[DAY24] Azure Machine Learning SDK 的 ScriptRunConfig
DAY24 Azure Machine Learning SDK 的 ScriptRunConfig
我们在训练模型的过程中,常常会写好训练用的 script,跑那个 script 以训练模型并得到结果。下面这个 MNIST 手写数字辨识的程序码,一般就是我们在训练模型时会用的程序码。
import tensorflow as tf
data = tf.keras.datasets.mnist
(x_train, y_train),(x_test,y_test) = data.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28,1)
x_test = x_test.reshape(x_test.shape[0], 28, 28,1)
x_train, x_test = x_train/255.0, x_test/255.0
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
model = tf.keras.models.Sequential(
[
tf.keras.layers.Conv2D(32,(3,3), activation='relu',input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
]
)
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
model.fit(x_train,y_train,epochs=10)
model.evaluate(x_test, y_test)
model.save("./mnist.h5")
可是我们学到了 Experiment,学到 Run,学到了 Enviroment,还有运算资源等等的元件,我们要怎麽把他们用在一个真实世界的 AI 专案呢?这时候就要用到 ScriptRunConfig 了。ScriptRunConfig 可以想成一个 config 档,我们把想要跑的环境、程序码等等的资讯设定进去,然後再把这个 config 档提交给 experiment 来跑实验。现在我们就来看看 ScriptRunConfig 怎麽使用吧!
开始使用 ScriptRunConfig
- 先来改写上面那段 MNIST 的程序码,我们在这里会用 Run 的另一种写法,这边要注意一下哦!然後我们把这个档案存成
train_mnist.py。
from azureml.core import Run
import tensorflow as tf
# 用 Run.get_context() 来开始一个 Run。
run = Run.get_context()
data = tf.keras.datasets.mnist
(x_train, y_train),(x_test,y_test) = data.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28,1)
x_test = x_test.reshape(x_test.shape[0], 28, 28,1)
x_train, x_test = x_train/255.0, x_test/255.0
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
model = tf.keras.models.Sequential(
[
tf.keras.layers.Conv2D(32,(3,3), activation='relu',input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
]
)
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
model.fit(x_train,y_train,epochs=10)
loss, acc = model.evaluate(x_test, y_test)
#用 Run 记一下 log
run.log('Accuracy', acc)
model.save("./mnist.h5")
- 接着我们在要跑 Experiment 的档案里,使用以下程序码:
from azureml.core import Experiment, ScriptRunConfig, Environment, Workspace
ws = Workspace.from_config()
# 这里我们用内建的环境
env = Environment.get(ws,"AzureML-tensorflow-2.4-ubuntu18.04-py37-cuda11-gpu")
# 建立 ScriptRunConfig
script_config = ScriptRunConfig(source_directory='.',
script='train_mnist.py',
environment=env)
# 提交实验
experiment = Experiment(workspace=ws, name='training-experiment')
run = experiment.submit(config=script_config)
run.wait_for_completion()
-
等待这个实验跑完了之後,我们就到 AML 的图形化介面去看,真的多出这个 experiment 了。如下图。
-
点进这个实验看,就可以到刚刚跑好那个 Run。
-
我们刚刚有做一个 log,去纪录下准确度,我们点进 Metrics 这个页签,就可以看到刚刚的纪录罗!
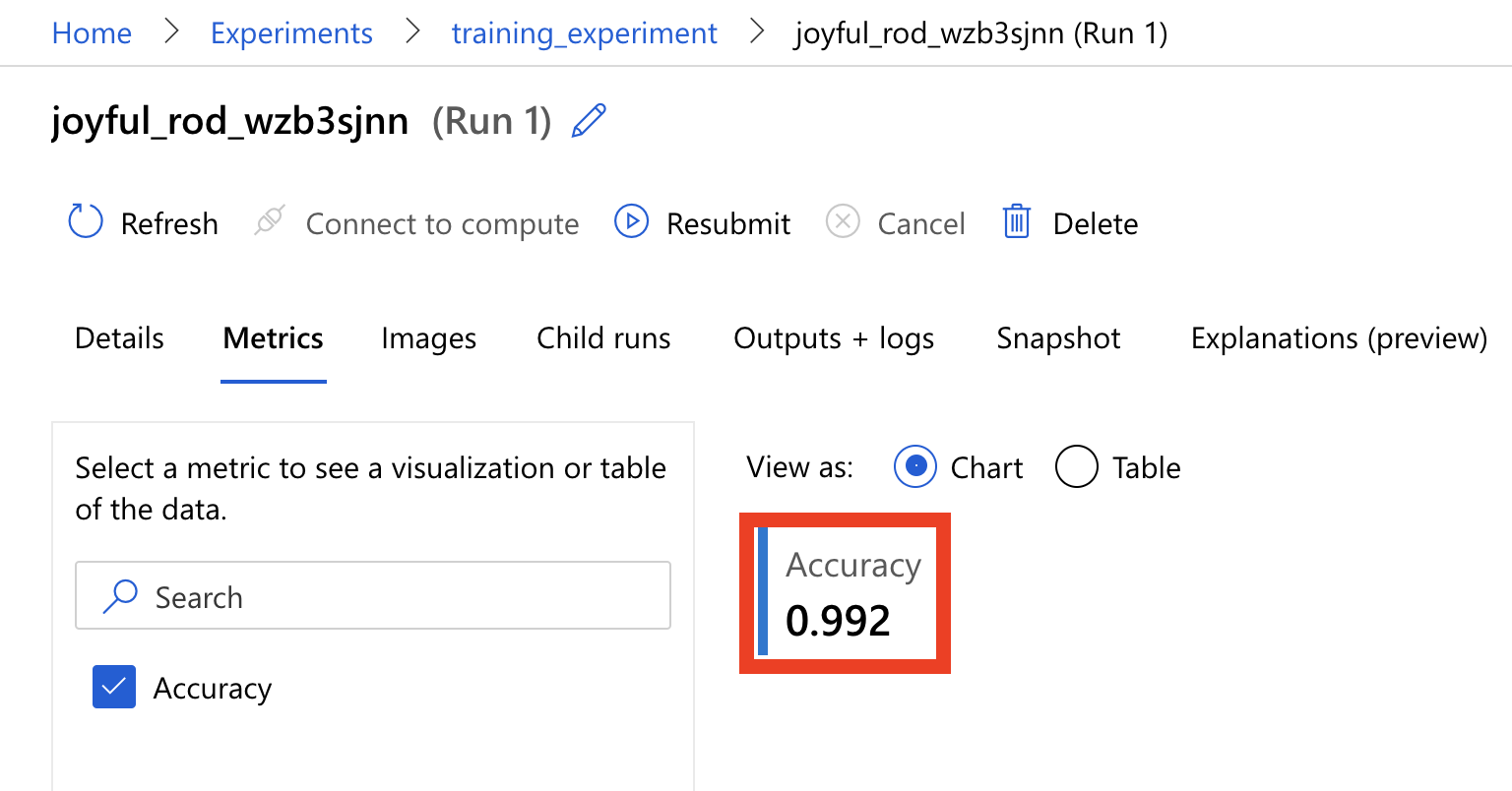
参数化训练的 script
- 我们还可以把 script 参数化哦!然後再透过 ScriptRunConfig 把参数丢进去即可!把
train_mnist.py程序码改写如下,另存成train_mnist_para.py:
import argparse
from azureml.core import Run
import tensorflow as tf
run = Run.get_context()
# 用 argparse 来参数化,我们把 echo 改成参数化吧!
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, dest='epochs', default=1)
args = parser.parse_args()
epoch_para = args.epochs
data = tf.keras.datasets.mnist
(x_train, y_train),(x_test,y_test) = data.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28,1)
x_test = x_test.reshape(x_test.shape[0], 28, 28,1)
x_train, x_test = x_train/255.0, x_test/255.0
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
model = tf.keras.models.Sequential(
[
tf.keras.layers.Conv2D(32,(3,3), activation='relu',input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
]
)
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
# 把 argparse 得到的参数放进去
model.fit(x_train,y_train,epochs=epoch_para)
loss, acc = model.evaluate(x_test, y_test)
# Log 一下 epoch 数
run.log('Epoch', epoch_para)
run.log('Accuracy', acc)
model.save("./mnist.h5")
- 然後 ScriptRunConfig 改写成这样子,然後提交实验:
from azureml.core import Experiment, ScriptRunConfig, Environment, Workspace
ws = Workspace.from_config()
env = Environment.get(ws,"AzureML-tensorflow-2.4-ubuntu18.04-py37-cuda11-gpu")
# 把参数设定进去
# 多个参数可以 ['--epochs', 2, --filter, 64] 依照这样子的规则往後加
script_config = ScriptRunConfig(source_directory='.',
script='train_mnist_para.py',
arguments = ['--epochs', 2],
environment=env)
# 提交实验,这里我们再取另一个实验名称
experiment = Experiment(workspace=ws, name='training_experiment_para')
run = experiment.submit(config=script_config)
run.wait_for_completion()
-
等待这个实验跑完了之後,我们就到 AML 的图形化介面去看,真的多出这个参数化的 experiment 了。如下图。
-
点进这个实验看,就可以到刚刚跑好那个 Run。
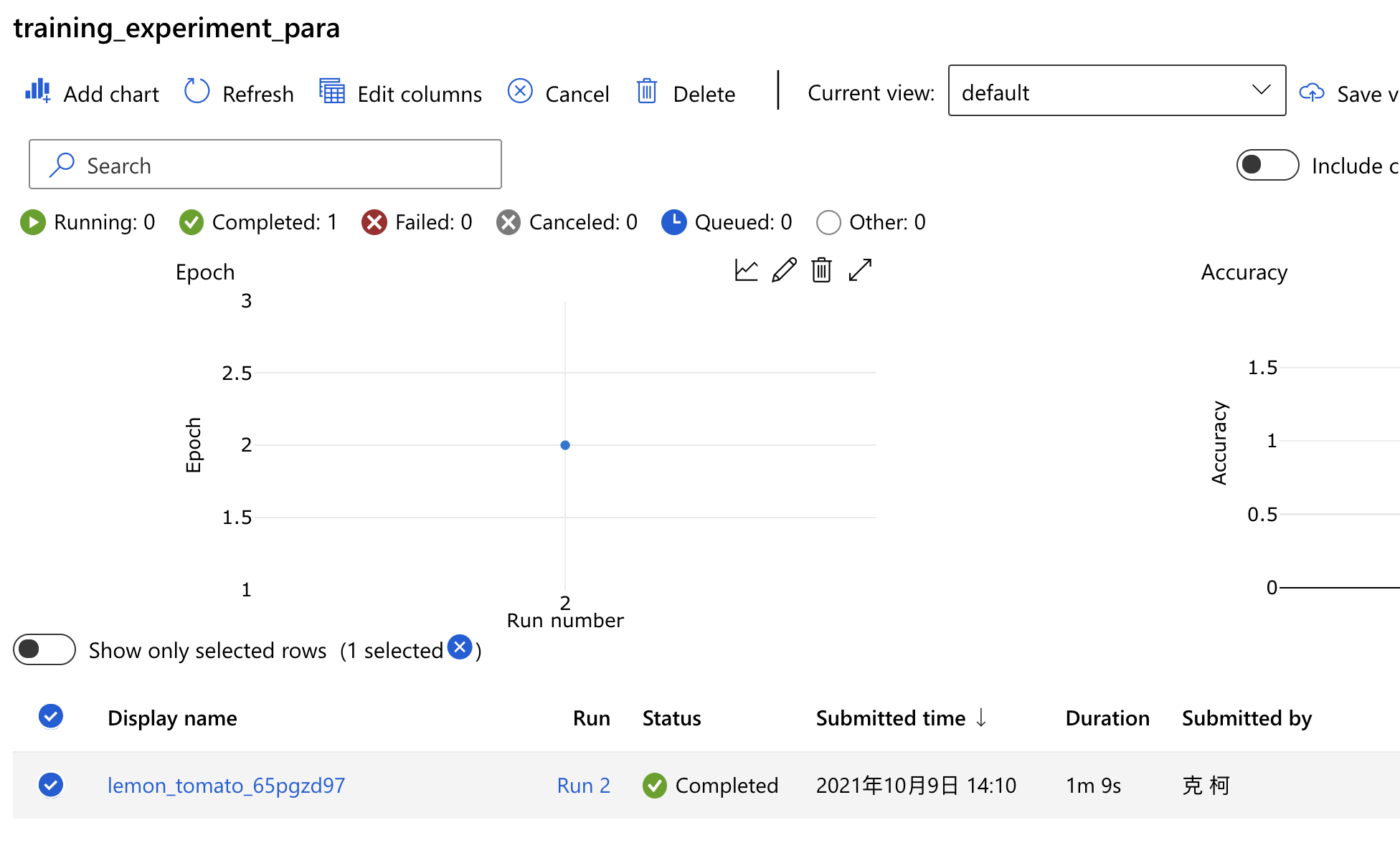
-
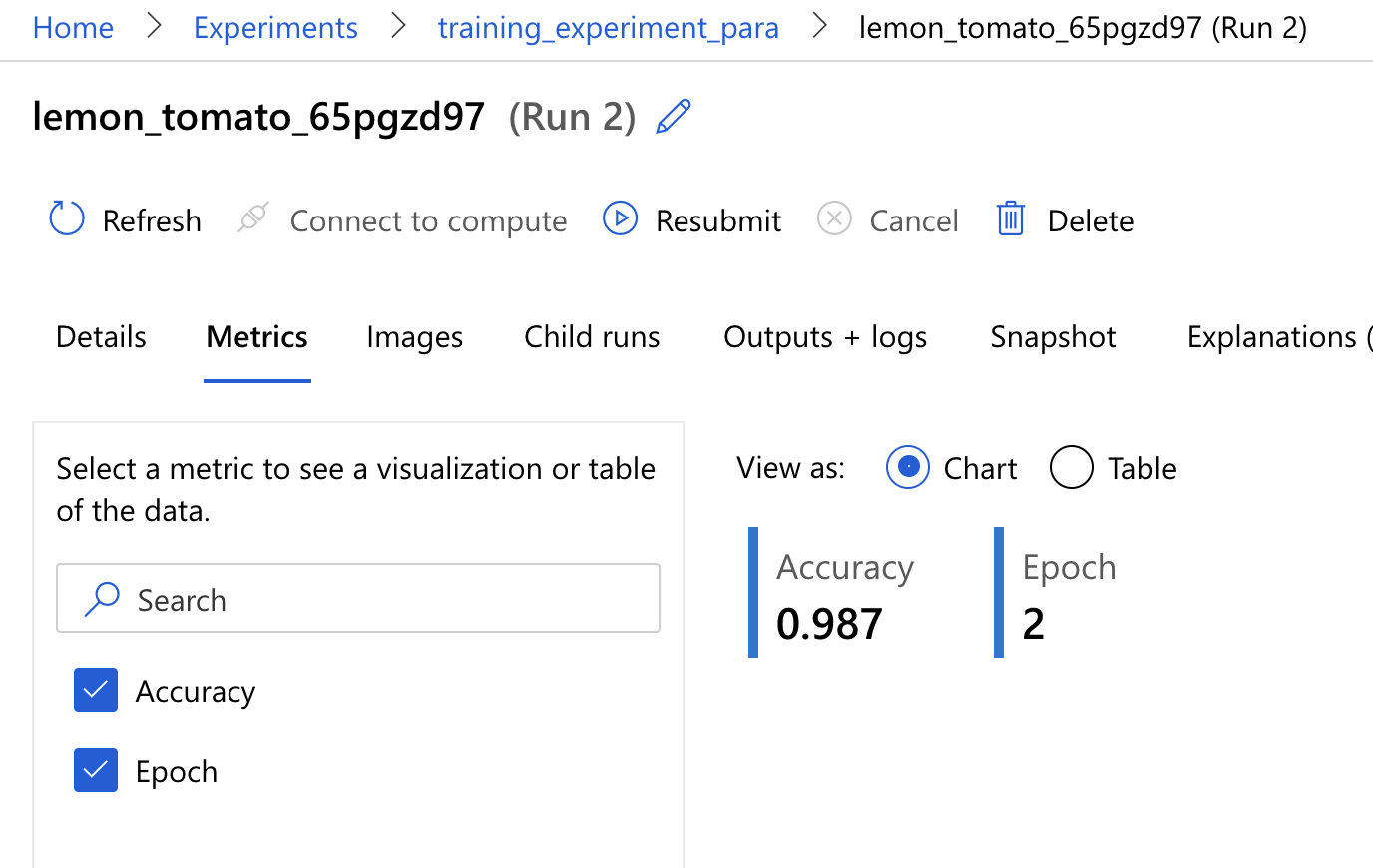
我们刚刚有做一个 log,去纪录下准确度,我们点进 Metrics 这个页签,可以看到 Accuracy 和 Epoch 的纪录了,真的只跑了两个 Epoch 呢!
以上就是今天的 ScriptRunConfig 啦!有没有觉得这个功能真的超好用的呢?
明天我们就来注册模型吧!
ps. 今天居然破6500了,程序码一多,内容就爆炸啊 QQ
<<: 【Day 25】 实作 - 启用 AWS WAF 日志
>>: Day24-介接 API(二)Google Calendar(II)Events——Read、Update、Delete
误用/滥用测试(Misuse/Abuse testing)
-HTTP请求(来源:Chua Hock-Chuan) 测试人员在HTTP请求中操纵URL的查询字...
Day 15 Matcher 基础三兄弟!
该文章同步发布於:我的部落格 今天会开始介绍许多好用的 Matcher 也就是配对仔,从开始到现在...
Day 20 架设开源的 CodiMD 服务
网路上的即时文件协作中,除了 Google Documents 系列外,HackMD 也走出了一条自...
Android x Kotlin : 简易实作第一堂-自定义customView与在xml中设定属性预设值
简介 在一个专案中,有时候会有一组view在很多地方都会用到,在每个地方都重刻一遍会很麻烦。这时候可...
Day29,使用Dex、OIDC为你的Kubernetes再上一道锁 (2/2)
正文 如果还没有看Day28的话,建议可以先回去看,不然接下来可能搞不清楚状况。 延续昨天的内容,我...