[Day 19] 还是学不会,再缩小一点 ~ (学习率衰减)
前言
走过了资料分析、演算法选择後,
我们得知了有些可以改善模型的方向:
- 解决资料不平衡(Done)
- 学习率的设定(Now)
- 训练轮数(To do)
- 模型深度(No, I want my model to be more efficient ! )
- 阶段式训练(To do)
林俊杰唱过:
总是学不会 再聪明一点
众所周知,最佳化就是在调整模型参数以降低loss值,
而这个调整的速度会被学习速率(learning rate)控制,
learning rate越大就会改变参数越多。
optimizer如SGD、ADAM都会根据导数乘以learning rate来改变参数值。
所以 learning rate在训练模型时非常重要。
也会让网路更聪明地学习!
学习率衰减
学习率衰减是训练模型的小技巧,
通常我们会希望学习率一开始大,
这样才会学得快(损失函数收敛速度快)。
但随着训练时间提升,
模型参数已经趋於稳定,
我们会希望学习率减小,
才会稳稳地在global minimum来回。
(local minimum 你走开= =)
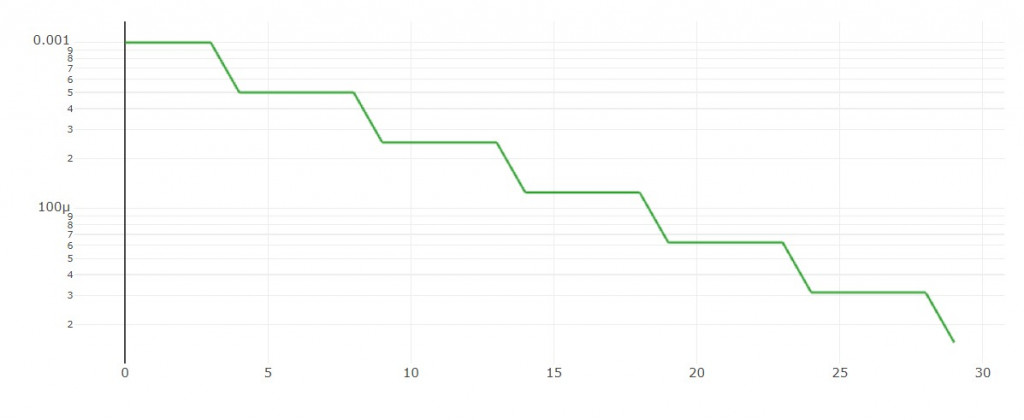
1. step decay
每隔n轮依比例下降。
学习率图形:
程序码实作:
def step_decay(epoch):
"""
Warm-up applying high learning rate at first few epochs.
Step decay schedule drops the learning rate by a factor every few epochs.
"""
lr_init = 0.001
drop = 0.5
epochs_drop = 5
warm_up_epoch = 0
if epoch+1 < warm_up_epoch: # warm_up_epoch之前采用warmup
lr = drop * ((epoch+1) / warm_up_epoch)
else: # 每epochs_drop个epoch,lr乘以drop倍。
lr = lr_init * (drop**(int(((1+epoch)/epochs_drop))))
return float(lr)
甚麽是warm-up?
大家可能注意到我有设一个参数是warm_up_epoch,
如果这个warm-up等於5,
代表前5轮训练时我使用由小渐大的学习率,随後使用step-decay。
例如: 0.0001, 0.0003, 0.0005, 0.0007, 0.0009, 0.001, 0.0005, 0.000025, ...
有人相信这个方法可以让模型後续收敛得更稳定。
(但我在这次实验中没有用到这个机制)
请参考这篇文章。
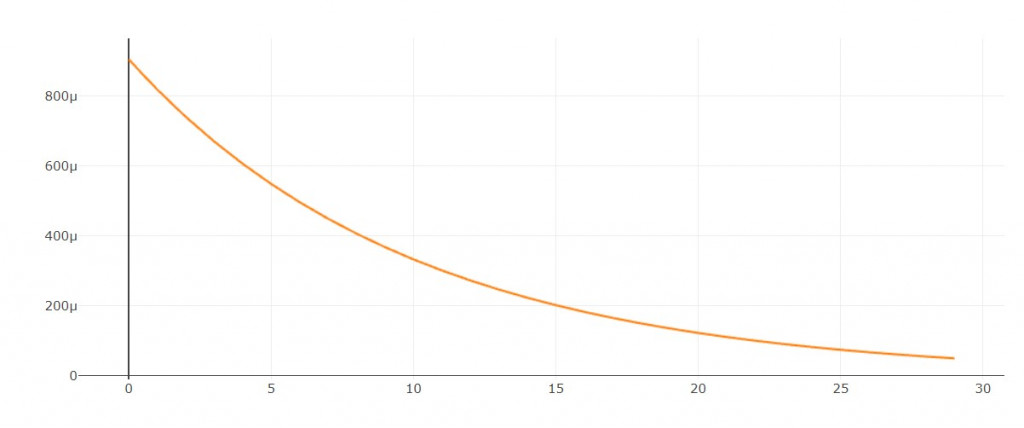
2. exponantial decay
每隔1轮依照指数下降
学习率图形:
程序码实作:
def exp_decay(epoch):
lr_init = 0.001
lr = lr_init * tf.math.exp(-0.2 * (epoch+1))
return float(lr)
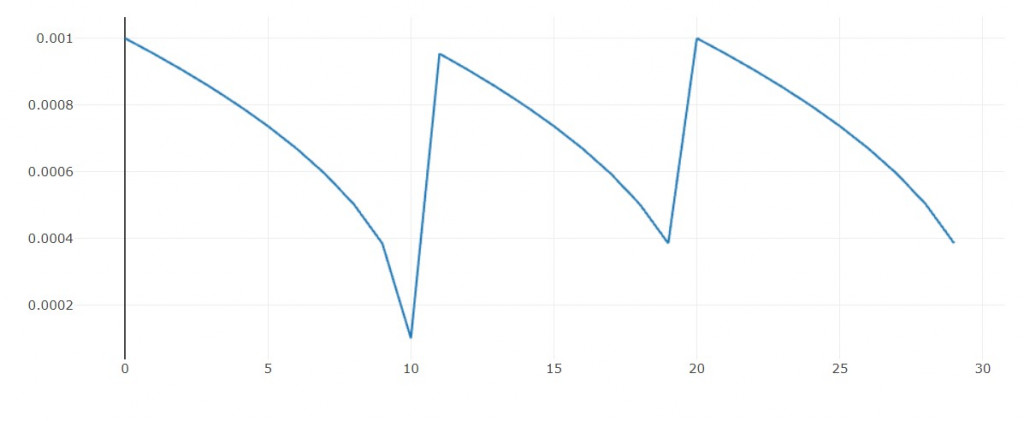
3. polynomial decay
每隔1轮依照多项式函数下降
这里我加上一个循环机制
if global_step >= decay_steps:
global_step = global_step % decay_steps
使得每隔n轮会重复相同图形
用意是: 当我陷入区域最小值的泥沼时,有机会跳出来。
学习率图形:
程序码实作:
def poly_decay(epoch):
lr_init = 0.001
lr_end = 0.00001
decay_steps = 10
global_step = epoch
power = 0.5
if global_step >= decay_steps:
global_step = global_step % decay_steps
lr = (lr_init-lr_end)*((1-(global_step/decay_steps))**power) + lr_end
return float(lr)
实验结果
- 这里要注意,因为EFN_poly从第11轮开始有循环,所以我们比较第10轮的表现。
验证准确率:step>poly>exp(准确率越大越好) in 10th epoch
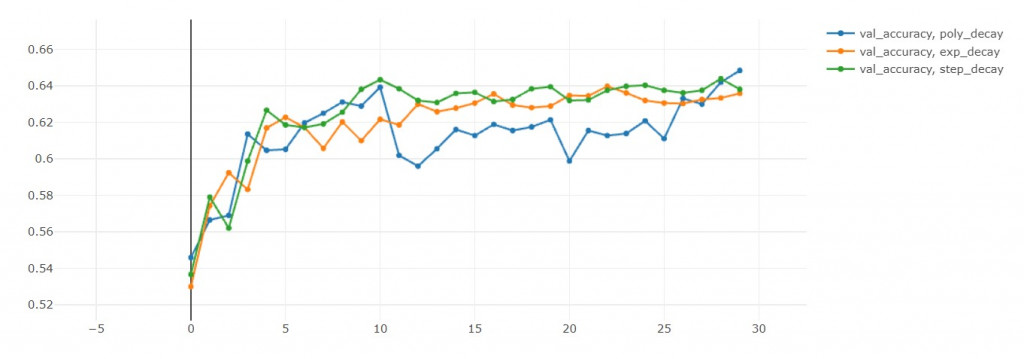
验证损失值:exp<poly<step(损失值越小越好) in 10th epoch
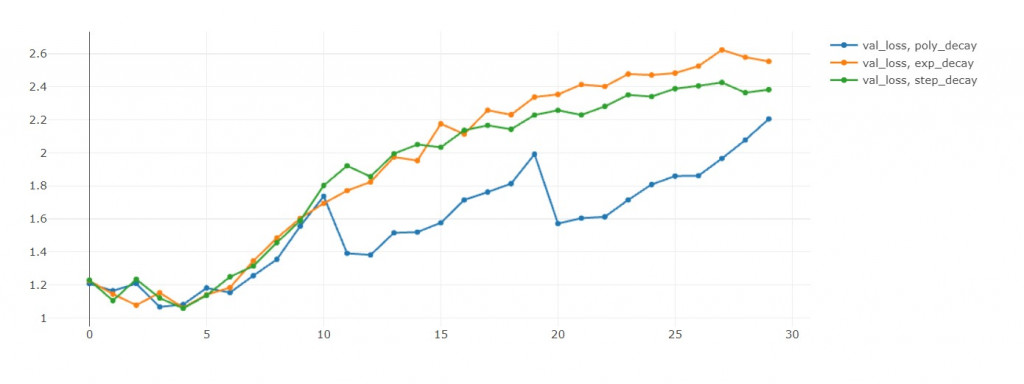
训练准确率:poly>step>exp in 10th epoch
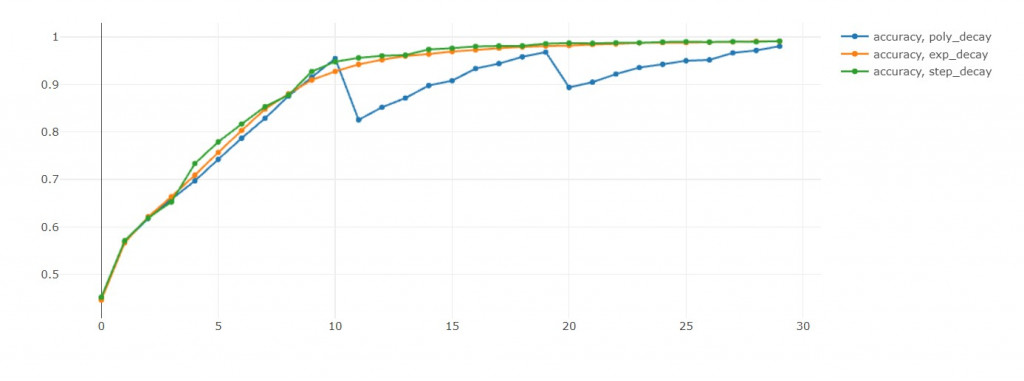
这里蛮有趣的地方是poly的循环机制,
可以从验证准确率和验证损失值中发现,
每次学习率回到初始值,这两者都会往下掉。
损失值下降是我们乐见的,代表演算法跳出之前的区域最小值,
前往寻找另一个区域最小值。
当然我不用担心演算法找不到另外一个区域最小值,
因为我可以储存每个epoch的模型。
但如果没有循环机制,
我就要担心演算法困在这一个区域最小值了!
comparing all metrics
| 模型 | 训练时长(秒) | acc | loss | val_acc | val_loss |
|---|---|---|---|---|---|
| EFN_step | 1960 | 0.991(胜) | 0.026(胜) | 0.638 | 2.383 |
| EFN_exp | 2083 | 0.991 | 0.029 | 0.636 | 2.554 |
| EFN_poly_cyclic | 2018 | 0.98 | 0.057 | 0.648(胜) | 2.205 |
| EFN_base | 2004 | 0.952 | 0.139 | 0.617 | 1.905(胜) |
结语
- exp dacay的学习率下降太快,导致模型还没在这个学习率上好好最佳化就缩小学习率了。
- step dacay应该是比较理想的方法,能够学得充分,不像其他两个方法每轮都下降。
- 循环机制很棒,以後要试试搭配其他衰减法。
<<: 【Day 19】Shellcode 与他的快乐夥伴 (下) - Shellcode Loader
>>: D24 - 用 Swift 和公开资讯,打造投资理财的 Apps { 台股成交量实作.4 }
Day14-Load Balance
负载平衡 API 最基本遇到的问题是如果使用者越来越多的时候 一台 Server 一定无法满足这些负...
Day4|【Git】用户名称与信箱- Git的初始设定与 config
💡 开始使用 Git 之前,我们需要先设定使用者名称及电子邮件地址。 为什麽需要设定用户名称及 E-...
感受时间的亲戚,时间、目标、精力三管
感受时间 六点半起来的好处,大概就是符合我晨型人的生理。 多出来的时间&早上的精力正好,很适合我做运...
DAY1-凡事起头难
前言: 总共104天的暑假要到来~离开学日子还很遥远我们这一个世代每天都要面对如何用力痛快的 学习...
【day3】和牛涮-和牛三吃
和牛涮最近很常出现在朋友的ig画面中 前阵子找时间到忠孝店品嚐 在价位方面 考量炙烧和牛寿司有数量限...