Day26 - 动态模型 part1 (LSTM)
动态模型我们会使用 LSTM-based 架构,并分成两种:
-
Basic LSTM
- Last-frame only
- Mean-pooling over time
- LSTM with attention
如 Day20 中提过的,动态模型的输入特徵为 32 维的特徵向量。Basic LSTM 中的 last-frame only 与 mean-pooling over time 使用的是相同的模型架构,差别在於 last-frame only 只取第二层 LSTM 最後一个时间点(timestamp)的输出输入至输出层;而 mean-pooling over time 则是对第二层 LSTM 所有时间点的输出做 mean-pooling 取平均後输入至输出层,此做法是希望藉由参考到LSTM所有时间点的输出来使网路能够学习到足够且情绪鲜明的资讯。架构如图 1。
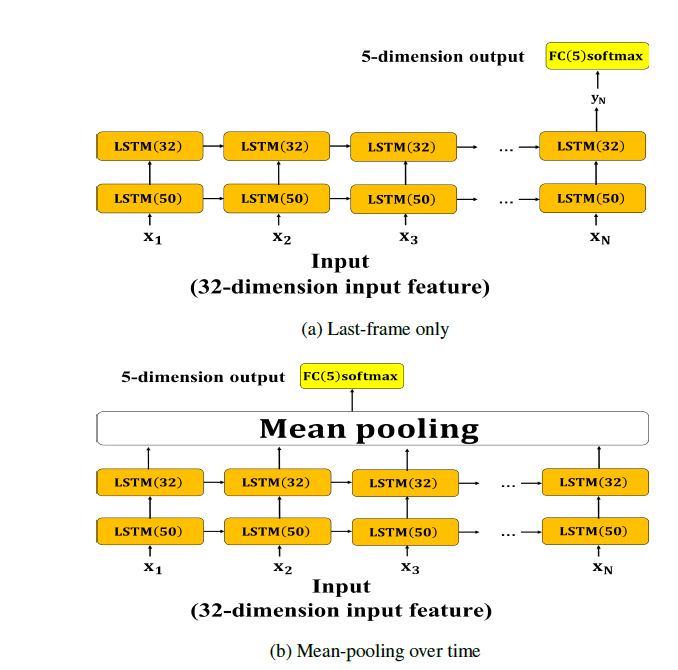
图 1: LSTM 动态模型架构图。两层 LSTM 使用的激活函数为 tanh、ReLU
两种架构的分类结果如表 1。
| Model | UA recall (tanh) | UA recall (ReLU) |
|---|---|---|
| Last-frame only | 37.0% | 20.0% |
| Mean-pooling over time | 40.6% | 20.0% |
表1: Basic LSTM 分类结果
在使用 keras 套件建构 LSTM 模型时直接使用 LSTM layer 就可以了,需要注意的地方在於如果是 last-frame only 的话最後一层的 LSTM layer return_sequences 这个参数要设成 False;mean-pooling over time 则是设为 True。
# last-frame only
dynamic_input = Input(shape=[max_length, args.dynamic_features], dtype='float32', name='dynamic_input')
lstm1 = LSTM(60, activation='tanh', return_sequences=True, recurrent_dropout=0.5, name='lstm1')(dynamic_input)
lstm2 = LSTM(60, activation='tanh', return_sequences=False, recurrent_dropout=0.5, name='lstm2')(lstm1)
output = Dense(args.classes, activation='softmax', name='output')(lstm2)
model = Model(inputs=dynamic_input, outputs=output)
model.summary()
# meal-pooling over time
dynamic_input = Input(shape=[max_length, args.dynamic_features], dtype='float32', name='dynamic_input')
lstm1 = LSTM(60, activation='tanh', return_sequences=True, recurrent_dropout=0.5, name='lstm1')(dynamic_input)
lstm2 = LSTM(60, activation='tanh', return_sequences=True, recurrent_dropout=0.5, name='lstm1')(lstm1)
mean = Lambda(lambda xin: K.mean(xin, axis=1))(lstm2)
output = Dense(args.classes, activation='softmax', name='output')(mean)
model = Model(inputs=dynamic_input, outputs=output)
model.summary()
另外因为资料集中几乎每一笔语音档长度都不会一样,为了输入到模型进行训练通常会使用 **padding (补值,一般是补 0)**的方式将所有语音档补成相同的长度,这部分可以使用 tf.keras.preprocessing.sequence.pad_sequences 这个 function 来达成。
从表中可以得知,不管是哪一种方法 basic LSTM 的效果都满差的,因此希望透过 attention 机制找出一段语音中情绪显着的部分来提升准确率。
>>: [Day24] Flutter with GetX Shimmer
day6 阿伯出事啦 exception
Coroutine支援kotlin一般的Exception处理 try/catch/finally,...
IT 铁人赛 k8s 入门30天 -- day15 k8s Workload 简介
前言 今天要讲的是 k8s 丛集对於 Workload 管理做讲解 Pod 的管理 以下将会解释一些...
[Day2] 何谓 LHS、RHS 错误?
今天来了解 JavaScrip 的 LHS 错误、RHS 错误,两者皆与取值、赋值有关,首先先来了解...
【Day 2】机器学习的种类
机器学习的种类主要分成四种:监督式学习(Supervised learning)、非监督式学习(Un...
Day29值的型态(JavaScript)
资料型态 我认为知道JS值的型态非常重要 因为要先能够判断他是甚麽变数类型的资料 才能进一步地做逻辑...