Elastic Stack第二十六重
Query DSL Part VII (查询语法)
本篇继续介绍 Query DSL 的 term-lvel queries
range query
找出terms在指定的range的documents
[情境] 找出 field age 的field value 介於 10(包含) 和 20(包含) 之间的documents
Example Request
GET /_search
{
"query": {
"range": { (1)
"age": { (2)
"gte": 10, (3)
"lte": 20 (4)
}
}
}
}
(1): range query
(2): <field>,必填,欲搜寻的 field
(3): gte,大於等於
(4): lte,小於等於
当然,有大於等於,也有 "大於",使用 gt,同理,"小於" 使用 lt
range query with text and keyword fields
实际上,range query是可以用在 field type为 text 和 keyword 的fields,
不过是属於 expensive queries (成本比较高),所以一般而言执行会比较慢。
而有参数可以限制 expensive queries, search.allow_expensive_queries 预设为 true,
当设定为 false 时,就无法执行 expensive queries,也就会包含无法使用 range query 来搜寻 field data type 为 text 和 keyword 的fields。
range query with date fields
如果 <field> 的 field data type为 date,则可以使用 date math(https://www.elastic.co/guide/en/elasticsearch/reference/current/common-options.html#date-math) 搭配 gt, gte, lt, lte
[情境] 找出 field timestamp 的field value 介於 今天 和 昨天 之间的documents
Example Request
GET /_search
{
"query": {
"range": {
"timestamp": {
"gte": "now-1d/d", (1)
"lt": "now/d" (2)
}
}
}
}
(1): 现在 减 1天,并无条件舍去至最近的天
(2): 现在,并无条件舍去至最近的天
这边稍微说明一下 date math,
可使用日期来当锚点(anchor),如 now 或者是 formatted date,而如果使用 formatted date,其後面须加上 ||,然後在 anchor date 後面可选择性加上 数学式,
例如:
-
+1h: 加上1小时 -
-1d: 减1天 -
/d: 无条件舍去至最近的天
regex query
透过 regular expression 找出有匹配的terms,然後回传其documents
而 regex query 支援的operators可参阅 Regular expression syntax ,是使用 Apache Lucene's 的 regular expression 引擎
[情境] 找出field user.id 是 k 开头,y 结尾的documents
Example Request
GET /_search
{
"query": {
"regexp": { (1)
"user.id": { (2)
"value": "k.*y", (3)
"flags": "ALL" (4)
}
}
}
}
(1): 即 regex query
(2): <field>,必填,欲搜寻的 field
(3): value,必填,填入 regular expression
(4): flags,选填,预设为 ALL,此参数用来设定 regular expression引擎 可使用的operators
上述request的 regex为 "k.*y",其中 .* operators 代表的是可以匹配任何字元,包括没有字元也算,所以可以匹配的terms可以是 ky, kay, kelly 等等
[Note]
regex query也是属於 expensive queries
term query
搜寻出指定field含 exact term 的documents
在蛮多篇章应该都有提到此 query,这边再完整介绍一次
[Note]
避免使用 term query 在 text field 上,因为 text field在建立索引时,会经过 analyzer分析而改变原本的值,所以会让精确匹配是很困难的
此范例使用 Elastic Stack第七重 汇入的范例资料,所以想用一样的测资可先照那一重做批次汇入
[情境] 找出 field firstname 为 "Nanette" 的 帐户拥有者资讯(document)
Request
GET /bank/_search
{
"query": {
"term": { (1)
"firstname.keyword": { (2)
"value": "Nanette" (3)
}
}
}
}
(1): 即 term query
(2): <field>,必填,欲搜寻的field,记得使用非 text field,此处使用 "firstname.keyword" 的 field date type为 keyword,而 "firstname" 是 text field data type,所以不能使用 "firstname" ,否则会不如预期(以此为例,用 "firstname" 会匹配不到任何documents)
(3): value,必填,欲搜寻的值
Response

上述Request也可以简写成
GET /bank/_search
{
"query": {
"term": {
"firstname.keyword": "Nanette"
}
}
}
[Note]
如欲搜寻 text fields,可以透过 match query,在储存至此field前会经过analyzer分析後转换成tokens才会被建立索引,而用 match query 提供的 query string(search term)也一样会经过analyzer分析,此两个analyzer是可以指定成不一样的analyzer,在未设定时,皆使用预设的 standard analyzer ,透过分析後的 tokens 来做匹配搜寻,而不是用 exact term(精确的值)
而 term query "不会"分析 search term, term query 直接拿提供的term找出完整符合的term,这也意味着用 term query 搜寻 text fields 可能回传 poor(较少) 或 没有匹配的documents
terms query
搜寻出指定field含 一个或多个 exact term 的documents,
其实和 term query一样,只是差在可以搜寻多个值
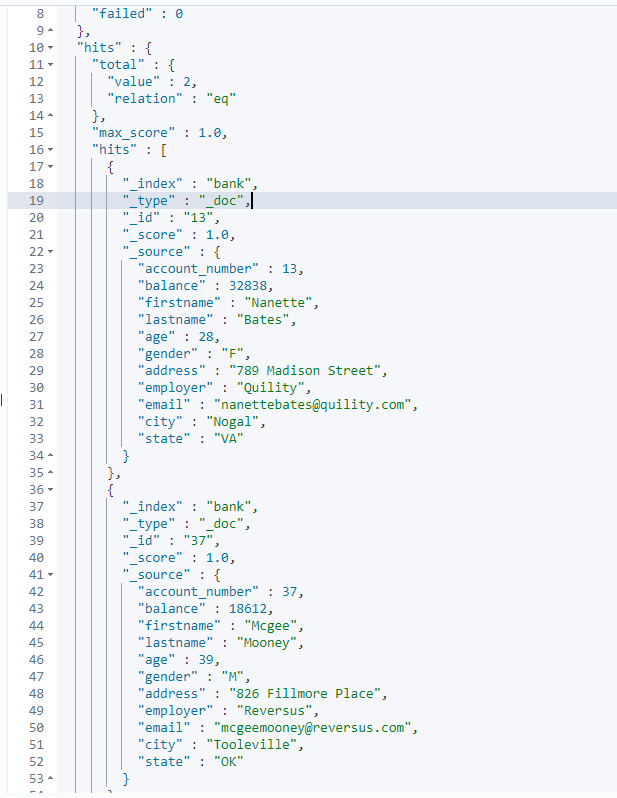
[情境] 找出 field firstname 为 "Nanette" 或 "Mcgee" 的 帐户拥有者资讯(document)
Request
GET /bank/_search
{
"query": {
"terms": { (1)
"firstname.keyword": ["Nanette", "Mcgee"] (2)
}
}
}
(1): 即 terms query
(2): 放置多个 search term至array value
Response
小小新手,如有理解错误或写错再请不吝提醒或纠正
Reference
Term-level queries
regular expression
>>: IOS 菜菜菜鸟30天挑战 Day-28 下拉式选单
与Arduino接起来
前面提到Raspberry pi有哪些传输方式 IIC/SPI/1-wire/UART 书上建议可以...
我的JavaScript日常- 第 31 天不是结束,反而是开始
昨天总算完成了「我的JavaScript日常」的最後一篇文章,很高兴自己成功挑战了 30 天的研究与...
[JS] You Don't Know JavaScript [Scope & Closures] - Using Closures?
前言 目前为止我们都专注在解释辞法范围,以及他会对程序中的变量与使用产生什麽影响,本章节会将角度转移...
【Day26】:从struct进化成class的物件导向技巧(下)
建构子 建构子(constructor)是一种初始化类别物件的成员函式,每一种类别都有一个建构子,当...
变更管理(Change management )
-不同程度的变化(来源:plutora) 变更管理至关重要,但也有开销。一些例行变更可能会被预先批...