爬虫怎麽爬 从零开始的爬虫自学 DAY19 python网路爬虫开爬-2网页解析
前言
各位早安,书接上回我们已经成功抓到网页的原始码了,今天我们要把它变成有用能阅读的资讯
开爬-网页分析
那我们解析网页就要用到 bf4 的功能了
先把印出全部 html 删掉 因为我们不用知道全部
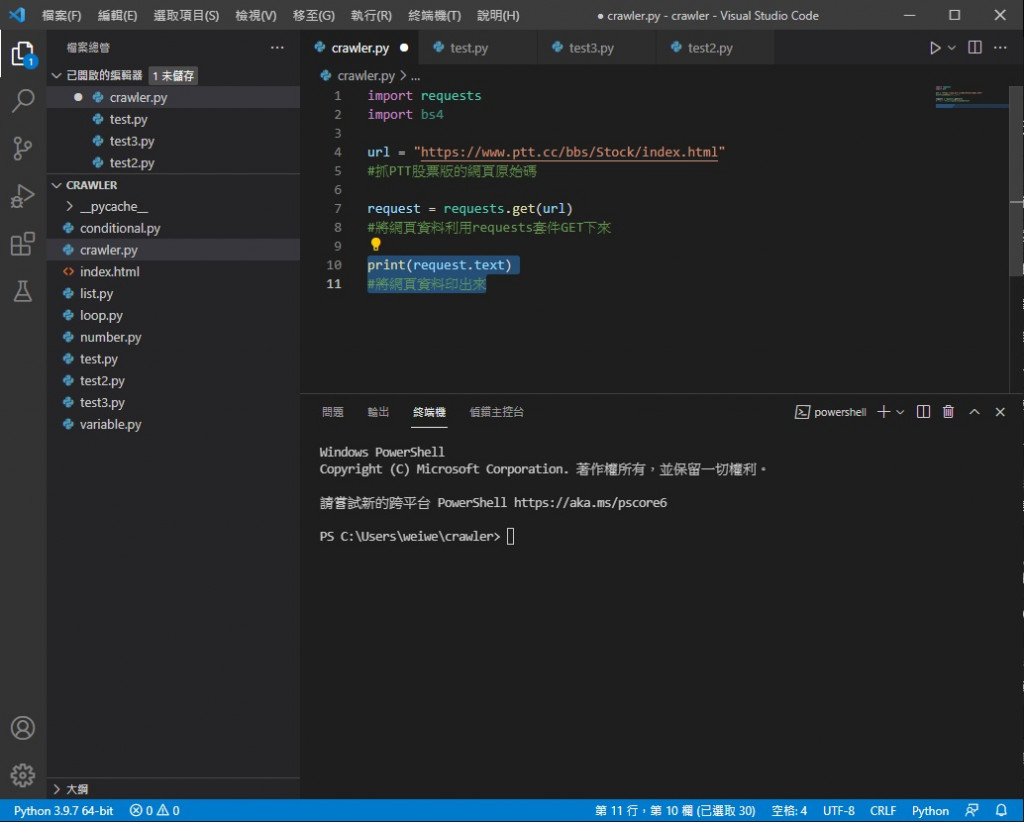
把这里删掉
接下来我们要解析它
在下面加上
data = bs4.BeautifulSoup(request.text, "html.parser")
print(data)
我们建立 data 变数用来存放经过 bs4 解析过的资料 request.text
然後解析的格式用 "html.parser"
然後印出 data
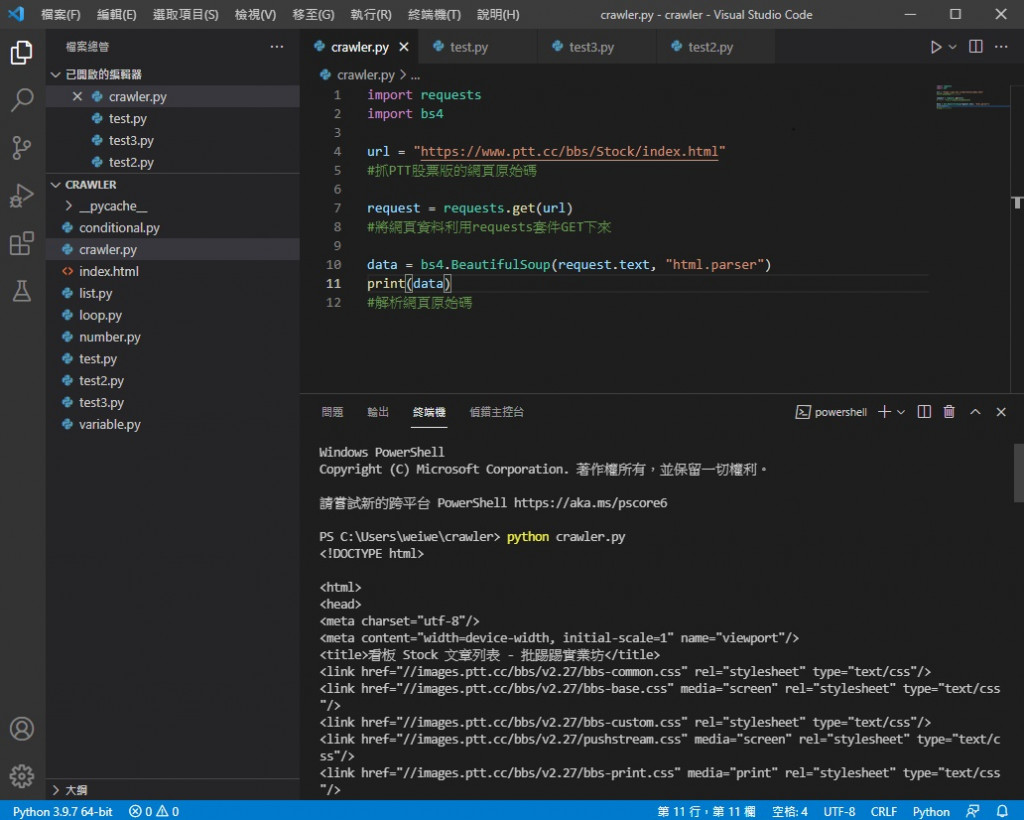
可以看到虽然还是看不懂 但是跟之前不同了
这是经过 bs4 解析整理过後的样子
开爬-网页抓取指定位置
我们先试着抓抓看最明显的网页标题
也就是这个东西

接下来我们开浏览器到网页原始码的地方
网页标题的原始码就在这
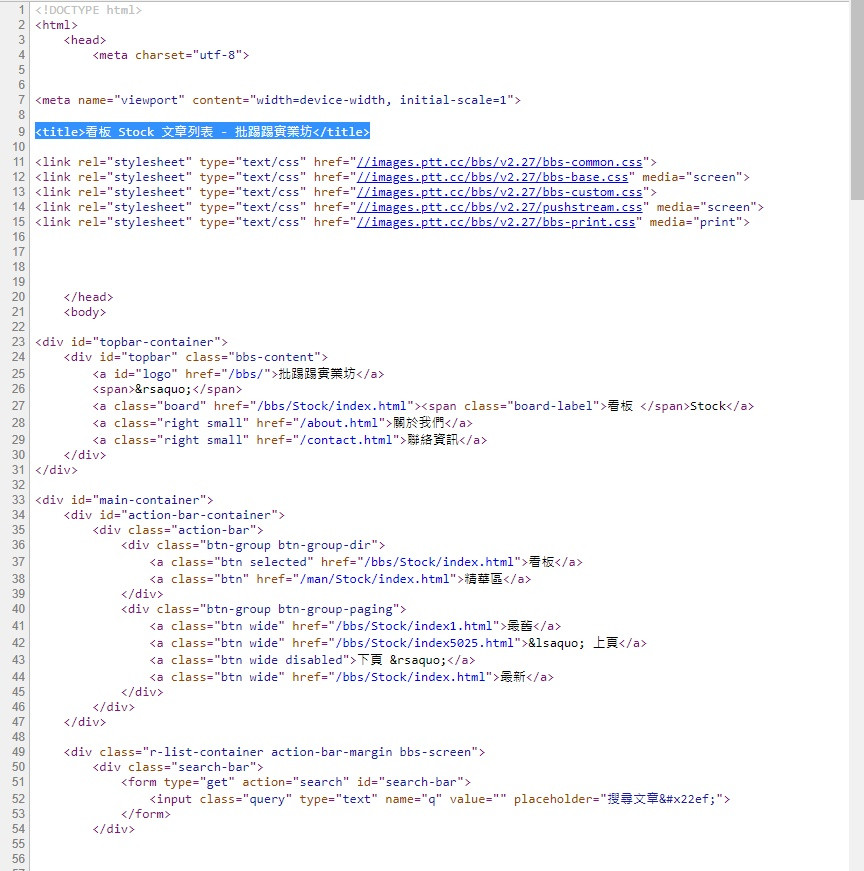
它的标签是 title
所以我们把 print(data) 加上 .title
变成
print(data.title)
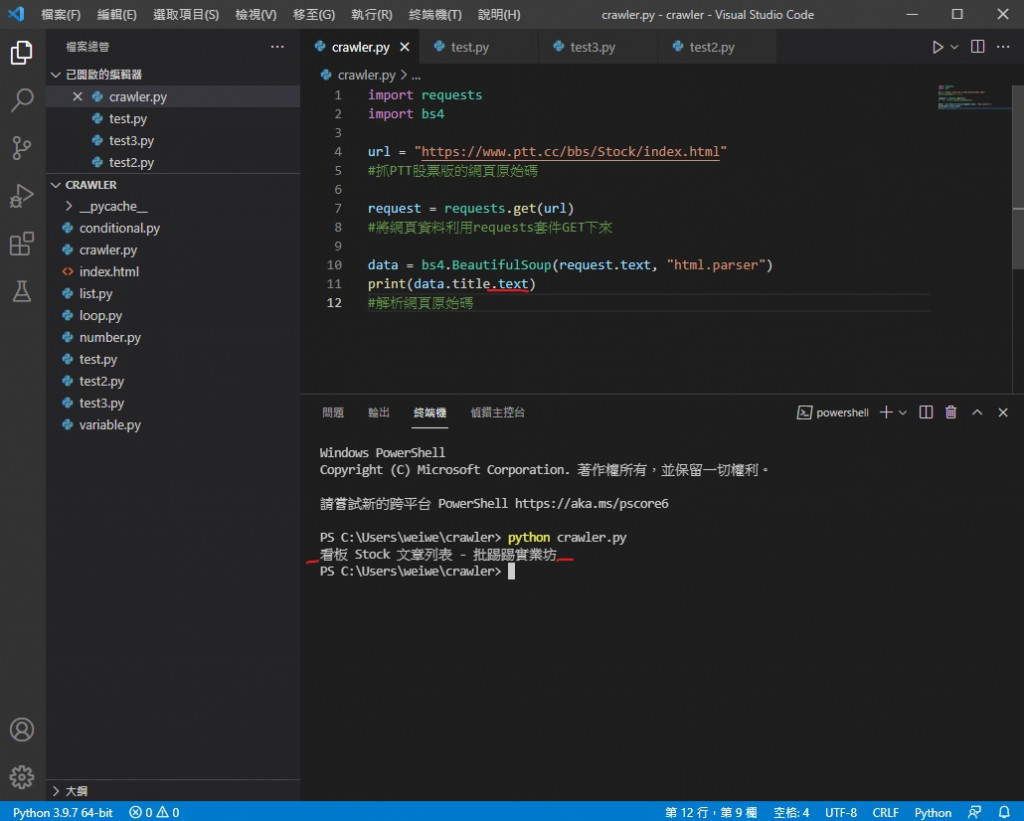
现在程序码
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index.html"
#抓PTT股票版的网页原始码
request = requests.get(url)
#将网页资料利用requests套件GET下来
data = bs4.BeautifulSoup(request.text, "html.parser")
print(data.title)
#解析网页原始码
执行结果
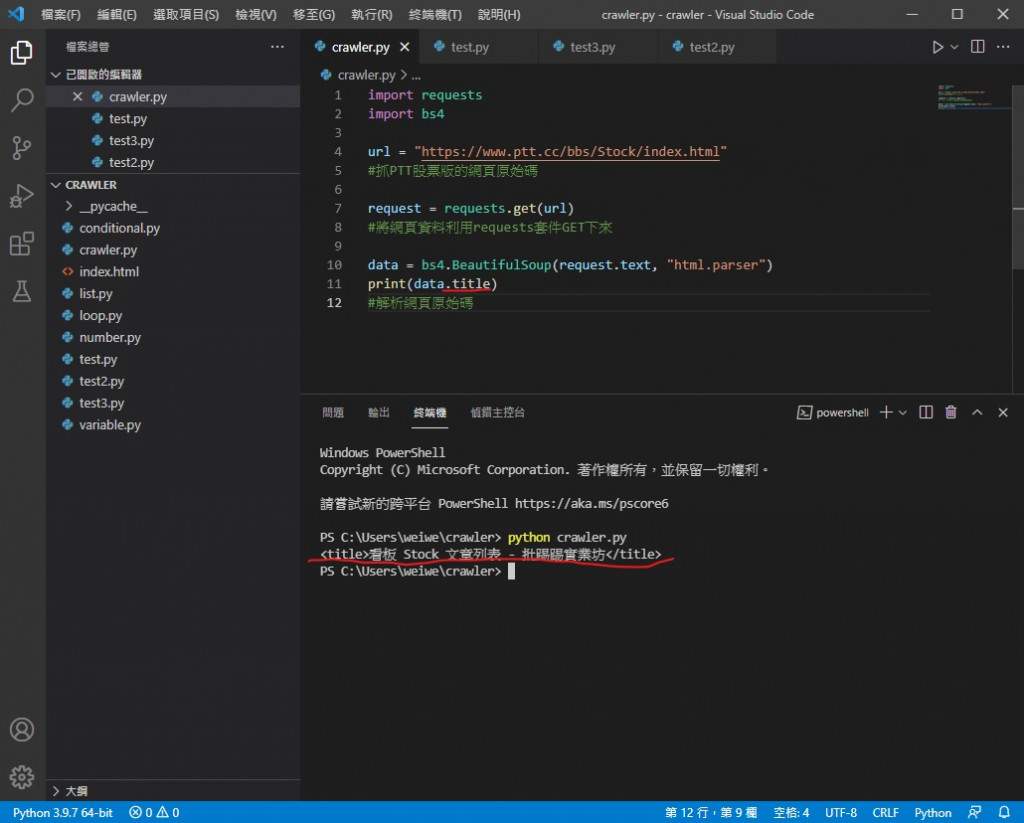
可以看到成功印出来了
那如果不希望它旁边有标签
就在 print(data.title) 里面加上 .text
变成
print(data.title.text)
执行结果
可以看到成功去掉标签了
从以上我们可以看出 在我们抓取资料时 要一层一层指定我们要的资料
今天的程序码
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index.html"
#抓PTT股票版的网页原始码
request = requests.get(url)
#将网页资料利用requests套件GET下来
data = bs4.BeautifulSoup(request.text, "html.parser")
print(data.title.text)
#解析网页原始码
今天我们知道怎样解析资料并指定到想要的位置
明天我们要来以文章标题做目标进行更进阶一点的爬取资料]
早安闲聊区
你知道吗?
鲸鱼的屍体放着会腐败发酵最後爆炸喔
每日二选一
如果可以的话你希望知道自己死掉的日期好好安排剩下时间还是不知道开心度日呢
>>: 【Day 21】Algorithm - Find Cycle in Directed Graph
Day 23 - 字串又来了,我还是没吃到串烧
Outline 可以把这三个东西理解成 class 的更多运用。 C++ Strings : 比之前...
[DAY-08] 增进诚实敢言 把一切摊在阳光下
人们如果主动隐瞒某些事 反而会花两倍时间想着那着些事 秘密的问题在於 只要你说出来 他就不再是秘密...
今天来瞄一眼龙与雀的科技:知觉共享技术 Body-sharing
嘿 前天去看了龙与雀斑公主,音乐真的很好听,剧情烘托的还不错。但每当遇到这种网路分身的题材时,我总是...
企划实现(30)
止损 止损顾名思义就是停止损失,今天在做企划的同时,世界并不会停下来等你发展,所以如果在做企划的同时...
[火锅吃到饱-4] 疯虾吃到饱(台中) Shrimp Buffet In Taichung 现点现做的虾料理
来疯虾是为了吃火锅的人应该是少数,但是,如果您来到疯虾,真的要试试他们的火锅~ 我很喜欢泰国虾,有时...