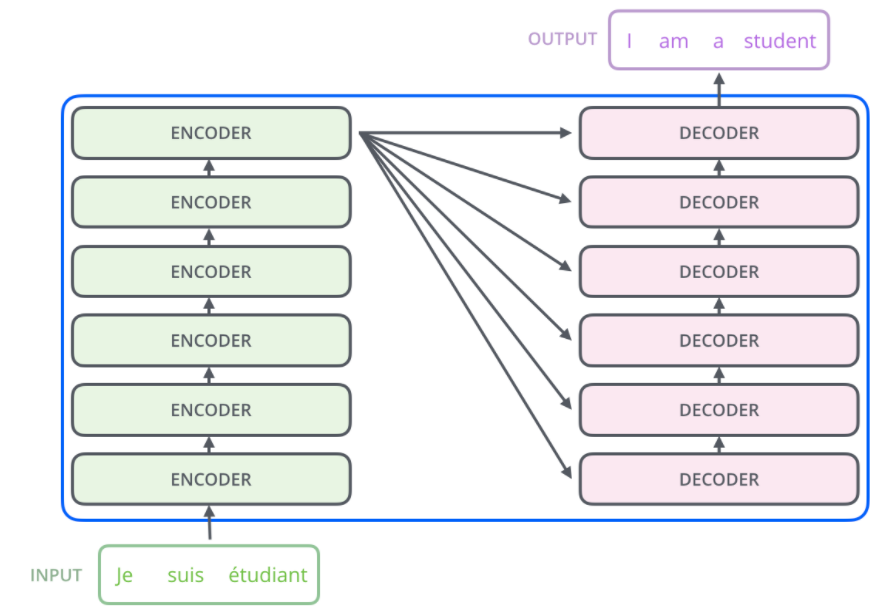
编码组件是一堆编码器(纸上将六个编码器彼此叠放–六个没有什麽神奇之处,可以尝试其他组合)。 解码组件是相同数量的解码器的堆栈。
注1: 「Seq2Seq」和「Encoder-Decoder」的关系
Seq2Seq(强调目的)不特指具体方法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。
而 Seq2Seq 使用的具体方法基本都属於Encoder-Decoder 模型(强调方法)的范畴。
总结一下的话:Seq2Seq 属於 Encoder-Decoder 的大范畴
注2: Encoder-Decoder、Seq2Seq、 以及Transformer之间的关系
注:本文是搜寻数个网站及各种不同来源之结果,着重在学习,有些内容已难办别出处,我会尽可能列入出处,若有疏忽或出处不可考,请联络我, 我会列入, 尚请见谅。
<<: Microsoft Windows VirtualDesktop 系列纪录 - MSIX AppAttach
30-10 之Presentation Layer - MVVM ( Model-View-ViewModel )
这个东东主要的概念来自 Martin Fowler 所写的 《 Presentation Model...
Day5 Game Frontend
今天我们来了解一下 Game Frontend 这个须由我们实作的部件,在 Open-Match 所...
[第02天]理财达人Mx. Ada-登入作业
目标 本文主要说明登入作业。 程序实作 # 载入shioaji函式库 import shioaji ...
【day8】居家办公的早餐diy卷饼
对比现在忙碌的工作 开始怀念过去两个月居家办公的时光 在相对有余裕的时候下厨 挑选自己喜欢的食物 一...
Android Studio 菜鸟笔记本-Day 26-介绍BottomNavigationView
BottomNavigationView是底部导览的控件,就像line下方的四个选项,今天我会分享B...