爬虫怎麽爬 从零开始的爬虫自学 DAY22 python网路爬虫开爬-4翻页继续爬
前言
各位早安,书接上回我们学会透过发送 cookie 来绕过18岁守门员,今天我们要学习如何翻页继续爬
开爬-翻页
在这里的大家一定都很有爱心 所以今天的目标是PTT的宠物领养版
我们要看更多页才能找到适合我们的领养对象 所以今天来实作翻页功能
首先打开PTT的宠物领养版网页 按下 F12
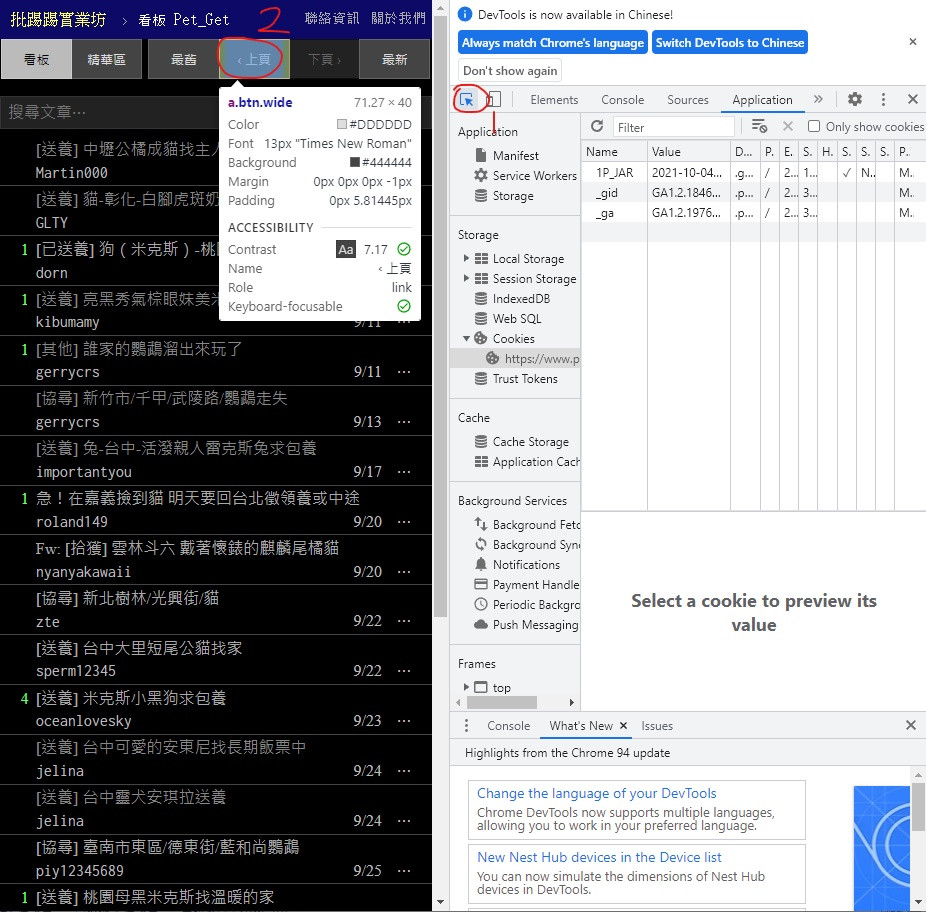
照着标示顺序按
1号位置是按了之後点网页的内容就会带你去找他的原始码部分
可以看到
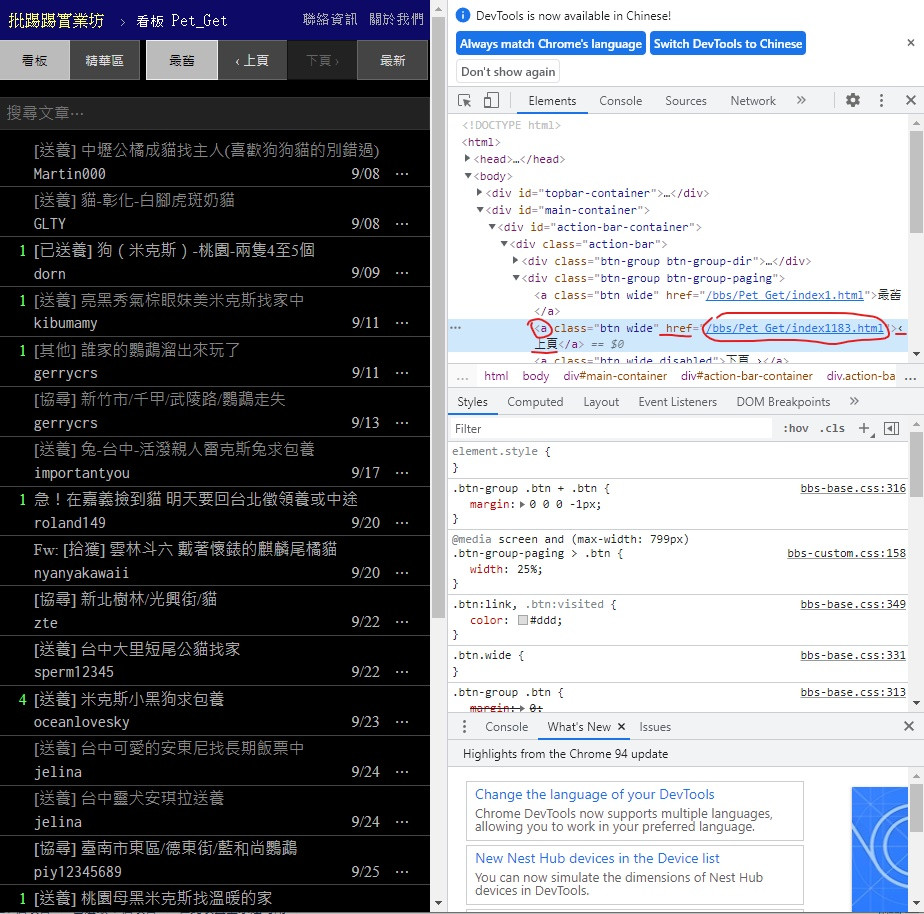
标签为 < a > class = "btn wide" 文字则是 ‹ 上页
href 後面的则是 url 也就是我们要的上一页连结
接着左键双击 ‹ 上页 的部分复制它
其他部分也可以用一样方式复制 贴到程序码内
在下面加上
prePage = data.find("a", class_ = "btn wide", text = "‹ 上页")
newUrl = prePage["href"]
print("https://www.ptt.cc"+newUrl)
先建立 prePage 存放抓到的资讯 指定的逻辑刚刚已经有展示怎麽找到的
建立 newUrl 用来存放我们的目标 也就是 href 的连结部分
但注意这个连结并不完整 观察原本网址缺啥後加进去
最後印出来
执行看看
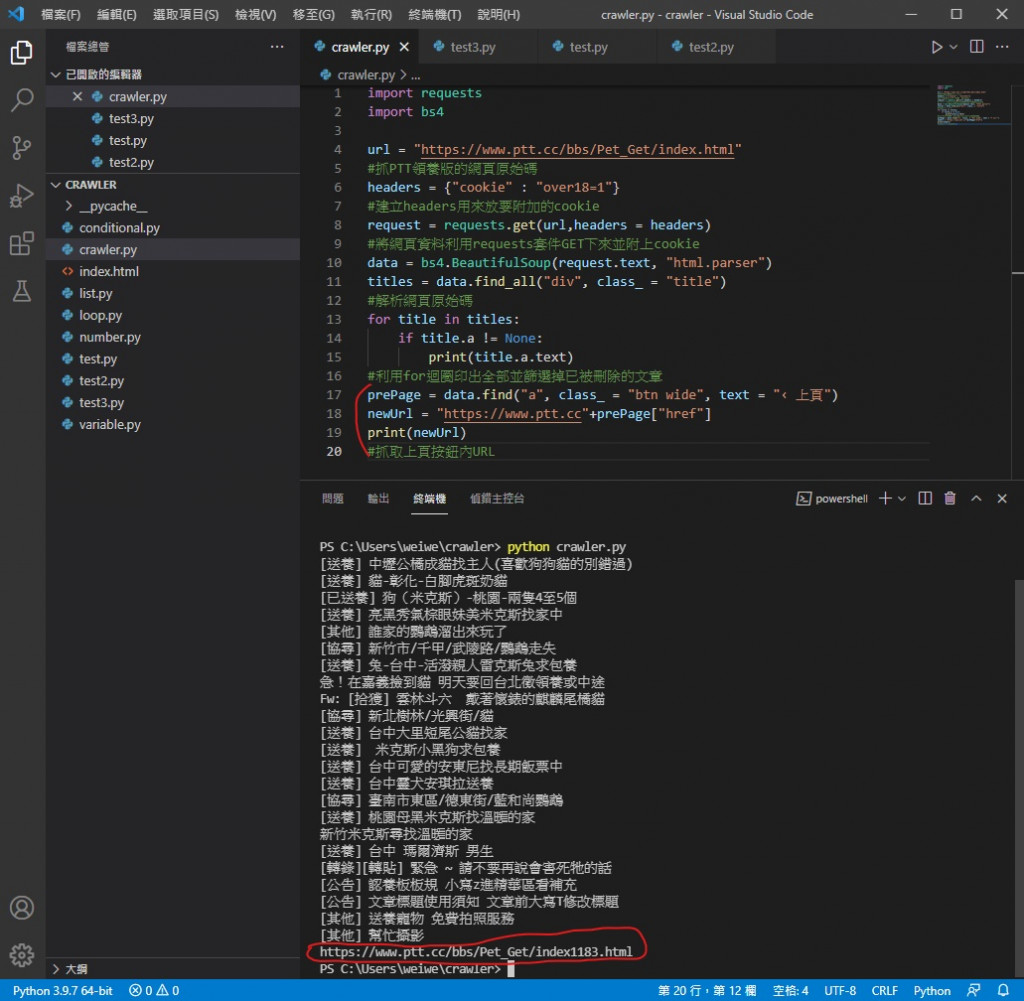
可以看到 newUrl 已经是下一页的完整网址了
目前程序码
mport requests
import bs4
url = "https://www.ptt.cc/bbs/Pet_Get/index.html"
#抓PTT领养版的网页原始码
headers = {"cookie" : "over18=1"}
#建立headers用来放要附加的cookie
request = requests.get(url,headers = headers)
#将网页资料利用requests套件GET下来并附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析网页原始码
for title in titles:
if title.a != None:
print(title.a.text)
#利用for回圈印出全部并筛选掉已被删除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上页")
newUrl = "https://www.ptt.cc"+prePage["href"]
print(newUrl)
#抓取上页按钮内URL
那得到这个网址能干嘛
答案是可以套入上面的程序码再跑一次 就能获得另一页的内容
那我们难道要把上面得程序码全部复制贴上一次吗
不用 只要把我们刚刚写出来的程序码定义成函式就可以再次叫出来用
被定义完的函式只要呼叫到它便会执行一次里面的程序码
利用这个特性便可以多次进行爬取的动作
作法如下
把 url 变数移到最下面
在空出来的位置打上 def getData(url): 意思是定义函式 getData 用到它时要传给它 url
接着把底下的功能全选 (不包括 url 变数的建立) 并按下 TAB 进行缩排
使其归到 def getData(url): 的里面
最後加上
return newUrl 用来回传 newUrl 出去 并删掉多余的 print(newUrl)
改完的程序码
import requests
import bs4
def getData(url):
headers = {"cookie" : "over18=1"}
#建立headers用来放要附加的cookie
request = requests.get(url,headers = headers)
#将网页资料利用requests套件GET下来并附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析网页原始码
for title in titles:
if title.a != None:
print(title.a.text)
#利用for回圈印出全部并筛选掉已被删除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上页")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上页按钮内URL
return newUrl
#回传newUrl出去
url = "https://www.ptt.cc/bbs/Pet_Get/index.html"
#抓PTT领养版的网页原始码
print(getData(url))
实际执行情况
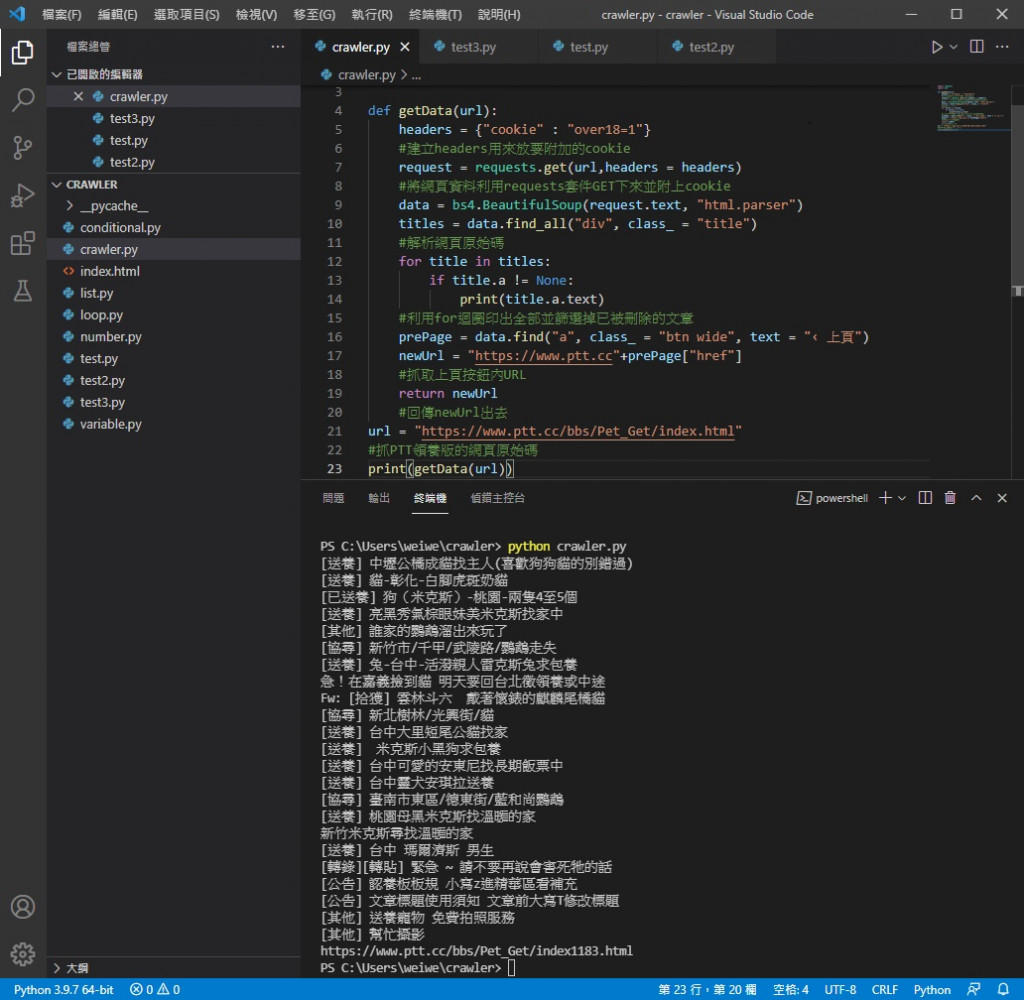
可以看到改完没问题
接下来如何利用它翻页呢
很简单 加一个回圈
把 print(getData(url)) 删掉
改成
for i in range(1,4,1):
url = getData(url)
假设要爬三页 设定回圈三次 (想爬更多次就改回圈次数)
这里的 getData(url) 就是最後 return 出来的 newUrl
把回传的 newUrl 放进 url 变数里进行下一次回圈
实际执行看看
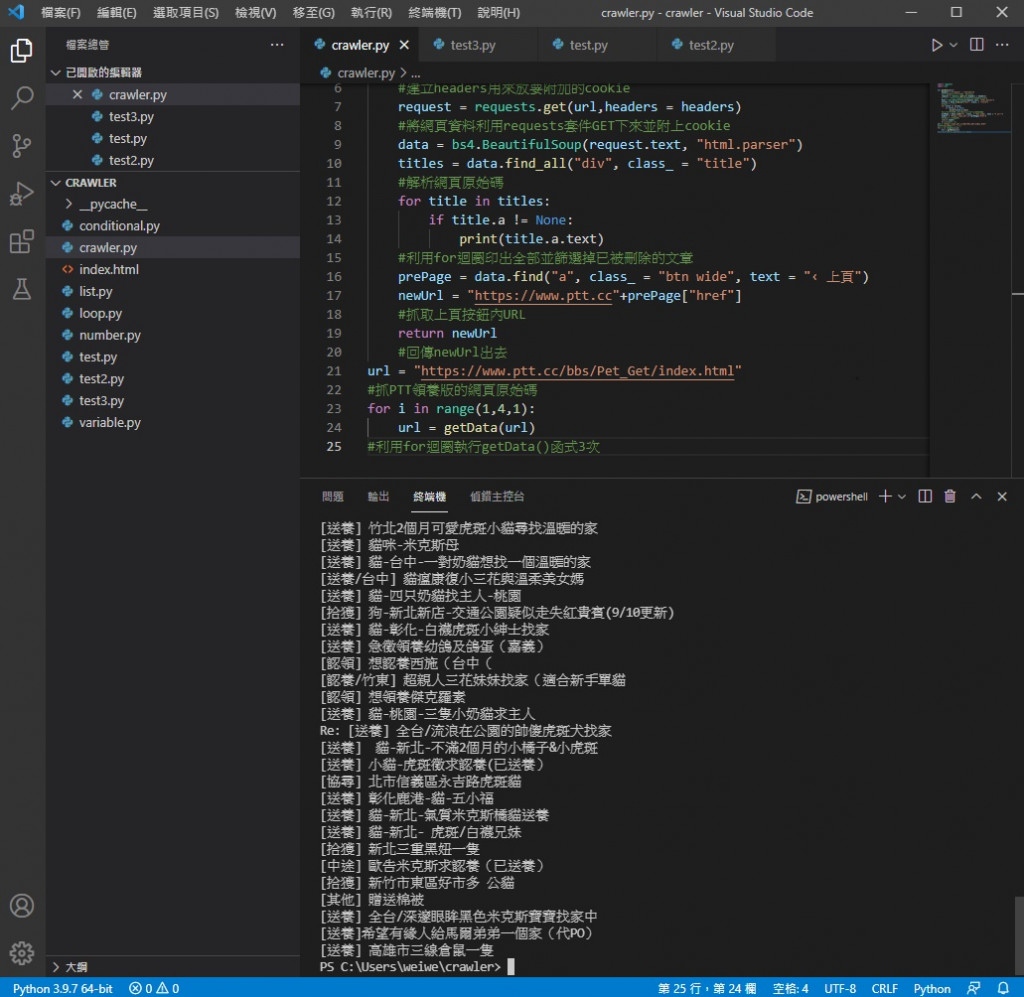
可以看到是三页的标题量 执行时应该会顿两下
原因是每次执行 getData( ) 都是重新对网站进行连线及抓取
所以才会有回应时间
今天我们成功翻页了 看到更多页就有更大机会找到适合领养的动物
明天我们要来小小优化一下这只程序 让它更方便使用
参考资料
https://www.youtube.com/watch?v=BEA7F9ExiPY&list=PL-g0fdC5RMboYEyt6QS2iLb_1m7QcgfHk&index=21
早安闲聊区
你知道吗?
我们的记忆其实也经过大脑的後制喔
每日二选一
你还相信自己的记忆吗还是不愿再被大脑骗了呢
Day11:【TypeScript 学起来】只有 TS 才有的型别 : Union Types(联合型别) / Intersection types (交集型别)
四个工程师一起坐上了车,发现车子发不动了。 机械工程师说: 看来是引擎出问题了。 电机工程师说: ...
【Day 21】Go 基础小笔记 II(pointer / array / slice / map / struct)
笔记会纪录与已知的 Python 的差别, 或是对我来说比较需要记忆的部分。 初学 Go 不建议看这...
[Day23] Array methods 阵列操作方法(1)
前面在讲物件型别的时候只稍微谈到阵列,而其实阵列包含很多种 methods 可以运用,这篇要来练习阵...
Angular 深入浅出三十天:表单与测试 Day24 - Reactive Forms 进阶技巧 - Auto-Complete Searching
在日常生活中,大家应该满常看到有些系统的搜寻输入框是可以在一边打字的同时,一边将搜寻结果呈现在一个...
[Day 25] BDD - godog image封装
封装 由於之後我打算将godog在CI/CD工具上定期跑BDD测试,所以我想要将godog封装在im...