Day 19 : 静态爬虫(下)
今天继续来谈论静态爬虫,昨天都在讲解文字,今天来讲讲图片的部分。常常看到一个网页中有很多漂亮的图片,可是一张一张下载太浪费时间了,这时候就可以使用爬虫来批量下载图片。
这次就用这个unsplash这个网站来作范例吧,这个网站有很多高画质的图,今天的目的就是写一个可以在本地端搜索想要的图并下载的功能。
网站分析
要进行搜寻的功能,问题最大的就是网址,所以要先找到网站的网址规律,才能根据想要的图片更改URL发送HTTP请求。我们先在这网站中随便搜寻一下:
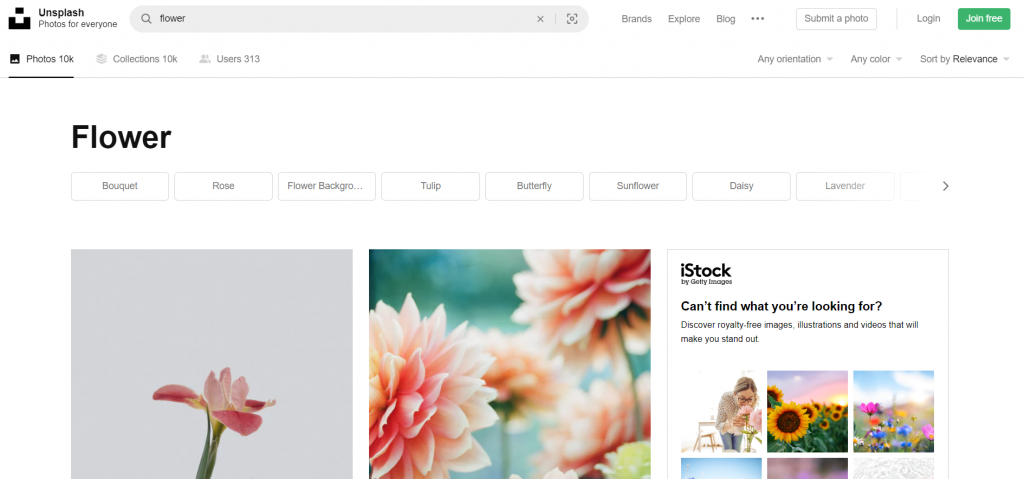

其实就可以发现在网址中photos後又增加了"/搜寻的关键字",找到规律後就可以开始撰写程序了。
这次因为是真正的要取得图片档案,所以必须使用os套件来帮助自动化建立资料夹等功能,所以我们会用到三个套件:
from bs4 import BeautifulSoup
import requests
import os
再来撰写利用使用者的输入来更改URL发送HTTP请求的功能,程序码如下:
input_image = input("请输入要下载的图片:")
response = requests.get(f"https://unsplash.com/s/photos/{input_image}")
ㄟ你怎麽没打User Agent? 我懒(X)
还是建议各位打一下就是了,这边的程序码会在启动程序後显示"请输入要下载的图片:"并且可以让你输入文字,将输入的文字存入input_image并且利用f字串来更动网址。
再来又需要检查网页了,有看到那个箭头吗,看来那个地方就是下载图片的按钮了,直接右键检查:
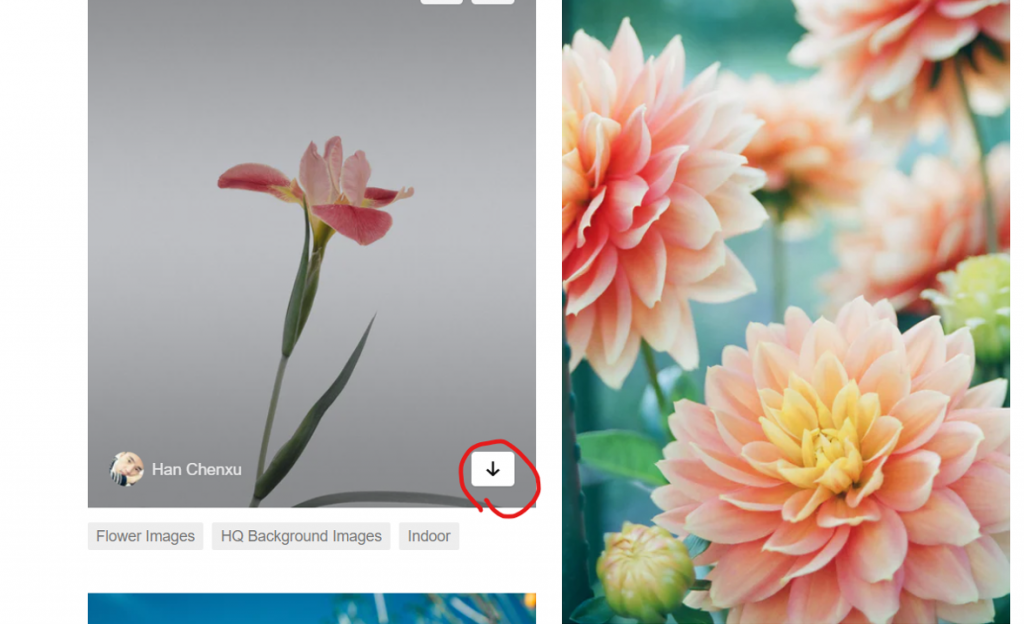
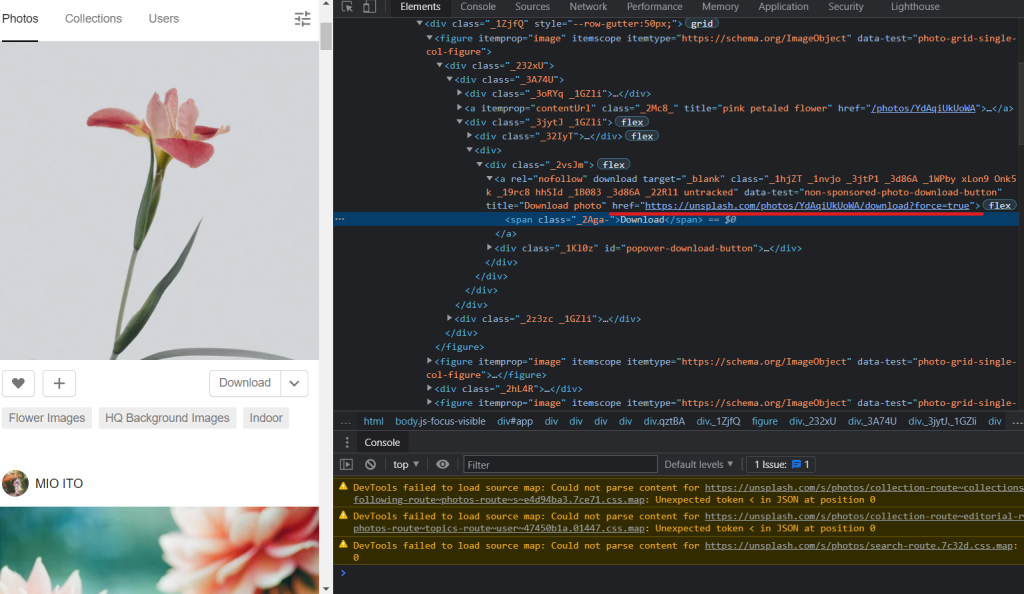
n = 0
for datal in data:
n = n+1
a = (datal.find('a')['href'])
folder_path = f'./images/{input_image}/'
img_name = folder_path +f"{n}.jpg"
r = requests.get(a)
os.makedirs(folder_path, exist_ok=True)
程序码开始复杂起来了呢,可是仔细看就会发现一点都不难。这边我让每跑一次回圈,n就+1,然後用find函式更进一步地把刚刚筛选的范围缩小到a的href存到a变数中,这边把它print出来就可以看到刚刚下载用的网址了,再来我建立了images资料夹,并且将输入的关键字作为这资料夹的下一层资料夹,把这路径存到folder_path变数中,打算将下载的图片放到这里面。
再来就是变数命名的部分啦,要注意的一点是,在os中最好使用绝对路径,比较不会有错误的产生,所以我将刚刚的folder_path(路径)放进来,後面才接档案名称,用f字串的方式将刚刚的n放进来,後面再补副档名jpg,这样在每执行一次回圈(每抓一张图片),档案名称就会按照顺序从1往上变动,避免掉档案名称重复覆盖的问题。
然後再用请求的方式得到网址a的资料并存到r变数中,再用os的makedirs函式创建刚刚的路径资料夹。
有资料夹,有路径,有资料,再来就是下载存档了,这边程序码很短,只需要三行或两行:
with open(img_name, 'wb') as f:
f.write(r.content)
print('Dowlaad:' + img_name + ' ......')
利用open函式创建刚刚定义的档案名称,用wb模式写入(w=write,b=bytes,为写及二进制模式)
用content方式将刚刚抓到的东西全部写到创建的档案中,最後一行只是告诉我们进度而已,应该满好理解的。
这边说一下下载图片的原理,其实那个网址就是一个存放在网路世界的资料,不知道各位有没有用文字编辑器看过图片档案,应该会长这样:

这种档案就是一个一个位元组起来的,通常一般人是无法阅读的。为甚麽要讲这个呢,我们可以单纯以一般常试想,如果这堆乱码可以组合成一张图片,那我只要取得这些资料就好了啊,爬虫就是拿来达成这样的功能。
上面的f.write(r.content)其实就如同刚刚讲的,将网路上的这个档案中的,像是上面这些构成图片的资料,拷贝下来存到你开的档案中。所以就某些层面来说,它可以说是下载图片也不是下载图片。这再次说明了电脑中的所有一切,都是一段一段的文字而已,并且这些文字也只是从0跟1转换过来的而已。
再来就给各位看一下成果图吧:
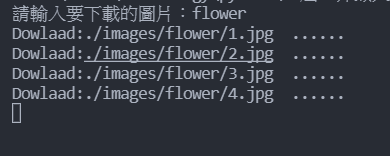
这样就能方便下载图片,再也不用手动按了,是不是很方便呢!
完整程序码:
from bs4 import BeautifulSoup
import requests
import os
input_image = input("请输入要下载的图片:")
response = requests.get(f"https://unsplash.com/s/photos/{input_image}")
soup = BeautifulSoup(response.text, "html.parser")
data = soup.find_all('div', {'class', "_2vsJm"})
n = 0
for datal in data:
n = n+1
a = (datal.find('a')['href'])
folder_path = f'./images/{input_image}/'
img_name = folder_path +f"{n}.jpg"
r = requests.get(a)
os.makedirs(folder_path, exist_ok=True)
with open(img_name, 'wb') as f:
f.write(r.content)
print('Dowlaad:' + img_name + ' ......')
明天会稍微提及一下动态爬虫,来讲解如何使用webdriver。
[Python 爬虫这样学,一定是大拇指拉!] DAY25 - 实战演练:关於多执行绪
多执行绪 介绍什麽是多执行绪(multithreading)前,先来简单讲一下什麽是执行绪。 在作业...
[笔记]vue-cli i18n 多语系应用练习
参考文章: https://medium.com/easons-murmuring/%E5%9C%A...
Day-13 Pytorch Tensors
程序语言会有一些常见的资料组单位,例如 python 会有 list,C、C++ 有 array ...
[ Day 19 ] - 箭头函式
这边先简单介绍前面有用到的函式陈述式和函式表达式 函式陈述式:特性是放在宣告的 function 前...
【Day7】情蒐阶段的小工具 ─ 扫描篇(一)
哈罗~ 今天要来跟大家介绍扫描的小工具 在介绍工具前,我们先来review一下TCP Flags。 ...