Day 6 - 目前(传统)的机器学习三步骤(1)-收集数据
如前所言,假设 y是结果(如股票价格) , x是变数(如进料成本,薪资成本......等) , 以机器学习方法找出y与x的关系, y=f(x), 如此可预测未来。
根据机器学习的目的,如何准确地预测或辨识,可分为以下三步骤
第一步 Data 收集数据:Clean / Prepare / Manipulate Data
第二步 Features 找出关键特徵
第二步 Training 训练并验证,找出最佳结果
例如
-
在现有手中的资料Data中,找X / Y对应
- 特徵 (Feature):⽤来描述每⼀笔资料,通常会⽤ X 来表⽰ 。
- 标记 (label):⽤来表⽰每⼀笔资料所对应的输出,这个输出样式可以有不同的状态(可能是类别或者实数值等),通常会⽤ Y。
- 机器学习(Training)就是利⽤历史资料(Data)找出⼀个函数 。
f : X →Y
-
若应⽤於辨识动物, 我们期待
输入X: 就会知道输出(辨识)时 f(X) = 猫的图片(Y)
就会知道输出(辨识)时 f(X) = 猫的图片(Y) -
若应⽤於语⾳辨识, 我们期待
输入X: 就会知道输出(辨识)时f(X) = ⼤家好 (Y)
就会知道输出(辨识)时f(X) = ⼤家好 (Y) -
可应⽤於预测明天天气如何
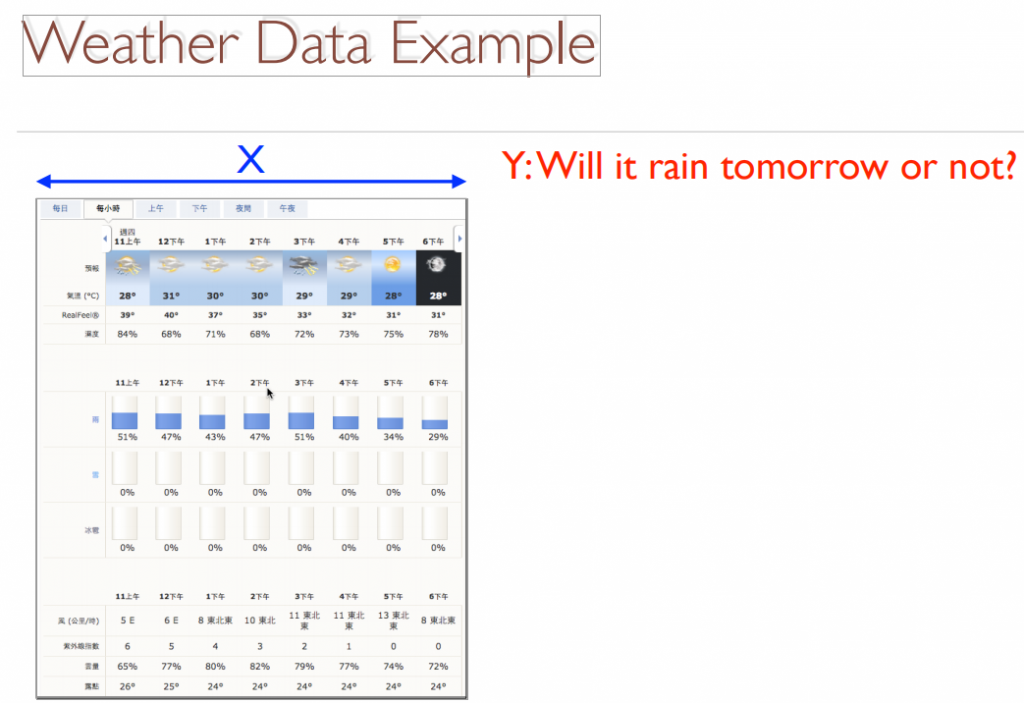
-
可应⽤於辨识交通工具

-
可应⽤於辨识spam mail
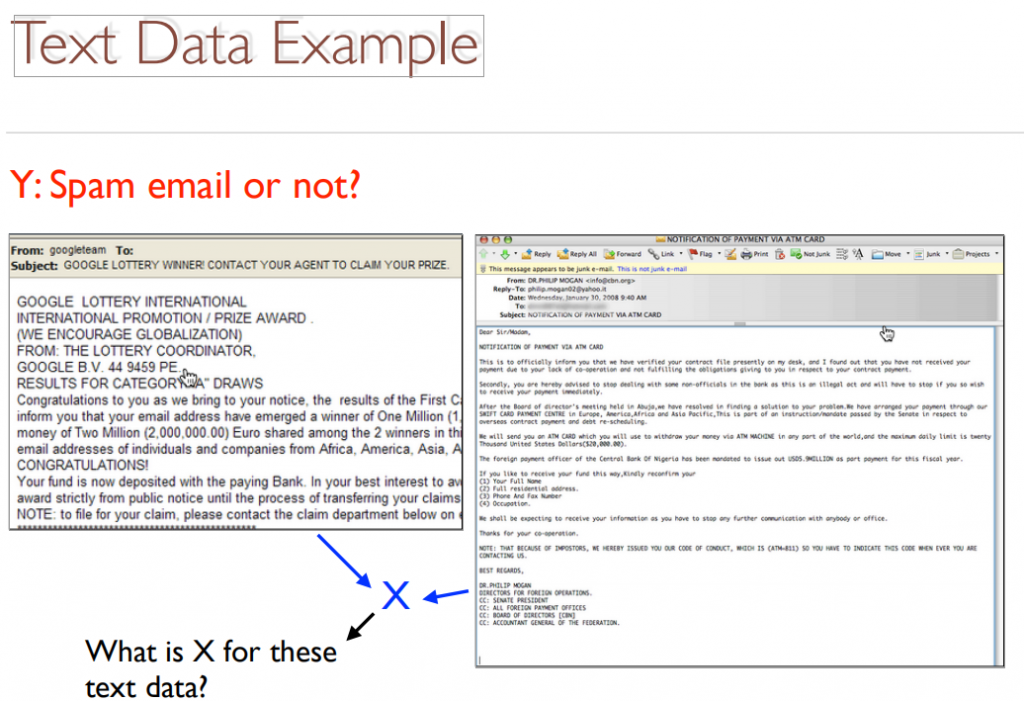
第一步 Data 收集数据
收集数据是一件不容易却是关键的第一件事情,很不幸的,收集数据是一件很浪费时间的事情,有时候收集数据也是一件反反覆覆的事情,收集不好可能需要再从来,因为
- 资料总是被糟蹋
- 资料一定不乾净
- 资料永远不完整
- 资料必然不前瞻
所以收集数据的"人"或称"专家"(domain know-how)很重要,必须对目的很了解,知道哪边可以收集数据,能够整理成乾净的数据,给下一步顺利地进行,否则容易失败,预测错误,甚至有时候必须要再回来收集数据,重头再来一次。
注:本文是搜寻数个网站及各种不同来源之结果,着重在学习,有些内容已难办别出处,我会尽可能列入出处,若有疏忽或出处不可考,请联络我, 我会列入, 尚请见谅。
<<: Gulp 基础介绍 gulp-load-plugins DAY82
>>: Gulp Babel ES6 编译(1) DAY83
【Day16-搜寻】茫茫文海当中找到那个对的词——文字处理利器之正规表达式在python的应用
前一天我们就如何让程序可以认得不同的单字稍微讨论了一下一些基本的处理,那今天我们就继续文字的主题来介...
Day11 配对品质评估 Evaluator
由於 Open-Match 在架构上,允许使用同一张 ticket,对不同的配对池进行搜寻与配对,这...
Day5 DCS 分散控制系统
基本介绍 DCS 分散控制系统(Distributed Control System):不需要有中...
[Day 28] 关於 InAppBrowser
InAppBrowser 说在最前面的,以目前的 iOS / Android 生态来看,所谓的 In...
Day 0x12 UVa10038 Jolly Jumpers
Virtual Judge ZeroJudge 题意 输入一串数字,输出是否为 Jolly Jum...