Day 27 - 建立自己的K线资料库 (中)
本篇重点
- 透过Pandas读取资料及做OHLC转换
- DataFrame.resample中的Left与Right
- 使用DataFrame.dropna移除资料
- 产生5分K资料并储存至资料库
透过Pandas读取资料及做OHLC转换
所谓的OHLC(或是OHLCV),就是指Open、High、Low及Close(加上Volume)这几个栏位。之前的文章中,是将这几个栏位分别做resample後,再结合成一个DataFrame,但最近做功课时,发现其实可以直接用pandas中的aggregation做运算
Pandas OHLC aggregation on OHLC data
程序范例如下:
import pandas as pd
import sqlite3
conn = sqlite3.connect('D:/shioaji.db') #建立资料库连线
#从stocks_1min_kbars这个Table中,取出2890这档股票的资料,并且将ts资料type转换为datetime64
df = pd.read_sql('SELECT * FROM stocks_1min_kbars WHERE code = "2890"', conn, parse_dates=['ts'])
# 加inplace=True,代表index变动後直接取代原本的dataFrame,而不是回传一个新的dataFrame
df.set_index('ts', inplace=True)
df_5minK = df.resample('5min').agg({'Open': 'first',
'High': 'max',
'Low': 'min',
'Close': 'last',
'Volume': 'sum'})
df_5minK.to_csv('5minK.csv', encoding="utf_8_sig") #将处理後的资料先汇出成csv档
conn.close() #关闭资料库连线
当在处理这类大量的资料时,我会先抓一部份的资料做处理,当处理的结果确定是我要的,我才会正式开始处理全部的资料,以免花了一大堆时间後才发现跑出来的资料是错的。
上面的程序,我先用pandas.read_sql抓2890永丰金的1分K资料,这里请务必要加上parse_dates=['ts'],这样下面的set_index才可以正常执行。
这里的resample,是参考上面文章中aggregation方式处理,并且加入成交量Volume这个栏位。转换成5分K并汇出成CSV档,开启档案後,可以看到2021-10-08第一个及第二个5分K,成交量分别为714和137,跟三竹及XQ的前两个5分K成交量是不同的
比对1分K的资料之後,发现我们所做的resample,前两个5分K分别是抓「09:01-09:04」及「09:05-09:09」,而看盘软件则是抓「09:01-09:05」及「09:06-09:10」
要解决这个问题,可以在resample中传入「closed='right'」,修改後的程序如下:
# 执行resample,并指定close为right
df_5minK = df.resample(rule='5min', closed='right').agg({'Open': 'first',
'High': 'max',
'Low': 'min',
'Close': 'last',
'Volume': 'sum'})
这样resample出来的数字,就会跟看盘软件中的数字一样
DataFrame.resample中的Left与Right
关於DataFrame.resample中的Left与Right,在官方的说明文件中并没有特别说明,以下为我个人的理解
以上面我们针对1分K做resample为列,当我们执行df.resample(rule='5min')时,pandas就会依照DataFrame中的index,先将资料做分割;虽然在1分K中并没有09:00的资料,但在做resample时,预设是会自动填补资料上去,此时的资料转为横向就会如下图这样排列,黄色底就是所谓分割点
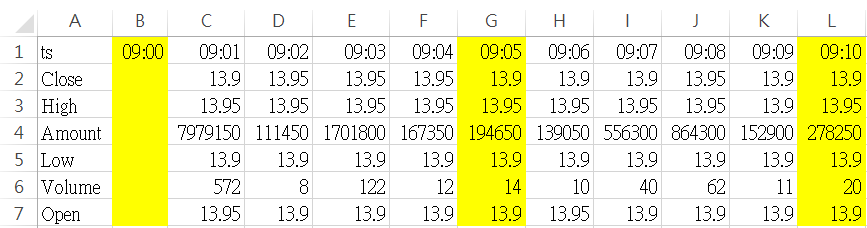
在DataFrame.resample中,label参数影响的是resample後的index内容,而closed则是影响resample後data的内容。在执行resample时,若未指定label跟closed这两个参数,则预设皆为left,所以resample後,第一组资料的index会是09:00,而data部份也是抓09:00-09:04去做计算
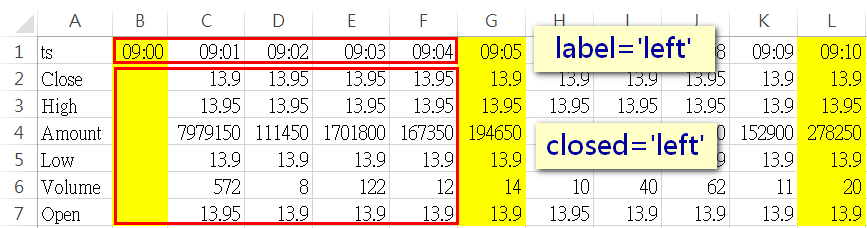
而在执行resample时传入「closed='right'」,第一组资料的index一样是09:00,而data部份就变成抓09:01-09:05去做计算(即所谓的向右结合)
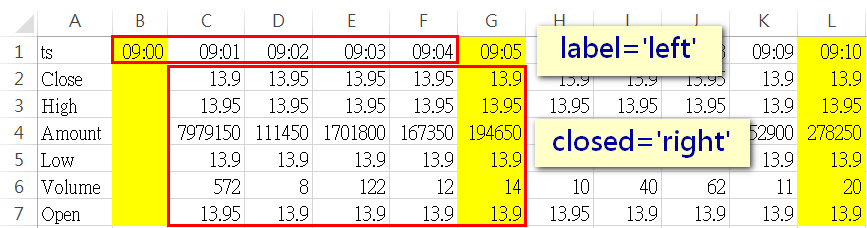
若在执行resample时传入「closed='right'」及「label='right'」,第一组资料的index就会变成是09:05(向右结合),而data部份一样是抓09:01-09:05去做计算(即所谓的向右结合)
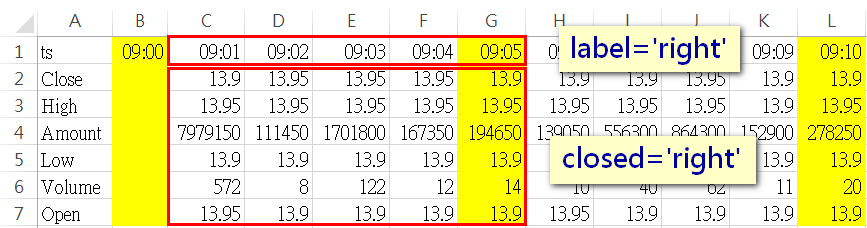
若将上面的资料转出来并跟看盘软件比较,你会发现XQ的5分K资料就是label='left'+closed='right';而三竹的5分K资料就是label='right'+closed='right'。
使用DataFrame.dropna移除资料
另外,在CSV档中,可以看到在执行resample後,pandas会帮我们在每个交易日的13:30到次一个交易日的09:00之间,增加对应时间的资料,但因为这段时间没有资料,所以OHLC的栏位内容皆为空值。我们可以用
pandas.DataFrame.dropna来删除这些不需要的资料
df_5minK.dropna(axis=0, inplace=True) #移除有空值的row,并取代原本的DataFrame
产生5分K资料并储存至资料库
接着,我们就可以依照上面的程序码,稍做修改来产生所有股票的5分K资料,完整程序范例如下:
import pandas as pd
import sqlite3
conn = sqlite3.connect('D:/shioaji.db') #建立资料库连线
# 传入股票代码,产生5分K资料并存至资料库
def generate_5min_kbar(stock_code):
print(f'generate 5minK for stock:{stock_code}') #输出程序执行点资料至console
df = pd.read_sql(f'SELECT code, Open, High, Low, Close, Volume, ts FROM stocks_1min_kbars WHERE code = {stock_code}', conn, parse_dates=['ts'])
df.set_index('ts', inplace=True)
df_5min_kbar = df.resample(rule='5min', closed='right').agg({
'code': 'first',
'Open': 'first',
'High': 'max',
'Low': 'min',
'Close': 'last',
'Volume': 'sum'})
df_5min_kbar.dropna(axis=0, inplace=True)
df_5min_kbar.to_sql('stocks_5min_kbars', conn, if_exists='append')
print(f'stock:{stock_code}, 5minK is added to DB...') #输出程序执行点资料至console
cursor = conn.cursor() #建立cursor物件
# 执行SQL,取出stocks_1min_kbars中所有的股票代码(不重复)
for code in cursor.execute('SELECT DISTINCT code FROM stocks_1min_kbars'):
generate_5min_kbar(code[0])
conn.close() #关闭资料库连线
请注意,在df_5min_kbar.to_sql这里,并没有传入index=False,因为现在df_5min_kbar中的index就是ts栏位,而写入资料库是需要保留这个栏位内容,供後续处理资料时使用。
若要产生其它分K的资料,只要稍微修改上面的程序码,就可以产生对应的资料。
>>: 【Day 27】Google Apps Script - API Blueprint 篇 - Apiary 建立专案与版本控制
[C#] 产生 MSSQL Table DML (SELECT, INSERT, UPDATE, DELETE) SQL 语法
当我们要在资料表内操作资料时,最常执行的指令就是 Select, Insert, Update, D...
DAY 26 『 AVPlayerViewController - 播放影片 』
今天要分享的是,如何用 AVPlayerViewController 显示影片 成品: {%yout...
创建App-Google sign in my App
创建App-Google sign in my App 本App设想登入方法有Google、Appl...
DAY15:玉山人工智慧挑战赛-中文手写字辨识(Pytorch 自订义资料集)
资料扩增 我们组的资料扩增这部分,因为第一次比赛,这个方法效果没有到非常好,采取的是用mask的方式...
day2: 程序码风格的重要性
对於程序码的风格,不管是初学者或是有经验的开发者,当一个专案执行时, 在规划程序码的写法,若没有考虑...