[Python]回归模型01─运用OLS做回归
Hi! 大家好,我是Eric,这次要来用Python做回归模型。

- 缘起:回归模型是常见的分析方法,可用来分析数值变数之间的关系。
- 方法:运用 [Python]的[statsmodels.api] 套件。
- 使用资料:台北市交通统计月报-公车运量、台北市政府民政局-人口数、新北市政府民政局-人口数、台北大众捷运股份有限公司-捷运运量
- 参考来源:
- https://www.twblogs.net/a/5b7a95f72b7177392c966121
- https://learnku.com/articles/39890
- https://info.todohealth.com/22056516
- ttps://www.statsmodels.org/dev/generated/statsmodels.regression.linear_model.OLS.html
1. 载入套件。
import statsmodels.api as sm #回归模型套件
import numpy as np #资料处理套件
import pandas as pd #资料处理套件
2. 输入资料。
df0 = pd.read_csv("TaipeiAllBus 0105.csv") #输入资料
df0
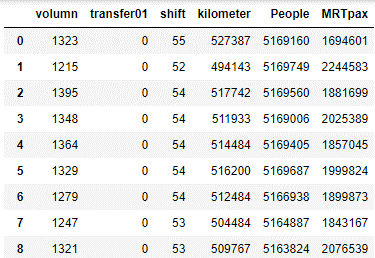
3. 资料前处理。
df0_X = df0.drop("volumn", axis=1) #将作为y的变数volunm删去,并另存为x
df0_X1 = df0_X.drop("transfer01", axis=1) #之後要做相关系数,而因为transfer01变数为虚拟变数,故不须纳入做相关系数,故删除
df0_y = df0[["volumn"]] #制作变数y
4. 相关系数检验。
rDf0 = df0_X1.corr() #查看数据间的相关系数
print(rDf0)
%matplotlib inline
sns.set(font_scale=1.5)
sns.set_context({"figure.figsize":(8,8)})
sns.heatmap(data = rDf0, square = True, cmap="RdBu_r", annot = True)
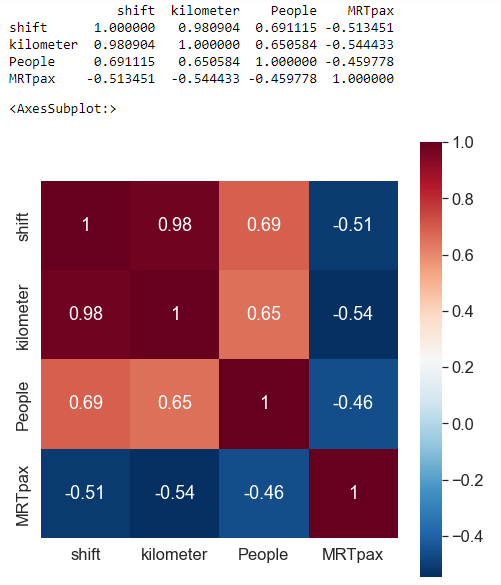
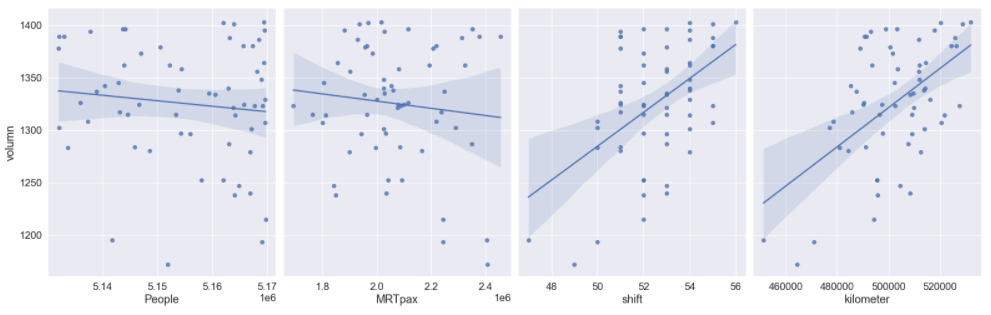
5. 检视资料分布情形。
import seaborn as sns #载入分布图形套件
import matplotlib.pyplot as plt #载入画图套件
sns.pairplot(df0, x_vars=["People","MRTpax", "shift", "kilometer"], y_vars='volumn', size=7, aspect=0.8, kind='reg')
plt.show()
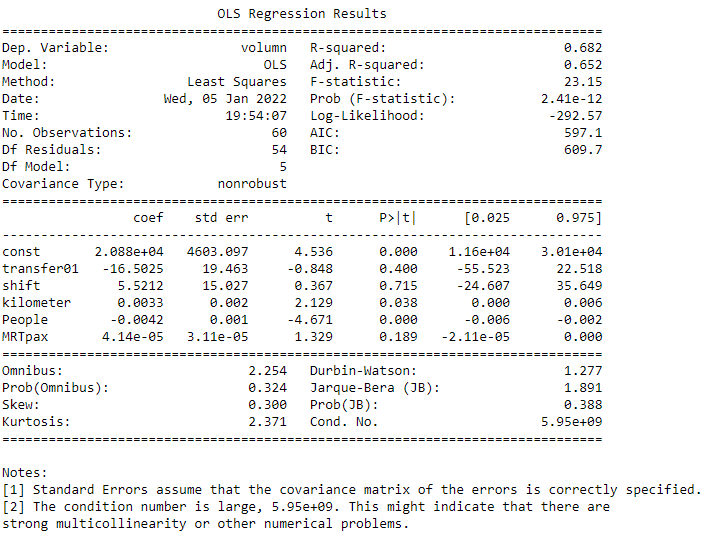
6. 建模。
df0_X = sm.add_constant(df0_X) #增加模型的常数,使更为符合回归模型
model0 = sm.OLS(df0_y, df0_X) #OLS回归
results0 = model0.fit()
print(results0.summary())
7. 大功告成。
下图就是回归的结果,可以看到各个x变数的系数,以及P值,检验哪些x变数对於y具有显着影响,另外也可由R2检验模型的解释能力。
DAY14 挑选合适的模型进行训练
机器学习可以分成监督式学习与非监督式学习,这部分我们在第四天有稍微提到过,这边就不多做说明了,今天我...
IOS、Python自学心得30天 Day-1 环境建置
前言: 因为最近需要用到Python,顺便纪录一下自己学习的过程 正文: 官方网站: https:/...
Day05:就像是刷牙洗脸倒垃圾
今天大概的进度要进到Controlling Program Flow,不过我自己对於这个章节好像没有...
[Day0] 前言
嗨!我是莉莉,目前是个软件工程师。去年因为公司内部任务接触到和资安相关的议题,开始对资讯安全感兴趣、...
Log Agent - Fluent Bit Input元件 与 Tail浅谈
Fluent bit回顾 Log Agent - Fluent Bit 简介 Log Agent -...