[神经机器翻译理论与实作] 从头建立英中文翻译器 (III)
前言
今天的内容依旧为训练翻译 seq2seq 神经网络的历程( training process )。
机器学习的两大阶段-训练(training)与推论(inference):
图片来源:www.intel.com

翻译器建立实作
建立资料集(续)
为了避免在稍後建立 numpy array 时耗掉所有的 RAM ( out of memory, OOM ),我们将资料量缩减为10000笔(资料瘦身之後 max_seq_length 、vocab_size 也会跟着改变):
# reduce size of seq_pairs
n_samples = 10000
seq_pairs = seq_pairs[:n_samples]
"""
Evaluating max_seq_length and vocab_size for both English and Chinese ...
Results are given as follows:
src_max_seq_length = 13
tgt_max_seq_length = 22
src_vocab_size == 3260 # 3260 unique tokens in total
tgt_vocab_size == 2504 # 2504 unique tokens in total
"""
我们之後会将经过断词之後的句子当作输入传入 seq2seq 模型并经过 word embedding 转为低维度的向量,因此不论是针对编码器或是解码器的输入句子(原型态为 string )我们都会进行 label encoding (将每个断开的单词赋予词汇表中的编号)。 由於翻译模型将每个经过 label encoding 的单词对应到目标词汇表中的某个单词,因此翻译任务本身可视为一个多类别的分类问题,而类别数量即是目标语言的单词总数( tgt_vocab_size )。我们很自然地将解码器的输出单词进行 one-hot 编码。
def encode_input_sequences(tokeniser, max_seq_length, sentences):
"""
Label encode every sentences to create features X
"""
# label encode every sentences
sentences_le = tokeniser.texts_to_sequences(sentences)
# pad sequences with zeros at the end
X = pad_sequences(sentences_le, maxlen = max_seq_length, padding = "post")
return X
def encode_output_labels(sequences, vocab_size):
"""
One-hot encode target sequences to create labels y
"""
y_list = []
for seq in sequences:
# one-hot encode each sentence
oh_encoded = to_categorical(seq, num_classes = vocab_size)
y_list.append(oh_encoded)
y = np.array(y_list, dtype = np.float32)
y = y.reshape(sequences.shape[0], sequences.shape[1], vocab_size)
return y
# create encoder inputs, decoder inputs and decoder outputs
enc_inputs = encode_input_sequences(src_tokeniser, src_max_seq_length, src_sentences) # shape: (n_samples, src_max_seq_length, 1)
dec_inputs = encode_input_sequences(tgt_tokeniser, tgt_max_seq_length, tgt_sentences) # shape: (n_samples, tgt_max_seq_length, 1)
dec_outputs = encode_input_sequences(tgt_tokeniser, tgt_max_seq_length, tgt_sentences)
dec_outputs = encode_output_labels(dec_outputs, tgt_vocab_size) # shape: (n_samples, tgt_max_seq_length, tgt_vocab_size )
Label Encoding为类别编号,产生一个纯量;One-Hot Encoding 则是对应该类别的维度为1,其余维度皆为0,产生一个n维向量(n为类别总数):
图片来源:medium.com

将建立好的特徵 enc_inputs 、 dec_inputs 以及标签 dec_outputs 连同来源语言(英文)的词汇总数 src_vocab_size 以上资讯一并存入同一份压缩 .npz 格式以便後续训练模型时可快速取用,并以其在现有程序中的变数名称当作引数名称(用以查找个别档案之关键字):
# save required data to a compressed file
np.savez_compressed("data/eng-cn_data.npz", enc_inputs = enc_inputs, dec_inputs = dec_inputs, dec_outputs = dec_outputs, src_vocab_size = src_vocab_size)
建立训练及测试资料
载入之前写入压缩档的合并训练资料,必且按照档案关键字还原个别的 Numpy arrays :
import numpy as np
data = np.load("data/eng-cn_data.npz")
print(data.files) # ['enc_inputs', 'dec_inputs', 'dec_outputs', 'src_vocab_size']
# Extract our desired data
enc_inputs = data["enc_inputs"]
dec_inputs = data["dec_inputs"]
dec_outputs = data["dec_outputs"]
src_vocab_size = data["src_vocab_size"].item(0)
注意此时的 enc_inputs 、 dec_inputs 和 dec_outputs 依旧是按照原始语料库中的前10000笔进行排列,我们建立 shuffler 并用它来打乱排列顺序,同时保留资料中每个句子的对应关系:
# shuffle X and y in unision
shuffler = np.random.permutation(enc_inputs.shape[0])
enc_inputs = enc_inputs[shuffler]
dec_inputs = dec_inputs[shuffler]
dec_outputs = dec_outputs[shuffler]
我们可以使用 sklearn.model_selection 模组当中定义的 train_test_split() 函式将资料依照指定的比例分割成训练资料以及测试资料,在此我们将原有资料的 20% 划为测试用资料:
from sklearn.model_selection import train_test_split
# prepare training and test data
test_ratio = .2
enc_inputs_train, enc_inputs_test = train_test_split(enc_inputs, test_size = test_ratio, shuffle = False)
dec_inputs_train, dec_inputs_test = train_test_split(dec_inputs, test_size = test_ratio, shuffle = False)
y_train, y_test = train_test_split(dec_outputs, test_size = test_ratio, shuffle = False)
X_train = [enc_inputs_train, dec_inputs_train]
X_test = [enc_inputs_test, dec_inputs_test]
准备好训练以及测试用的特徵以及标签之後,我们就可以来建立模型了。
建立附带注意力机制的LSTM Seq2Seq模型
从 enc_inputs 与 dec_outputs 的维度资讯可以得到中英文的最大序列长度(可理解为最大的句子长度)以及目标单词的词汇总数(这也是为什麽我们需要特别再存入 src_vocab_size ):
src_max_seq_length = enc_inputs.shape[1]
tgt_max_seq_length = dec_outputs.shape[1]
tgt_vocab_size = dec_outputs.shape[2]
指定英文和中文的 embedding 维度以及 LSTM 内部状态向量的维度等超参数,我们可由以上超参数以及中、英文最大序列长度和英文词汇总数 src_vocab_size 来建立一个附带 Luong attention 机制双层 LSTM seq2seq 神经网络。自定函式build_seq2seq()将建立神经网络之外,紧接着指定衡量预测值与实际值之间误差的损失函数(由於输出值 dec_outputs 为 one-hot 编码向量,我们指定损失函数为适用於多类别分类问题的 CategoricalCrossentropy()) 并定义找寻损失函数最小值使用的梯度下降演算法为 Adam ,指定其学习率( learning rate,其也是可 fine-tune 的超参数之一)。
# hyperparameters
src_wordEmbed_dim = 96
tgt_wordEmbed_dim = 100
latent_dim = 256
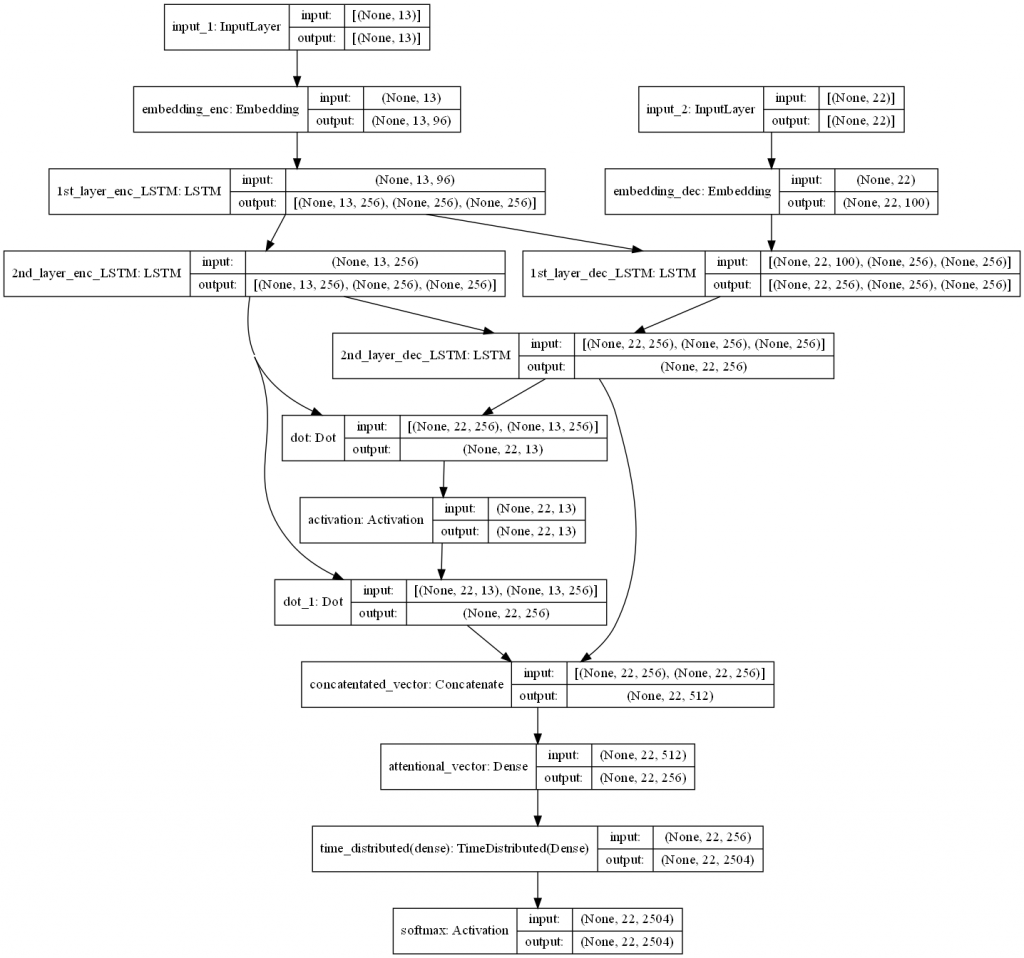
def build_seq2seq(src_max_seq_length, src_vocab_size, src_wordEmbed_dim, tgt_max_seq_length, tgt_vocab_size, tgt_wordEmbed_dim, latent_dim, model_name = None):
"""
Builda an LSTM seq2seq model with Luong attention
"""
# Build an encoder
enc_inputs = Input(shape = (src_max_seq_length, ))
vectors = Embedding(input_dim = src_vocab_size, output_dim = src_wordEmbed_dim, name = "embedding_enc")(enc_inputs)
enc_outputs_1, enc_h1, enc_c1 = LSTM(latent_dim, return_sequences = True, return_state = True, name = "1st_layer_enc_LSTM")(vectors)
enc_outputs_2, enc_h2, enc_c2 = LSTM(latent_dim, return_sequences = True, return_state = True, name = "2nd_layer_enc_LSTM")(enc_outputs_1)
enc_states = [enc_h1, enc_c1, enc_h2, enc_h2]
# Build a decoder
dec_inputs = Input(shape = (tgt_max_seq_length, ))
vectors = Embedding(input_dim = tgt_vocab_size, output_dim = tgt_wordEmbed_dim, name = "embedding_dec")(dec_inputs)
dec_outputs_1, dec_h1, dec_c1 = LSTM(latent_dim, return_sequences = True, return_state = True, name = "1st_layer_dec_LSTM")(vectors, initial_state = [enc_h1, enc_c1])
dec_outputs_2 = LSTM(latent_dim, return_sequences = True, return_state = False, name = "2nd_layer_dec_LSTM")(dec_outputs_1, initial_state = [enc_h2, enc_c2])
# evaluate attention score
attention_scores = dot([dec_outputs_2, enc_outputs_2], axes = [2, 2])
attenton_weights = Activation("softmax")(attention_scores)
context_vec = dot([attenton_weights, enc_outputs_2], axes = [2, 1])
ht_context_vec = concatenate([context_vec, dec_outputs_2], name = "concatentated_vector")
attention_vec = Dense(latent_dim, use_bias = False, activation = "tanh", name = "attentional_vector")(ht_context_vec)
logits = TimeDistributed(Dense(tgt_vocab_size))(attention_vec)
dec_outputs_final = Activation("softmax", name = "softmax")(logits)
# integrate as a model
model = Model([enc_inputs, dec_inputs], dec_outputs_final, name = model_name)
# compile model
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate = 1e-3),
loss = tf.keras.losses.CategoricalCrossentropy(),
)
return model
# build our seq2seq model
eng_cn_translator = build_seq2seq(
src_max_seq_length = src_max_seq_length,
src_vocab_size = src_vocab_size,
src_wordEmbed_dim = src_wordEmbed_dim,
tgt_max_seq_length = tgt_max_seq_length,
tgt_vocab_size = tgt_vocab_size,
tgt_wordEmbed_dim = tgt_wordEmbed_dim,
latent_dim = latent_dim,
model_name = "eng-cn_translator_v1"
)
eng_cn_translator.summary()
模型中可经过反向传播( backpropagation, BP )进行学习的参数有3,115,624个,构成了决定此模型的所有参数:

检查模型架构中各层神经元输入与输出的维度是否正确:
模型学习
我们希望记录训练过程中的模型权重( model weights )变化以及模型本身(以 .h5 格式呈现),加入了 tf.keras.callbacks.ModelCheckpoint 物件。如此之外,我们也希望在训练过程中若是误差(损失函数)超过10个训练期依旧持续停止下降即中止模型训练,引入 tf.keras.callbacks.EarlyStopping 物件。我们将让模型学习训练资料X_train = [enc_inputs_train, dec_inputs_train]和y_train,并且取其中的 20% 当作验证资料:
# save model and its weights at a certain frequency
ckpt = ModelCheckpoint(
filepath = "models/eng-cn_translator_v1.h5",
monitor = "val_loss",
verbose = 1,
save_best_only = True,
save_weights_only = False,
save_freq = "epoch",
mode = "min",
)
es = EarlyStopping(
monitor = "loss",
mode = "min",
patience = 10
)
# train model
train_hist = eng_cn_translator.fit(
X_train,
y_train,
batch_size = 64,
epochs = 200,
validation_split = .2,
verbose = 2,
callbacks = [es, ckpt]
)
# preview training history
print("training history have info: {}".format(train_hist.history.keys())) # ['loss', 'val_loss']
fig, ax = plt.subplots(figsize = (10, 5))
fig.suptitle("Eng-Cn NMT Model")
ax.set_title("Cross Entropy Loss")
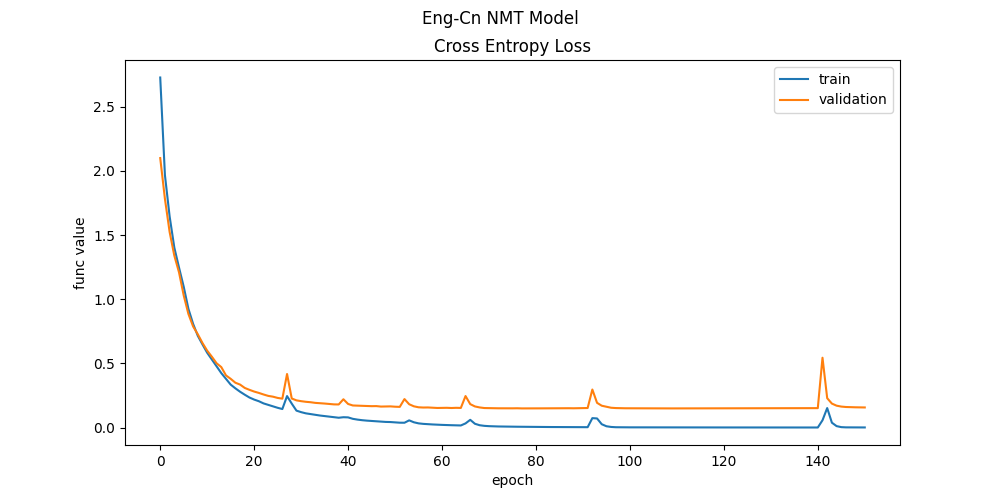
ax.plot(train_hist.history["loss"], label = "train")
ax.plot(train_hist.history["val_loss"], label = "validation")
ax.set_xlabel("epoch")
ax.set_ylabel("func value")
ax.legend()
plt.show()
经过了200个 epochs (一个 epoch 为一次 feed forward 得到输出加上一次 back propagation 更新参数),我们可以观察模型在训练资料集上与验证资料集上误差的递减:
训练好之後即回顾训练中每个时期( epoch )中损失函数下降变化:
结语
模型训练好了,下一步就是评估模型好坏的时刻。我们将透过计算模型在语料库中的 BLEU (bilingual evaluation understudy) 得分来衡量此 seq2seq 模型的翻译品质。今天的实作进度就到此告一段落,bis morgen und gute Nacht!
阅读更多
>>: Day22:终於要进去新手村了-Javascript-函式-概念
[ 卡卡 DAY 15 ] - React Native 页面导览 Navigation (下)
接下来要在页面上按下按钮跳页 以及按了左边 header icon 回上一页 正所谓有去有回才不会...
Day 02 什麽是关键字广告?
昨天聊到在搜寻引擎输入字词触发进而触发关键字广告,有些人可能会好奇,这些广告是以什麽形式出现呢? 这...
Day04 测试写起乃 - 撰写Rspec
在上一篇我们已经安装好 rspec 也产出了 User model 接下来就开始尝试写测试搂! 我在...
[Day 14] 更换连线的资料库,聊 Database.connect 的操作
之前我们连线的,一直都是测试用的资料库。 今天我们来练线 MySQL 资料库来进行操作。 连线MyS...
Day25:看看猪走路
在初学Java的时候,常常会有以下的输入输出范例出现: Scanner sc = new Scann...