爬虫怎麽爬 从零开始的爬虫自学 DAY18 python网路爬虫开爬-1网页抓取
前言
各位早安,书接上回我们已经搞定接下来会用到的套件的安装了,套件是很强大的工具可以帮助我们简化很多复杂程序码,接下来今天我们要开始期待已久的开爬时间
但是在这之前 要麻烦你先做一件事
删除之前的练习档 string.py
为甚麽呢 这要从小弟我开心的测试爬虫程序开始讲起
有一天在运行我自己的 test.py 测试档的时候不断出现这个结果
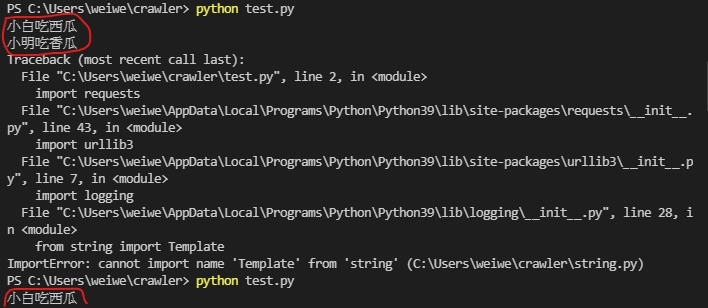
我就觉得奇怪怎麽会这样 还跑出小明跟小白 这超眼熟的阿
後来想起来这是之前练习档案的内容
阿奇怪怎麽我执行的是 test.py 报错就算了反而跑出别的档案的内容呢
後来经过我反覆确认及思考 突然想通了 原来是我取的名字太烂干扰到系统抓资料了阿
难怪会跑出 string.py 的内容
所以麻烦大家为了不要遇到问题
先找到它
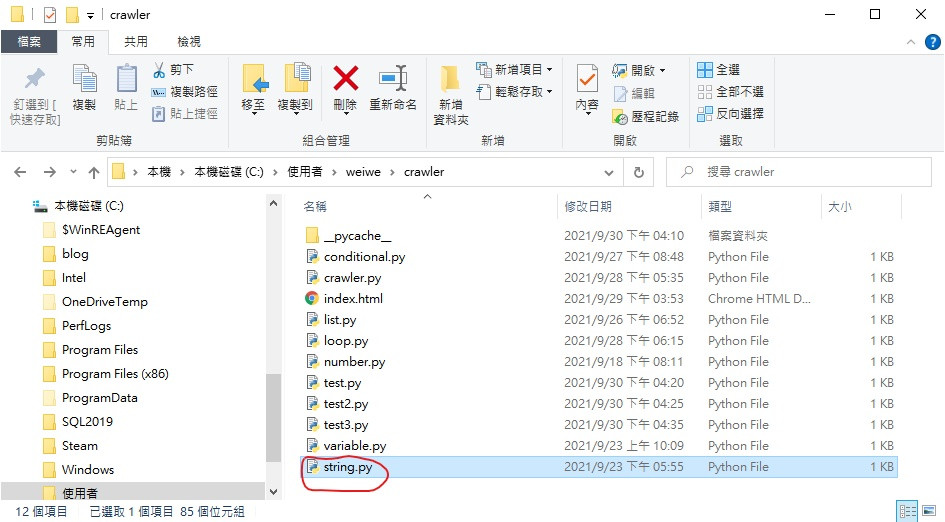
然後果断按下删除键吧
开爬-网页抓取
首先第一步就是打开我们好久没用到的 crawler.py 档案编辑器
那在我们开爬之前我们要先知道我们想要抓取那些资讯
所以今天假设我是一个想了解股票资讯的年轻人
想要抓取PPT股票版的内容了解最近的事
所以首先找到目标网页 url (网址)
复制下来
接着先 import 要用的套件功能 requests bs4
接着建个变数放 url
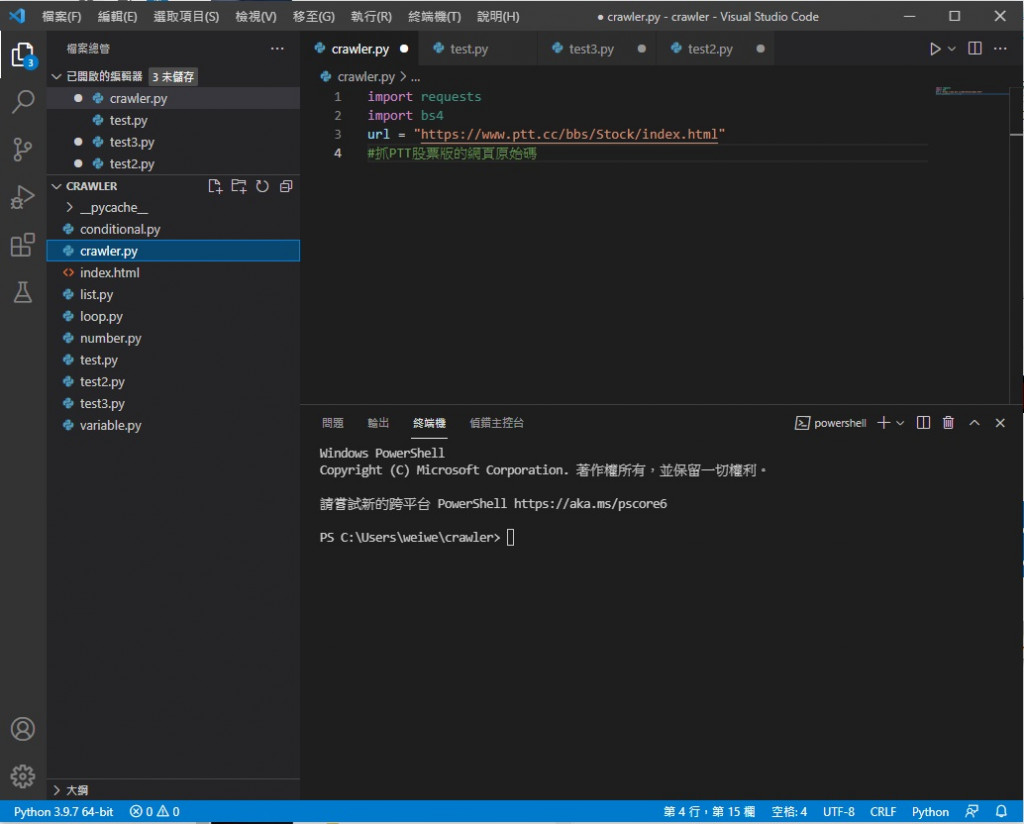
这里补充一下在 python3 中 # (井字号) 後面的内容叫做注解 是不会被程序执行到的
接着我们要用 requests 内的方法把网页内资料 GET 下来
再把它印出来看看
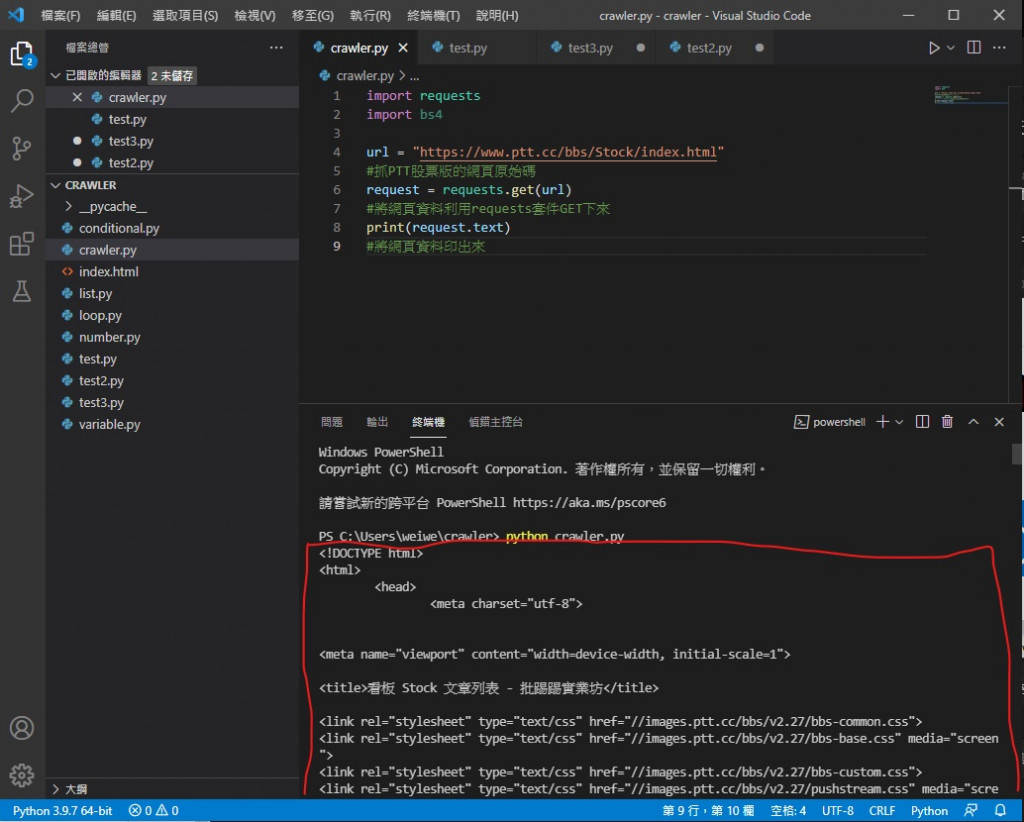
print(request.text) 意思是把 request 内的东西以文本形式印出
红色框住的地方开始就是抓到的网页内容 是 html 格式的网页原始码
我先提醒一下 这里抓到的内容都是网页实时更新的内容 你们跟我不一样很正常
我们到目标网页上看看原始码
先对网页点右键 再点检视网页原始码
就会看到这样的视窗 这就是刚刚网页的 html 原始码

跟刚刚我们爬虫抓到的一样
今天的程序码
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index.html"
#抓PTT股票版的网页原始码
request = requests.get(url)
#将网页资料利用requests套件GET下来
print(request.text)
#将网页资料印出来
今天我们知道怎麽抓到资料
明天要来讲解析这些资料的方法 还有怎麽抓取特定资料
早安闲聊区
你知道吗?
就连声控关灯也算是人工智慧喔
每日二选一
你觉得人工智慧发展下去会跟电影里一样毁灭人类吗
效率在哪里?别再开会开到死
在一开始整理观察到常见的痛点们,你看到的是想解决的地方,也可以换个角度去思考,其实你想要保持是你的信...
Day 26: Server我也不要了,Mock Ktor 环境
Keyword: Ktor MockEngine, Unit Test 直到27日,完成KMM的测试...
Day 25. Hashicorp Vault: Diagnose Vault server
Hashicorp Vault: Diagnose Vault server 这是Vault 1.8...
#11. Color theme switcher + Clock(原生JS版)
#11. 白天/夜间模式切换+时钟显示 这次作品的灵感是来自这个dribbble CodePen: ...
那些被忽略但很好用的 Web API / History
历史是现在与过去之间永无休止的对话。 我们都知道浏览器提供了上一页、下一页,甚至可以让你回到前两页...