[Day 20] 两段式训练比两段式左转更安全 (迁移学习技巧)
前言
走过了资料分析、演算法选择後,
我们得知了有些可以改善模型的方向:
- 解决资料不平衡(Done)
- 学习率的设定(Done)
- 训练轮数(Nice to have)
- 模型深度(No, I want my model to be more efficient ! )
- 阶段式训练(Now)
训练轮数(epoch)
这边我做实验都是为了比较不同方法带给模型的提升,
而并非追求最佳模型,
所以在未来我的最终训练轮数绝对会远远超过30,
很有可能落在100到300之间,
这样我要跑一个模型就要3小时以上,
抱歉我只能说我不OK,你先train。
如果大家真的想不开要去找最佳epoch,
建议大家使用Google Colab完成。
(如果资料量很大,建议不要忍一下,直接买Pro方案)
迁移学习
在传统的机器学习领域,我们获得训练资料和标签,
训练一下就可以获得还不错的模型。
但在现今深度学习领域,我们拥有巨量的训练资料,
可惜的是标签并没有办法也这麽大量。
那怎麽办呢?
那就是Transfer Learning!
机器学习的困境
有学过一点统计的人,
应该听过分布相同假设,
或更常听到的是「我们假设这两个随机变数都来自常态分布,所以我们可以推导出...」,
很多传统机器学习方法本质上就是统计方法。
那些方法会需要在训练资料和测试资料相同分布的前提下才能使用。
如果分布不同,则应用在测试资料时会凄惨无比。
为什麽要迁移学习
迁移学习就是把用现有资料学习好的模型直接拿来使用,
因为卷积神经网路的前几层具有通用性广泛的特徵(低阶特徵),
这些特徵在不同分布的图片中都可以使用。
比如说猫狗辨识网路的前两层可以迁移到虎狼辨识网路上。
因为老虎和狼的照片与猫和狗的照片有点相似,却又不完全一样。
如果直接拿猫狗辨识网路来分辨老虎和狼的话,应该会很落漆~
诸如Google、Facebook等大公司有着巨量的资料、大量的运算资源和源源不绝的工作应聘者。
很多深度学习网路只有他们才能训练出来。
他们已经用我们无法企及的大数据训练出一个很棒的网路,
我们拿来微调最後的分类层就好了
迁移学习三方法
随着测试资料和预训练资料的差异越大,我们有1~3的方法。
越後面介绍的方法会调整越多预训练的参数。
1. Extract Feature Vector
这是最简单的版本,单纯把预训练CNN的最後一层卷积层输出(feature map)拿出来,
然後就没有预训练CNN的事情了。
之後用feature map当作一张图片的特徵,去训练一个简单的机器学习模型,
像是SVM、RF、NN等等。
2. Transfer Learning
这是真正意义上的迁移学习,
我们把预训练模型拿出来,
只对最後的输出层进行训练,
其他层的参数都固定不动。
3. Fine-tune
这是实际上最常用的方法,
相比於第2个方法只训练输出层,
Fine-tune会多训练几层。(通常是靠近输出层的网路层)
这个「多训练几层」也可以是「训练全部网路层」,
我们把它叫做「微调」。
在实务上,
我们会从後面的网路层开始逐渐解冻,
每解冻一个区域就训练个几轮。
例如:
- 解冻最後一层,训练10轮
- 解冻最後两层,再训练10轮
- 解冻最後三层,再训练10轮
这样模型才会稳定的收敛,
因为(在有些仍冻结的情况下)一次微调太多层的参数很容易不收敛,
有可能还不如把全部预训练参数都进行微调。
程序码
建立一个冻结参数的预训练模型
def build_model(preModel=EfficientNetB0,
pretrained=True,
num_classes=7,
input_shape=(48, 48, 3),
l2_coef=0.0001):
pre_model = preModel(include_top=False, weights='imagenet' if pretrained == True else None,
input_shape=input_shape,
pooling='max', classifier_activation='softmax')
for layer in pre_model.layers:
layer.trainable = False
x = Dropout(0.2)(pre_model.output)
output = Dense(
num_classes, activation="softmax", name="main_output",
kernel_regularizer=regularizers.l2(l2_coef))(x)
freezed_model = tf.keras.Model(pre_model.input, output)
freezed_model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=['accuracy'])
return freezed_model
如何解开冻结的参数
如果你想要把神经网路的最後n层变成可训练的:
def unfreeze_model(model, n=1, is_unfreeze_BN=False):
# We unfreeze the top n layers while leaving BatchNorm layers frozen
# n = 6 (~ block-top)
# n = 19 (~ block-7)
# n = 78 (~ block-6)
if is_unfreeze_BN == False:
for layer in model.layers[-n:]:
if not isinstance(layer, BatchNormalization):
layer.trainable = True
else:
for layer in model.layers[-n:]:
layer.trainable = True
记得最後要再执行一次model.compile(),
这些改动才会生效。
如何做二阶段式训练
这里我第一阶段先解冻6层,训练15轮。
第二阶段解冻19层(包含那6层),再训练15轮。
总共30轮。
- 6和19不是随便选的数字,这两个数字分别是EfficinetNetB0的最後两个Block的网路层
unfreeze_n = [6, 19]
phase_epochs = [15, 30]
phase_batch_size = [32, 32]
phases = len(phase_epochs)
model = build_model()
for i in range(phases):
unfreeze_model(model, n=unfreeze_n[i])
model.fit(X_train, y_train_oh,
validation_data=(X_val, y_val_oh),
initial_epoch=0 if i == 0 else phase_epochs[i-1],
epochs=phase_epochs[i],
batch_size=phase_batch_size[i])
实验结果
我把模型分成三个区块:
| 区块名称 | 从後面数来的层数 |
|---|---|
| Block-top | 6 |
| Block-7 | 19 |
| Block-6 | 78 |
| Block-all | 全部 |
把训练好的模型用以下称呼:
初始模型: EFN_base_init(不使用预训练参数,直接训练Block-all)
模型零: EFN_base(单一阶段微调Block-all)
模型一: EFN_2StepsToBlock7(先微调Block-top、再微调Block-7)
模型二: EFN_2StepsToAll(先微调Block-top、再微调Block-all)
模型三: EFN_3StepsToAll(先微调Block-top、再微调Block-7、再微调Block-all)
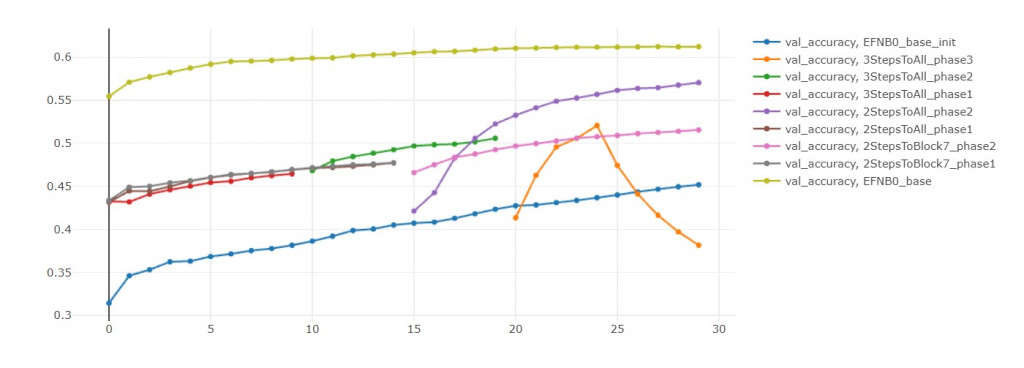
初始模型 vs 模型零
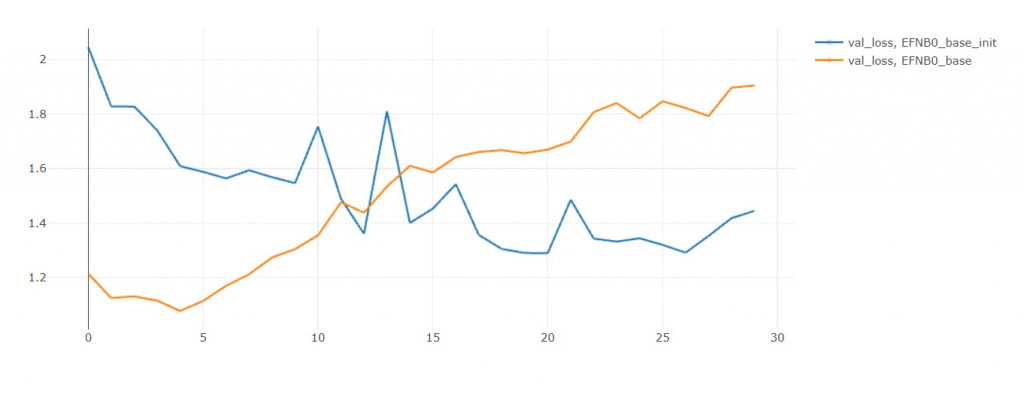
从val loss来看,初始模型比较没有过拟合的问题。
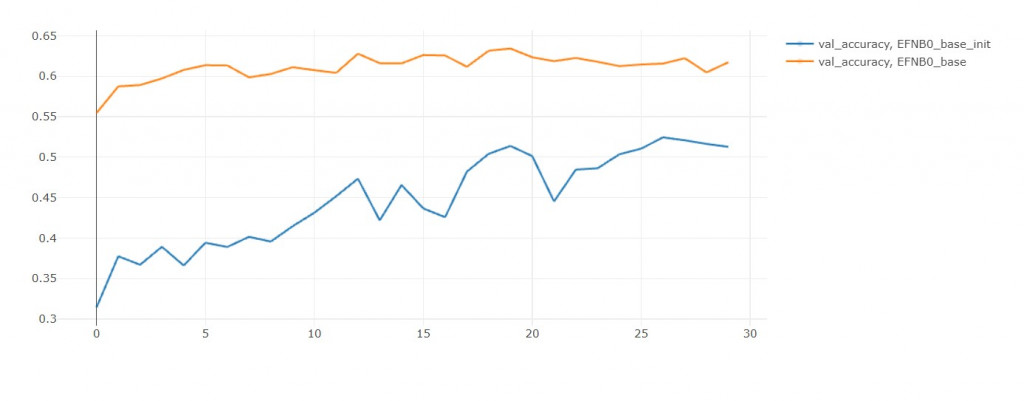
但是从 val accuracy来看,模型零有预训练的优势,准确率高不只一点。
我推断只要给初始模型更多训练轮数,
他能够无限趋近於模型零,
但最後还是会过拟合,
所以不如一开始就用模型零!
这就是迁移学习的好处。
模型一 vs 模型二
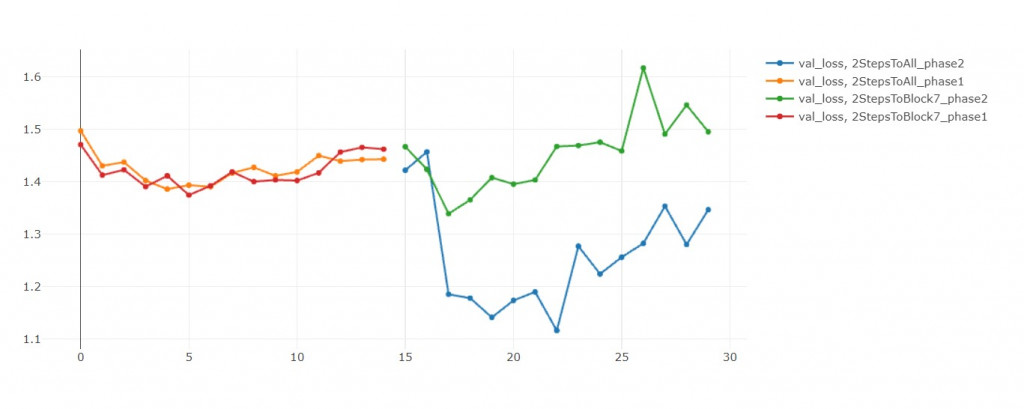
在前15轮中,两者不相上下。
但後15轮中,模型二收敛的比较好,
模型二 vs 模型三
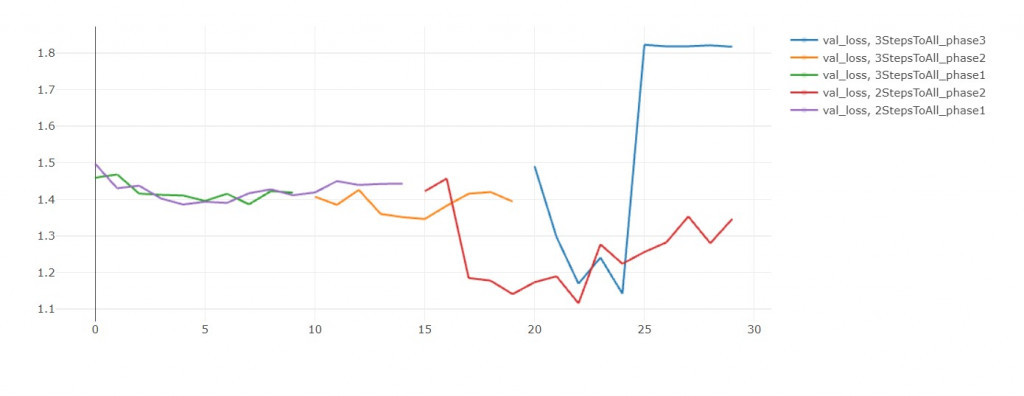
在第25轮,模型三的validation loss大幅上升。
我重复同样实验三次都得到这个结果。
我判断是学习率太大,导致我跳出local minimum,
然後跳不回去了
如果没有发生这种意外的话,模型三应当比较好才对
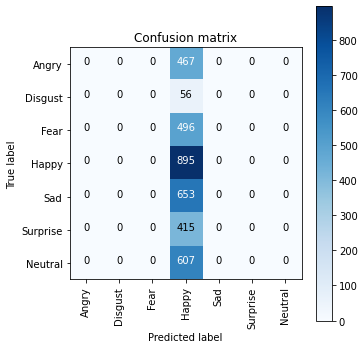
模型三学坏了!
全部都预测成Happy
应该是嗑药了
结语
如果单纯比较val acc,
那还是微调 Block-all 30轮胜出。
但这是不公平的,
因为每开放一个block,都应该要微调30轮才对。
但我为了节省时间,把总轮数设固定是30轮。
才让两段式学习看起来不如全直接部微调。
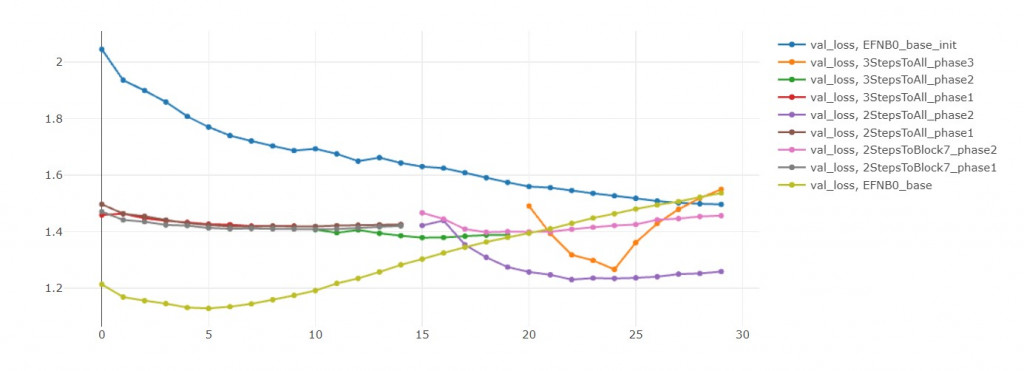
如果你观察 val loss,会发现多阶段训练还是比较有潜力的(训练更多轮)。
反之,看看EFN_base,
如果把模型都再训练10轮,
EFN_base的损失值简直快要飞上天和太阳肩并肩 = =
唤醒与生俱来的数学力 (2) 顺序 & 因果
由於昨天晚上听了明就仁波切的分享,今天原本想读 In Love with the World,但读了...
goto die? 那个 goto 到底能不能用啊?
写在开始之前 今年以系统程序为主题跳进 Software Development 算是一个大胆的尝试...
【Day 5】Google Apps Script - 变数与函式呼叫与GS档的顺序影响
在专案里,所有的档案都预先被 import 在一起的,可直接呼叫其他 gs档里的变数与函式。gs档...
【程序】给 23 - 28 岁的你的一封信 转生成恶役菜鸟工程师避免 Bad End 的 30 件事 - 29
来到了铁人赛的29天,扣除掉最後一集的心得,今天算是最後一个主题。 今天的影片和以往不太一样,我事...
[Day4] Arduino测试烧录
1.前言 铁人赛参赛的第一个周末(打卡),今天将带各位开始进入到开发阶段,废话不多说,赶紧往下看吧!...