爬虫怎麽爬 从零开始的爬虫自学 DAY21 python网路爬虫开爬-3我已满18岁(cookie)
前言
各位早安,书接上回我们已经能够成功抓到整页的文章标题了,今天我们要来破解 PTT 某些版上的是否已满18岁页面了
开爬-我已满18岁
各位一定很想知道最近的时事八卦吧
但是进入八卦版时会跳出是否已满18岁的问题
今天我们就要来克服它
要看八卦版首先我们把网址改成八卦版的网址
去复制回来贴上就好
可以看到换成八卦版的网址了
但是奇怪 怎麽啥都没有
公布答案 答案是被这家伙

给挡住了
你如果去看它的原始码 就会发现

根本没有啥 < div class="title" > 可以给你抓 当然抓不到任何东西
所以我们要想办法处理掉这家伙 才能爬取八卦版上的东西
所以我们要来观察它 按下 F12 就会开启开发人员工具
找到 Application
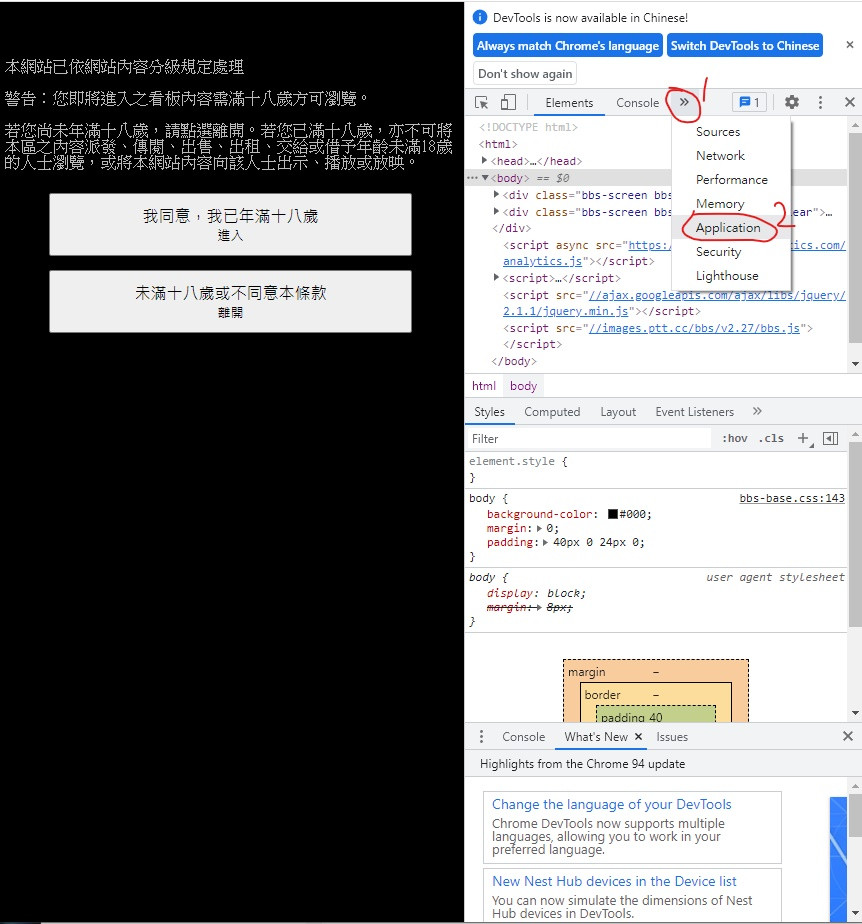
按下去
就会看到
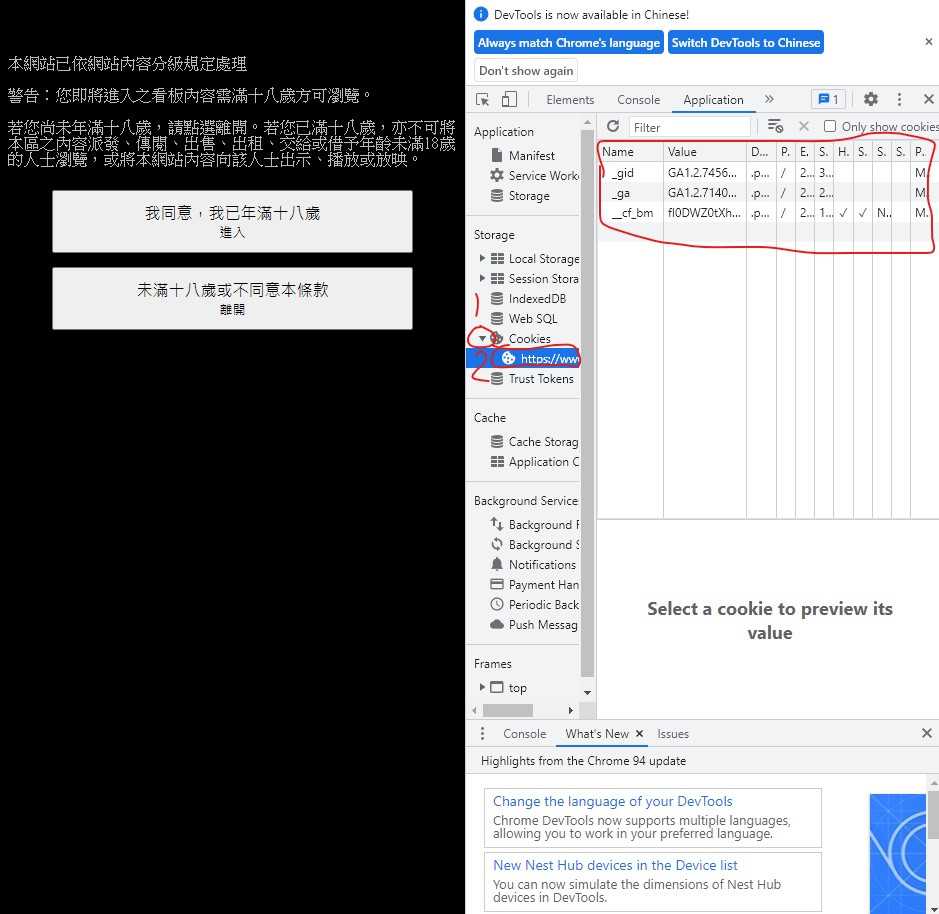
按 Cookie 旁的小箭头再按下面那个
仔细盯着这区看
接着按下 我同意,我已年满十八岁 (没满18的就当作为了学习牺牲吧)
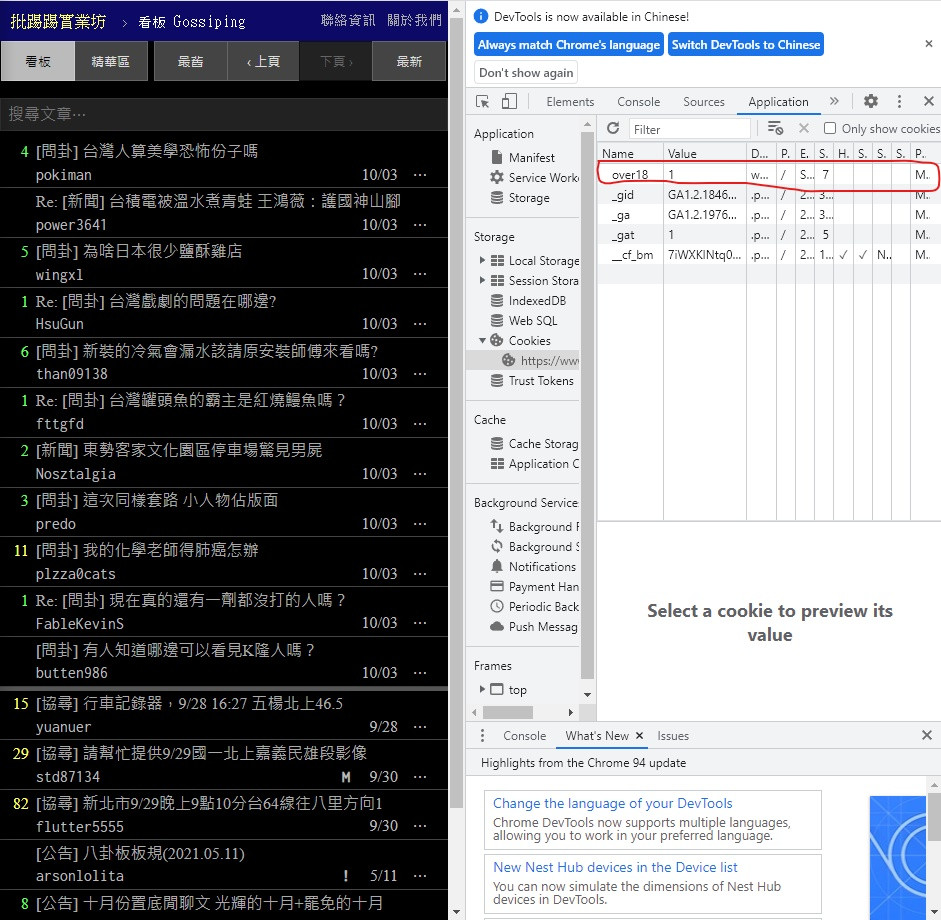
你会发现里面多出了一个 over18 它的 Value (值)是 1
那根据判断 它应该就是我们今天的主角了
这时候你重新整理会发现没有再跳出一次18岁确认
这便是因为你的浏览器里存的 Cookie 告诉网站你已经确认过了
所以只要我们的程序里也送出这个 Cookie 便可以达到直接进入八卦板内爬取资讯的目的了
首先建立一个变数 headers
headers 是啥呢 就是我们浏览器传给网站的资料
在里面放入要附加的 cookie 资讯 over18=1
headers = {"cookie" : "over18=1"}
接下来利用 requests.get() 的功能将 headers 一并传过去
request = requests.get(url,headers = headers)
结果如下
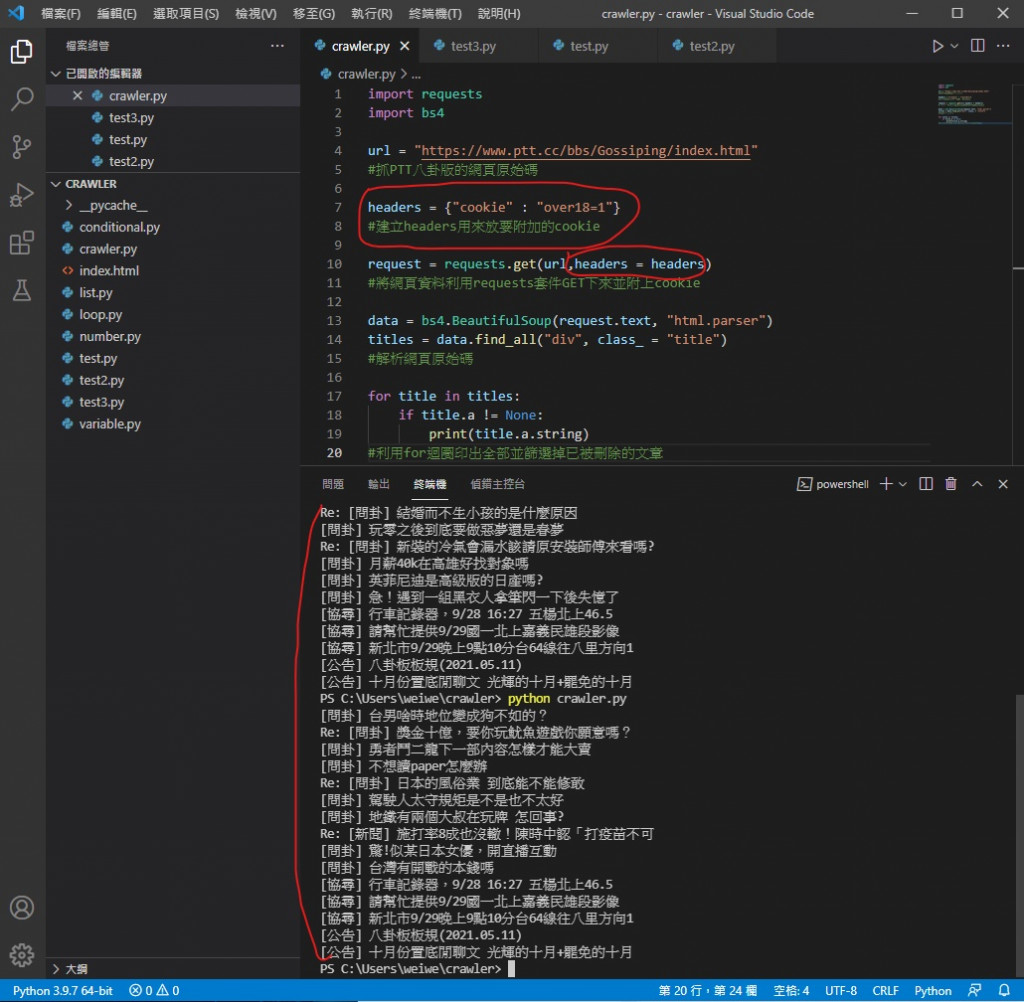
终於绕过18岁守门员成功抓到网页资讯了
今天的程序码
import requests
import bs4
url = "https://www.ptt.cc/bbs/Gossiping/index.html"
#抓PTT八卦版的网页原始码
headers = {"cookie" : "over18=1"}
#建立headers用来放要附加的cookie
request = requests.get(url,headers = headers)
#将网页资料利用requests套件GET下来并附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析网页原始码
for title in titles:
if title.a != None:
print(title.a.string)
#利用for回圈印出全部并筛选掉已被删除的文章
今天我们藉由打败18岁守门员学习到附加 cookie 的方法
明天我们会学其他东东 敬请期待
参考资料:
https://www.youtube.com/watch?v=BEA7F9ExiPY&list=PL-g0fdC5RMboYEyt6QS2iLb_1m7QcgfHk&index=20
https://ithelp.ithome.com.tw/articles/10220161
早安闲聊区
你知道吗?
我们眼睛看到的世界其实都经过大脑的後制喔
每日二选一
你还相信眼见为凭吗还是不想再被脑袋戏耍了呢
Day 09 Create a Clustering Model with Azure Machine Learning designer
Clustering - Group similar items into clusters(bas...
EP 29 - [TDD] 订单交易查询
Youtube 频道:https://www.youtube.com/c/kaochenlong ...
【LeetCode】Binary Tree
大部分会碰到的是 Binary Tree 和 Binary Search Tree。 常见错误:nu...
Day31 参加职训(机器学习与资料分析工程师培训班),tf.keras & Pytorch
早上: Python机器学习套件与资料分析 今天也是练习CNN import os import c...
Day 20 - 规划各功能模组的介面
紧接着今天我们要来规划各个功能模组的介面了! 首先是登入後的首页,会陈列使用者上传记帐资讯,包含图片...