[Day 21] 调整模型超参数利器 - Optuna
Optuna
今日学习目标
- Optuna 如何采样参数?
- 实作 Optuna 搜寻最佳超参数
- 以 XGBoost 回归模型於房价预测为例
- Optuna 视觉化分析搜寻结果
前言
你是否曾经觉得模型有太多的超参数而感到厌烦吗?要从某一个演算法得到好的解必须要调整超参数,所谓的超参数就是控制训练模型的一组神秘数字,例如学习速率就是一种超参数。你永远都不知道 0~1 之间哪一个数字是最适合的,唯一的方法就是试错 (trial and error)。那万一模型有多个超参数可以控制,岂不是就有成千上万种组合要慢慢尝试吗?如果你有也这个问题,看这篇就对了!虽然你可能听过 Sklearn 的 GridSearchCV 同样也是暴力的找出最佳参数,或是使用 RandomizedSearchCV 指定超参数的范围并随机的抽取参数进⾏训练,其它们的共同缺点是非常耗时与占用机器资源。这里我们要来介绍 Optuna 这个自动找超参数的方便工具,并且可以和多个常用的机器学习演算法整合。Optuna 透过调整适当的超参数来提高模型预测能力,此专案最初於 2019 发表於 arxiv 的一篇论文 Optuna: A Next-generation Hyperparameter Optimization Framework 同时开源在 GitHub 上免费提供大家使用。同时 Optuna 也是 2021 年 Kaggle 资料科学竞赛中最常见的模型调参工具。那是什麽原因让 Optuna 受到广大的机器学习社群如此的欢迎呢?就让我们来看看他是如此地强大吧!

关於 Optuna
Optuna 是一个专为机器学习设计的自动超参数优化的框架。其最突出的特点是:
- 人性化的定义搜索空间。
- 支援大多数 ML 与 DL 的学习套件。例如: Sklearn、PyTorch、TensorFlow, XGBoost、LightGBM、 CatBoost...等。
- 对对搜索结果提供可解释性(XAI)。
- 储存历史最佳的参数实现平行优化工作。
- 决定并终止不满足预定义条件的试验。
Optuna 简单范例
这里我们设定一个简单的目标函式 (x1+2)^2+(x2−4)^2。我们都知道当这个式子 x1=-2, x2=4 时将会有极小值 0。因此我们就用这个简单的例子透过 Optuna 找出这个函式中极小值所对应的 x1 与 x2 吧。
import optuna
def objective(trial):
x1 = trial.suggest_float("x1", -5, 5)
x2 = trial.suggest_float("x2", -5, 5)
return (x1 + 2) ** 2 + (x2 - 4) ** 2
首先载入 optuna 套件,如果尚未安装此套件的的读者可以参考以下指令进行安装:
pip install optuna
接着我们来定义一个找出极小值的目标函式 objective()。在这个函式中我们将要设定 optuna 可以去寻找的一参数,也就是 x1 与 x2。我们可以透过 optuna 所提供的 trial 物件来为我们的超参数设定一组范围。其中它有一个 suggest_float 方法,该方法采用超参数的名称和范围来寻找其最佳值。我们以 x1 来举例:
x1 = trial.suggest_float("x1", -5, 5)
上面这一段程序在 GridSearch 中可以表示成 {"x1": np.arange(-5, 5, .1)}。即表示搜寻过程中我们会从 x1 随机设定 -5~5 之间的任一浮点数。设定完函式後就可以开始优化了,我们从 optuna 建立一个 study 物件,并将 objective 函数传递给 study 的 optimize 方法。由於我们的目标是要找出函式中的极小值,因此 direction 设为 minimize。另外在 optimize 方法中我们也可以设定试验的次数(n_trials)或时间(timeout)。一切就绪後即可开始执行!以下范例是迭代50次并从中找到一组最佳的 x1 与 x2 使其目标函式可以最小化。跑完 50 次後我们可以经由 study 变数中得到一组最佳的解。试验结束後我们可以发现 x1 趋近於 -2 和 x2 趋近於 4。
%%time
# Creating Optuna object and defining its parameters
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials = 50)
# Showing optimization results
print('Number of finished trials:', len(study.trials))
print('Best trial parameters:', study.best_trial.params)
print('Best score:', study.best_value)
输出结果:
Number of finished trials: 50
Best trial parameters: {'x1': -1.8154924755761588, 'x2': 3.9141985823539844}
Best score: 0.04140490983908035
CPU times: user 432 ms, sys: 46.3 ms, total: 478 ms
Wall time: 431 ms
由上述的简单例子我们可以知道建立一个 optuna 最佳化流程仅需要三步骤:
- 建立 objective 函式与设定 trial,并回传 loss。
- 建立
create_study()物件。 - 使用
optimize()执行搜寻。
End-to-end example with XGBoost
我们以 Sklearn 所提供的房价预测资料夹来做范例。此资料集共有 506 笔资料,其中输入特徵有 13 个其输出为预测该笔资料的房价。由於想要快速示范如何使用 optuna,因此这里就不做任何资料 EDA 与前处理。
from sklearn.datasets import load_boston
X, y = load_boston(return_X_y=True)
print('X:',X.shape)
print('y:',y.shape)
输出结果:
X: (506, 13)
y: (506,)
资料集成功被载入後我们就可以建立一个 objective 函式。在这个目标函式中,我们建立了一个小范围的的 XGBoost 超参数搜索空间。其每一个超参数都会有一个搜索的范围,可以使用 suggest_* 方法设定区间。此方法必须输入超参数的名称,以及给予该参数的一组随机范围其型态有很多例如:suggest_int、suggest_discrete_uniform、suggest_float...等。更多详细的内容可以从官方文件取得。或是也可以参考官方在 GitHub 上对於 XGBoost 的使用范例。
import optuna
import xgboost as xgb
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def objective(trial, X=X, y=y):
"""
A function to train a model using different hyperparamerters combinations provided by Optuna.
"""
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.4)
params = {
'max_depth': trial.suggest_int('max_depth', 6, 15),
"subsample": trial.suggest_float("subsample", 0.2, 1.0),
'n_estimators': trial.suggest_int('n_estimators', 500, 2000, 100),
'eta': trial.suggest_float("eta", 1e-8, 1.0, log=True),
'alpha': trial.suggest_float('alpha', 1e-8, 1.0, log=True),
'lambda': trial.suggest_float('lambda', 1e-8, 1.0, log=True),
'gamma': trial.suggest_float("gamma", 1e-8, 1.0, log=True),
'min_child_weight': trial.suggest_int('min_child_weight', 2, 10),
'grow_policy': trial.suggest_categorical("grow_policy", ["depthwise", "lossguide"]),
"colsample_bytree": trial.suggest_float("colsample_bytree", 0.2, 1.0)
}
reg = xgb.XGBRegressor(**params)
reg.fit(X_train, y_train,
eval_set=[(X_valid, y_valid)], eval_metric='rmse',
verbose=False)
return mean_squared_error(y_valid, reg.predict(X_valid), squared=False)
设定好调参的区间後,即可开始罗。
%%time
# Creating Optuna object and defining its parameters
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials = 10)
# Showing optimization results
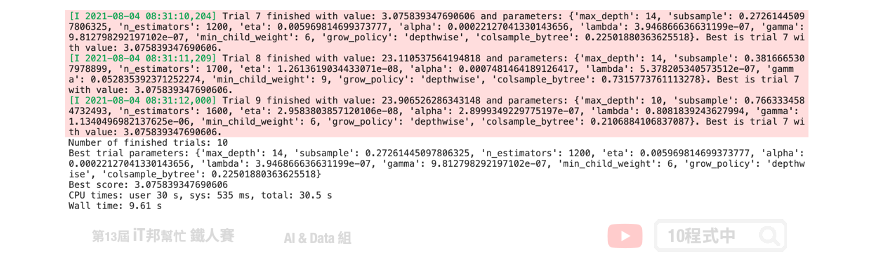
print('Number of finished trials:', len(study.trials))
print('Best trial parameters:', study.best_trial.params)
print('Best score:', study.best_value)
Optuna 预设的超参数搜寻方法能有效地在短时间内往最佳的方向去寻找一组适合的参数。与 GridSearch 相比原本可能需要数小时的搜索空间在短短的几分钟内就可以获得不错的经果。并且有效的降低 loss。除了回归问题 Optuna 也能对分类问题进行超参数搜寻,官方的 GitHub 也有提供各种不同机器学习框架的写法。
Optuna 如何采样参数?
TPESampler 为预设的超参数采样器。它试图透过提高最後一次试验的分数来对超参数候选者进行采样。除此之外 Optuna 提供了以下这几个参数采样的方式:
-
GridSampler: 与 Sklearn 的GridSearch采样方式相同。使用此方法时建议不要设定太大的范围。 -
RandomSampler: 与 Sklearn 的RandomizedGridSearch采样方式相同。 -
TPESampler: 全名 Tree-structured Parzen Estimator sampler。预设采样方式。 -
CmaEsSampler: 基於 CMA ES 演算算法的采样器 (不支援类别型的超参数).
如果需要替换采样参数的方式可以参考以下程序。
from optuna.samplers import CmaEsSampler, RandomSampler
# Study with a random sampler
study = optuna.create_study(sampler=RandomSampler(seed=42))
# Study with a CMA ES sampler
study = optuna.create_study(sampler=CmaEsSampler(seed=42))
Optuna 视觉化分析
Optuna 在同时也提供了视觉化的套件:
- plot_optimization_history (视觉化优化的过程)
- plot_intermediate_values (视觉化学习的曲线)
- plot_parallel_coordinate (视觉化高维度中参数间的彼此关系)
- plot_contour (视觉化参数间的彼此关系)
- plot_slice (视觉化个别参数)
- plot_param_importances (参数对模型的重要程度)
- plot_edf (视觉化验分布函数)
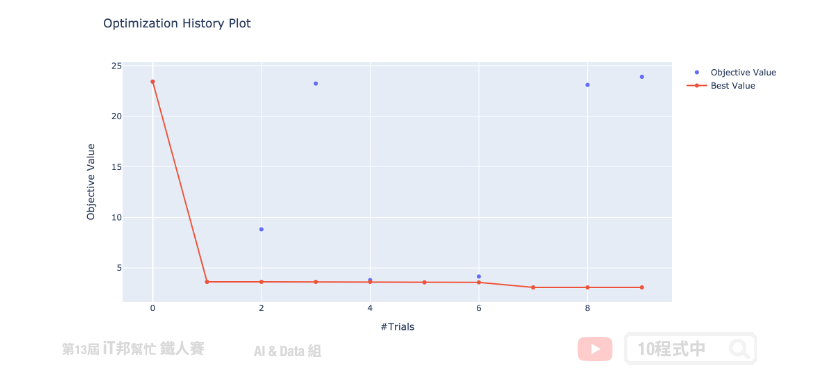
延续上面的范例我们来视觉化展示 Optuna 搜寻的过程与结果。首先我们来绘制 study 的优化历史过程。这张图告诉我们,Optuna 只经过几次试验就使分数收敛到最小值。
from optuna.visualization import plot_optimization_history
plotly_config = {"staticPlot": True}
fig = plot_optimization_history(study)
fig.show(config=plotly_config)
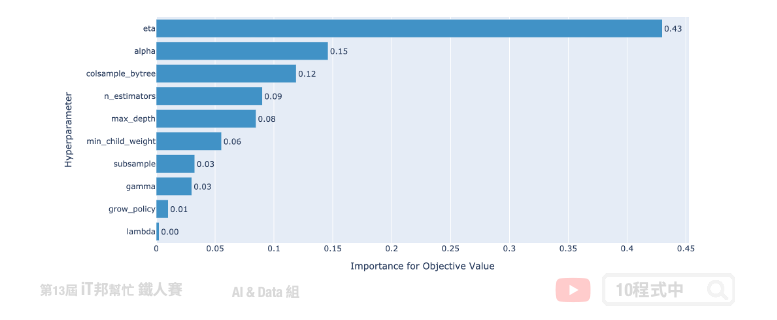
接下来,让我们绘制超参数重要性。从这张图我们可以发现 eta(learning_rate) 学习速率是最为重要的。此外 grow_policy 与 lambda 对减少 loss 上无太大帮助。因此在下一次执行试验的时候可以考虑将无用的参数移除,并将重要的超参数范围加大取得更好的搜索结果。其他的使用方法可以 参考 官方的说明文件。
from optuna.visualization import plot_param_importances
fig = plot_param_importances(study)
fig.show(config=plotly_config)
小结
今天我们介绍了这一个超参数最佳化的工具,里面有太多功能尚未提到。例如:试验的剪枝,简单来说就是设定试验的例外条件当不满足预定条件即不执行此次试验。或是储存历史最佳的参数实现平行优化工作。除此之外此套件还支援像是 SQLite 等资料库可以储存历史搜寻结果快速的达到最佳搜寻能力。重点此套件还支援神经网路的参数搜寻以及网路的宽度深度选择。常见的深度学习框架都能支援例如 TensorFlow、PyTorch,MXNet...等。
Reference
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: [前端暴龙机,Vue2.x 进化 Vue3 ] Day24.Vue3 Options API & Composition API 介绍
Day14 ATT&CK for ICS - Execution(1)
Execution 攻击者尝试任意执行程序码与指令、控制工控设备的功能、调整参数与修改资料。 T0...
Day 14 - Object and Arrays - Reference VS Copy
前言 JS 30 是由加拿大的全端工程师 Wes Bos 免费提供的 JavaScript 简单应用...
如何在图片和按钮上设定圆形 - 最终章
透过设定 view 的 layer.cornerRadius,我们可以为原本方方正正的 view 增...
【後转前要多久】# Day18 BootStrap - 快速看文件
学BootStrap最快的方式就是直接套一个模板来使用。 我们直接来套一个 Navbar Navba...
24. 工程师之伤 x 久坐 x 徒手治疗
本篇是病人的非专业心得分享。 酸痛其实是老毛病,因为工程师一不小心就久坐,长期会让酸痛恶化。 如果...