standardize VS normalize
当我们想要把资料丢进model前,常常会需要把资料标准化,尤其是针对跟距离有关的模型(像是knn, svm等),标准化大概分为standardize和normalize两种:
standardize:资料点减去平均数在除以标准差,当你觉得资料符合高斯分配时才选择
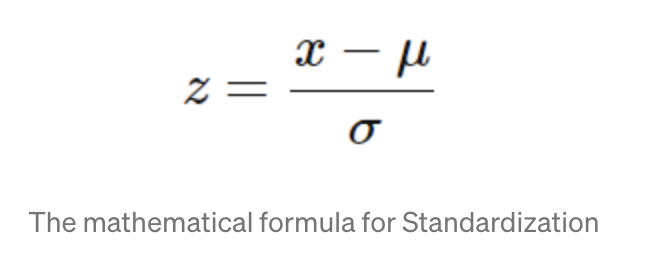
normalize:把资料范围变为[0,1]间,大部分的标准化都会选择这个方法
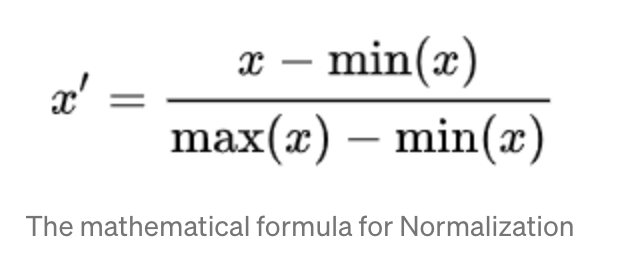
这边有一个非常重要的观念想要强调,就是在标准化之前必须要把资料先分割好,也就是对training和testing set分别标准化,不然会有data leakage的问题,data leakage是指训练模型的过程中用到了training set以外的资讯,如果在未分割前就把所有资料标准化,那数值就会隐含着所有资料的分布,进而影响模型。
[reference]
https://towardsdatascience.com/normalization-vs-standardization-cb8fe15082eb
>>: Day 17: 人工智慧在音乐领域的应用 (AI作曲-基因演算法一)
Day 19:「通通拿去做鸡精啦!」- Vue SFC
嗨大家~ 昨天有没有试着用 Creator 建立专案呢! 没有的话现在赶快去复习哦, 因为我们今天...
如何透过SEO搜寻优化布局全球市场
在辅导客户中多数都是外销公司的辅导顾问案件,尤於外销市场不同於内销市场在操作 业务开发 的确有难度。...
Day 10 「如入鲍鱼之肆」从测试闻出 code smell:万恶之源 ---「重复」
Day 10 「如入鲍鱼之肆」从测试闻出 code smell:万恶之源 ---「重复」 好好写测试...
Day9 Goroutine
并发 vs并行 并发运算就是多线程运算,且并发(concurrency)并非并行(Paralleli...
[2020铁人赛] Day29 - 切换身分Impersonation
通常系统中如果要区分windows权限只要在IIS内设定好即可,但有时候可能为了控管windows帐...