Day 23 Selenium模组二
今天的影片内容为介绍selenium的webdriver物件用来寻找网页元素的方法
其实跟BeautifulSoup模组中find()以及find_all()是差不多的呦~
有了前面的基础一定很快就能学会!
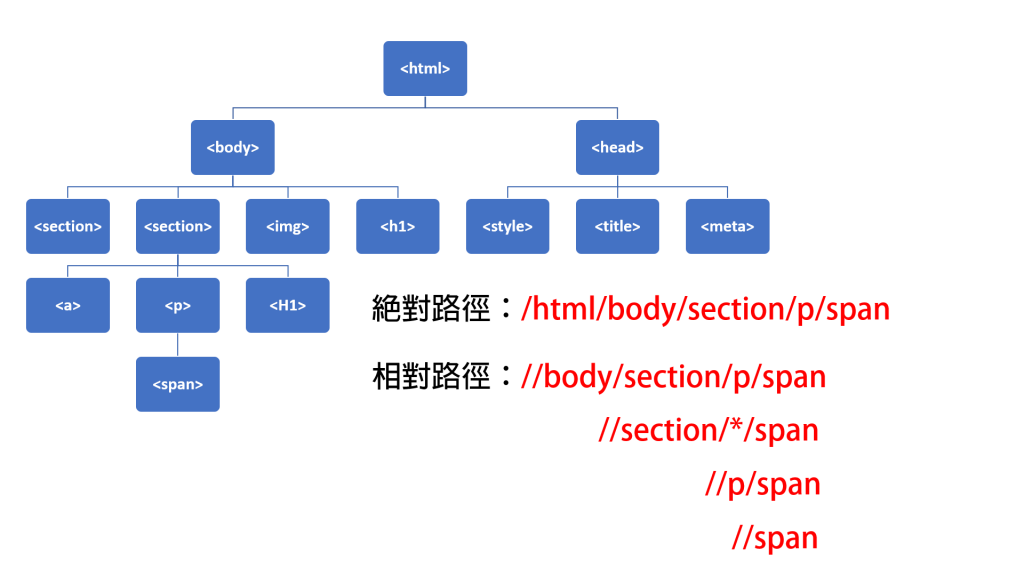
以下为绝对路径与相对路径的概念图
以下为ChroPath的连结
https://chrome.google.com/webstore/detail/chropath/ljngjbnaijcbncmcnjfhigebomdlkcjo/related
以下为影片中有使用到的程序码
<!doctype html>
<!-- 请将此档案储存成bs4_HTML.html -->
<html lang="zh-tw">
<head>
<meta charset="utf-8">
<title>水母</title>
<style>
section.section1 {background-color:#AAFFEE;} /*薄荷绿*/
h1#title {background-color:#CCCCFF;} /*淡紫色*/
h1#content1 {color:#227700;} /*深绿色*/
h1#content2 {color:#7700BB;} /*深紫色*/
span {color:red;}
</style>
</head>
<body>
<h1 id="title">水母的天敌</h1>
<img src="DSC_0394.jpg" alt="於海生馆拍摄的水母" height="300" width="450">
<section class="section1">
<h1 id="content1">海龟</h1>
<p>捕食水母为生,海龟除了<span>眼睛</span>外,身体其他部分都可以抵抗水母的毒性,牠们在捕食水母时会闭上眼睛。</p>
<a href="https://zh.wikipedia.org/wiki/%E6%B5%B7%E9%BE%9F">维基百科海龟连结</a>
</section>
<section class="section1">
<h1 id="content2">紫螺</h1>
<p>分布在热带太平洋温暖的水域,爱吃漂浮在水面的水母。</p>
<a href="https://zh.wikipedia.org/wiki/%E7%B4%AB%E8%9E%BA">维基百科紫螺连结</a>
</section>
</body>
</html>
#开启电脑中的档案
#请将C:\\spider\\修改为chromedriver.exe在您电脑中的路径
#请将C:\\Users\\ASUS\\Desktop\\bs4_HTML\\修改为bs4_HTML.html在您电脑中的路径
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'C:\\Users\\ASUS\\Desktop\\bs4_HTML\\bs4_HTML.html'
browser.get(url)
print('浏览器名称:', browser.name)
print('网页网址:', browser.current_url)
print('网页标题:', browser.title)
print('网页原始码:\n', browser.page_source)
#find_element(s)_by_XX
#请将C:\\spider\\修改为chromedriver.exe在您电脑中的路径
#请将C:\\Users\\ASUS\\Desktop\\bs4_HTML\\修改为bs4_HTML.html在您电脑中的路径
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'C:\\Users\\ASUS\\Desktop\\bs4_HTML\\bs4_HTML.html'
browser.get(url)
tag_1 = browser.find_element_by_id('title') #回传第一个id相符的元素
print("回传第一个id为title的元素内容:\n", tag_1.text)
print("="*100)
tag_2 = browser.find_element_by_class_name('section1') #回传第一个相符class的元素
print("回传第一个class为section1的元素内容:\n", tag_2.text)
tag_3 = browser.find_elements_by_class_name('section1') #回传所有相符class的元素,以串列传回
print("回传所有class为section1的元素内容:\n", tag_3)
for tag in tag_3:
print(tag.text)
print("="*100)
tag_4 = browser.find_element_by_css_selector('h1') #回传第一个相符CSS选择器的元素
print("回传第一个CSS选择器为h1的元素内容:\n", tag_4.text)
tag_5 = browser.find_elements_by_css_selector('h1') #回传所有相符的CSS选择器的元素,以串列传回
print("回传所有CSS选择器为h1的元素内容:")
for tag in tag_5:
print(tag.text)
#find_element(s)_by_XX
#请将C:\\spider\\修改为chromedriver.exe在您电脑中的路径
#请将C:\\Users\\ASUS\\Desktop\\bs4_HTML\\修改为bs4_HTML.html在您电脑中的路径
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'C:\\Users\\ASUS\\Desktop\\bs4_HTML\\bs4_HTML.html'
browser.get(url)
tag_6 = browser.find_element_by_partial_link_text('海龟') #回传第一个含有XX内容的<a>元素
print("回传第一个含有「海龟」内容的<a>元素内容:\n", tag_6.text)
tag_7 = browser.find_elements_by_partial_link_text('维基百科') #回传所有含有XX内容的<a>元素
print("回传所有含有「维基百科」内容的<a>元素内容:")
for tag in tag_7:
print(tag.text)
print("="*100)
tag_8 = browser.find_element_by_link_text('维基百科海龟连结') #回传第一个含有XX内容的<a>元素(要完全相符)
print("回传第一个含有「维基百科海龟连结」内容的<a>元素内容:\n", tag_8.text)
tag_9 = browser.find_elements_by_link_text('维基百科海龟连结') #回传所有含有XX内容的<a>元素(要完全相符)
print("回传所有含有「维基百科海龟连结」内容的<a>元素内容:")
for tag in tag_9:
print(tag.text)
print("="*100)
tag_10 = browser.find_element_by_tag_name('span') #回传第一个相符的元素(不区分大小写)
print("回传第一个<span>元素的内容:\n", tag_10.text)
tag_11 = browser.find_elements_by_tag_name('p') #回传所有相符的元素(不区分大小写)
print("回传所有<p>元素的内容:")
for tag in tag_11:
print(tag.text)
#XPath
#请将C:\\spider\\修改为chromedriver.exe在您电脑中的路径
#请将C:\\Users\\ASUS\\Desktop\\bs4_HTML\\修改为bs4_HTML.html在您电脑中的路径
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'C:\\Users\\ASUS\\Desktop\\bs4_HTML\\bs4_HTML.html'
browser.get(url)
X_1 = browser.find_element_by_xpath('/html/body/section/p/span')
print(X_1.text)
print("="*100)
X_2 = browser.find_element_by_xpath('//body/section/p/span')
print(X_2.text)
print("="*100)
X_3 = browser.find_element_by_xpath('//section/*/span')
print(X_3.text)
print("="*100)
X_4 = browser.find_element_by_xpath('//p/span')
print(X_4.text)
print("="*100)
X_5 = browser.find_element_by_xpath('//span')
print(X_5.text)
#XPath
#请将C:\\spider\\修改为chromedriver.exe在您电脑中的路径
#请将C:\\Users\\ASUS\\Desktop\\bs4_HTML\\修改为bs4_HTML.html在您电脑中的路径
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'C:\\Users\\ASUS\\Desktop\\bs4_HTML\\bs4_HTML.html'
browser.get(url)
X_1 = browser.find_element_by_xpath('//section')
print(X_1.text)
print("="*100)
X_2 = browser.find_element_by_xpath('//section[1]')
print(X_1.text)
print("="*100)
X_3 = browser.find_element_by_xpath('//section[2]')
print(X_3.text)
#利用XPath寻找台彩网页双赢彩区块
#请将C:\\spider\\修改为chromedriver.exe在您电脑中的路径
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'https://www.taiwanlottery.com.tw/index_new.aspx'
browser.get(url)
XPath = browser.find_element_by_xpath("//body/form[@id='form1']/div[@id='wrapper_overflow']/div[@id='rightdown']/div[3]")
print(XPath.text)
本篇影片及程序码仅提供研究使用,请勿大量恶意地爬取资料造成对方网页的负担呦!
如果在影片中有说得不太清楚或错误的地方,欢迎留言告诉我,谢谢您的指教。
<<: D3JsDay22给我两个以上的变数,给你呈现资料的散布—散布图
>>: [Day 24 - Modern CSS] 在JS中写CSS,神套件Styled-components
03 | 认识 WordPress「区块编辑器」的发展和简介
关於 Block Editor(区块编辑器)的各类延伸有很多,我们这篇文章尽量保持简单,但您可以从...
React和DOM的那些事-节点更新
点击进入React源码调试仓库。 React的更新最终要落实到页面上,所以本文主要讲解DOM节点(H...
【第二六天 - Flutter 知名外送平台画面练习(中)】
前言 接续上一篇 【第二五天 - Flutter 知名外送平台画面练习(上)】~~。 今日的程序码 ...
Day3: Big O — 时间复杂度与空间复杂度
每一种题目可能有数种的解法,那我们应该怎麽评估每种解法的优劣呢?以前的我应该会回答,当然是越简短的...
Day6 - 读 Concurrency is not Parallelism - Rob Pike (一)
本篇是看 Concurrency is not Parallelism 的心得 Concurrenc...