【Day29】为爬虫加上通知 - 成功收到 LINE 通知爬虫摘要讯息,专案大功告成!
除了要有专业外,你更要有技术整合的能力
 笔者有话先说
笔者有话先说
这份专案所用到的各种技术都不难,难的是将这些技术整合成一个能让客户买单的专案;当时在跟工程师朋友分享这个专案的技术组成时他们都觉得很是猎奇,没想到爬虫专案还能用如此低成本的方式完成,而且真的能帮客户解决问题
今天这篇文章是实作的最後一篇,我们要将爬虫执行时的资讯做成一份摘要,透过 LINE 发送给使用者
 今日目标
今日目标
- 分析爬虫摘要讯息来源
- 调整爬虫函式回传的资料结构
- 调整主程序传递 lineNotify 所需的参数
- 在
lineNotify函式中整合摘要讯息
1. 分析爬虫摘要讯息来源
根据需求规格书,在摘要中需包含以下讯息:
- 爬虫总费时:在主程序计算从爬虫开始到更新完 Google sheet 的时间
-
总计扫描FB粉专、IG帐号数量:因为爬虫函式
crawlerIG、crawlerFB回传的结果result_array是阵列的形式,所以数量的部分使用阵列的长度即可 -
Google Sheets 连结:依照 .env 环境档中的
SPREADSHEET_ID组成连结 -
无法爬虫的FB粉专、IG帐号名称:在爬虫函式
crawlerIG、crawlerFB中纪录无法爬虫的标题
2. 调整爬虫函式回传的资料结构
下面用 crawlerFB 来举例,crawlerIG 可以自己尝试修改看看喔~
- 使用
error_title_array来纪录无法爬虫的标题 - 完成爬虫後回传 爬虫结果(result_array)、无法爬虫的粉专标题(error_title_array) 这两个参数,让後续 Google Sheet 更新、LINE Notify 传送通知时使用
async function crawlerFB (driver) {
const isLogin = await loginFacebook(driver)
if (isLogin) {
console.log(`FB开始爬虫`)
let result_array = [], error_title_array = []// 纪录无法爬虫的标题
for (fanpage of fanpage_array) {
let trace = null
try {
const isGoFansPage = await goFansPage(driver, fanpage.url)
if (isGoFansPage) {
await driver.sleep((Math.floor(Math.random() * 4) + 3) * 1000)
trace = await getTrace(driver, By, until)
}
if (trace === null) {// 将无法爬虫的标题放入阵列
error_title_array.push(fanpage.title)
console.log(`${fanpage.title}无法抓取追踪人数`)
} else {
console.log(`${fanpage.title}追踪人数:${trace}`)
}
} catch (e) {
console.error(e);
continue;
} finally {
result_array.push({
url: fanpage.url,
title: fanpage.title,
trace: trace
})
}
}
// 回传爬虫结果、无法爬虫的粉专标题
return { "result_array": result_array, "error_title_array": error_title_array }
}
}
3. 调整主程序传递 lineNotify 所需的参数
-
爬虫总费时:使用
spend_time函式把时间差转换成 时 分 秒的格式因为朋友数百个品牌爬虫总费时快两小时,如果用秒数呈现实在太不人性化了
- 整合
lineNotify所需的参数: 爬虫总费时(spend_time)、总计扫描FB粉专、IG帐号数量(result_array.length)、无法爬虫的FB粉专、IG帐号名称(error_title_array)
index.js
require('dotenv').config();
const { initDrive } = require("./tools/initDrive.js");
const { crawlerFB } = require("./tools/crawlerFB.js");
const { crawlerIG } = require("./tools/crawlerIG.js");
const { updateGoogleSheets } = require("./tools/google_sheets");
const { lineNotify } = require("./tools/lineNotify.js");
exports.crawler = crawler;
async function crawler () {
const start_time = new Date(); // 取得开始时间
const driver = await initDrive();
if (!driver) {
return
}
// 分别取出爬虫结果、无法爬虫的粉专标题
const { "result_array": ig_result_array, "error_title_array": ig_error_title_array } = await crawlerIG(driver)
const { "result_array": fb_result_array, "error_title_array": fb_error_title_array } = await crawlerFB(driver)
driver.quit();
await updateGoogleSheets(ig_result_array, fb_result_array)
const end_time = new Date(); // 取得结束时间
// 计算爬虫作业总费时
const spend_time = spendTime(start_time, end_time)
// 执行完毕後用 lineNotify 回报爬虫状况
lineNotify(spend_time, ig_result_array.length, fb_result_array.length, ig_error_title_array, fb_error_title_array)
}
function spendTime (start_time, end_time) {
const milisecond = end_time.getTime() - start_time.getTime() //时间差的毫秒数
//计算出相差天数
const days = Math.floor(milisecond / (24 * 3600 * 1000))
//计算出小时数
const leave1 = milisecond % (24 * 3600 * 1000)// 计算天数後剩余的毫秒数
const hours = Math.floor(leave1 / (3600 * 1000))
//计算相差分钟数
const leave2 = leave1 % (3600 * 1000)// 计算小时数後剩余的毫秒数
const minutes = Math.floor(leave2 / (60 * 1000))
//计算相差秒数
const leave3 = leave2 % (60 * 1000)// 计算分钟数後剩余的毫秒数
const seconds = Math.round(leave3 / 1000)
let time_msg = ""
if (days !== 0)
time_msg = time_msg + days + '天'
if (hours !== 0)
time_msg = time_msg + hours + '小时'
if (minutes !== 0)
time_msg = time_msg + minutes + '分'
if (seconds !== 0)
time_msg = time_msg + seconds + '秒'
return time_msg
}
4. 在 lineNotify 中整合摘要讯息
- 使用
combineErrMsg将无法爬虫的FB粉专、IG帐号标题整合 - 将最终要传送的讯息组合在
message变数中
const axios = require('axios')
var FormData = require('form-data');
require('dotenv').config();
module.exports.lineNotify = lineNotify;
async function combineErrMsg (error_title_array, type) {
let error_msg = ""
for (const error_title of error_title_array) {
error_msg = error_msg + '\n' + error_title
}
if (error_msg !== "") {
error_msg = `\n\n下列${type}标题无法正常爬虫:` + error_msg
}
return error_msg
}
async function lineNotify (time, ig_total_page, fb_total_page, ig_error_title_array, fb_error_title_array) {
const token = process.env.LINE_TOKEN;
// 无法爬虫的FB粉专、IG帐号名称整合
const fb_error_msg = await combineErrMsg(fb_error_title_array, "FB")
const ig_error_msg = await combineErrMsg(ig_error_title_array, "IG")
let error_msg = fb_error_msg + ig_error_msg
// 组合传送讯息
const message =
`\n\n已完成今日爬虫排程作业` +
`\n共费时:${time}` +
`\n总计扫描FB粉专: ${fb_total_page} 、IG帐号: ${ig_total_page}` +
`\nGoogle Sheet: https://docs.google.com/spreadsheets/d/${process.env.SPREADSHEET_ID}` +
error_msg;
const form_data = new FormData();
form_data.append("message", message);
const headers = Object.assign({
'Authorization': `Bearer ${token}`
}, form_data.getHeaders());
axios({
method: 'post',
url: 'https://notify-api.line.me/api/notify',
data: form_data,
headers: headers
}).then(function (response) {
// HTTP状态码 200 代表成功
console.log("HTTP状态码:" + response.status);
// 观察回传的资料是否与 POSTMAN 测试一致
console.log(response.data);
}).catch(function (error) {
console.error("LINE通知发送失败");
if (error.response) { // 显示错误原因
console.error("HTTP状态码:" + error.response.status);
console.error(error.response.data);
} else {
console.error(error);
}
});
}
 执行程序
执行程序
- 为了确认我们爬虫摘要能纪录无法爬虫的页面,
我在 ig.json、fb.json 里面各新增了两个无效的粉专网址 - 在专案资料夹的终端机(Terminal)执行指令
yarn start - 程序执行完毕後确认 Google Sheets 的资料有正确写入
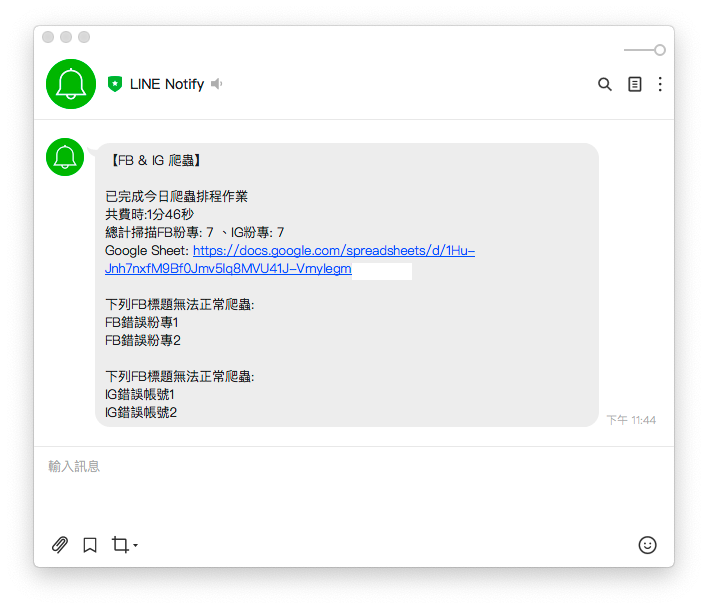
- 收到 LINE 通知爬虫摘要讯息就代表大功告成啦!!!
ℹ️ 专案原始码
- 今天的完整程序码可以在这里找到喔
- 我昨天的把昨天的程序码打包成压缩档,你可以在乾净的环境完成专案的最後一步:发出LINE通知让使用者知道这次爬虫的情况
- 请记得在终端机下指令 yarn 才会把之前的套件安装
- windows需下载与你chrome版本相同的chrome driver放在专案根目录
- 要在tools/google_sheets资料夹放上自己的凭证,申请流程请参考Day17
- 调整fanspages资料夹内目标爬虫的粉专网址
- 调整.env档
- 填上FB登入资讯
- 填上FB版本(classic/new)
- 填上IG登入资讯
- 填上SPREADSHEET_ID
- 填上爬虫执行时间(CRONJOB_TIME)
- 填上LINE Notify申请的权杖(LINE_TOKEN),申请流程请参考Day27
- 在终端机下指令 npm install forever -g ,让你在终端机的任何位置都能管控排程
- 在sh资料夹中设定执行排程的shell script
我在 Medium 平台 也分享了许多技术文章
❝ 主题涵盖「MIS & DEVOPS、资料库、前端、後端、MICROSFT 365、GOOGLE 云端应用、自我修炼」希望可以帮助遇到相同问题、想自我成长的人。❞
在许多人的帮助下,本系列文章已出版成书,并添加了新的篇章与细节补充:
- 加入更多实务经验,用完整的开发流程让读者了解专案每个阶段要注意的事项
- 将爬虫的步骤与技巧做更详细的说明,让读者可以轻松入门
- 调整专案架构
- 优化爬虫程序,以更广的视角来撷取网页资讯
- 增加资料验证、错误通知等功能,让爬虫执行遇到问题时可以第一时间通知使用者
- 排程部分改用 node-schedule & pm2 的组合,让读者可以轻松管理专案程序并获得更精确的 log 资讯
有兴趣的朋友可以到天珑书局选购,感谢大家的支持。
购书连结:https://www.tenlong.com.tw/products/9789864348008

6. Prototypal inheritance 的运作原理
(这篇会延续Constructor Function的内容,来解释 Prototype 和 Prot...
Sass @import DAY34
今天我们要来学习如何把Sass切分支许多档案 这样会使我们比较容易管理 @import(汇入) 可将...
Day 24 开发者福音无服务器运算
随着资讯技术普及与推陈布新,基础设施及服务(IaaS)、平台即服务(PaaS)、软件即服务(Saa...
DAY1 筑个前端毛胚屋
嗨我是稚鸟。这是一个for比菜鸟还菜的幼鸟前端指南。 幼鸟品种说明:学过一种程序语言,但对前端没啥概...