Day 18 - [语料库模型] 06-程序码: TF、IDF、TF-IDF
今天和明天的主题会以讲解程序码为主,其中 TF-IDF 演算法主要来自莫烦 Pythton。
莫烦 Python 原版程序码: https://github.com/MorvanZhou/NLP-Tutorials
我修改过的版本: https://gitlab.com/graduate_lab415/nlp/-/blob/master/main.py
不确定我改了哪些东西(我也不记得了QQ),大部分应该只有加上印 log 的部分吧。
很重要,再提醒一次,中文要做 TF-IDF 要先经过断词,作法请参考前天的文章。 今天的 code 建议大家可以搭配 debug 模式使用,一行一行执行可以更清楚运作的步骤唷。
预处理
- 读档
- 断词
- 将词做成 set
v2i = {'word': index} i2v = {index: 'word'}
计算 TF(Term Frequency)
代表一个词在一篇文章(一个句子)中出现的频率。
程序码
def get_tf(method="log"):
"""term frequency: how frequent a word appears in a doc"""
_tf = np.zeros((len(vocab), len(docs)), dtype=np.float64) # [n_vocab, n_doc]
for i, d in enumerate(docs_words):
counter = Counter(d)
for v in counter.keys():
_tf[v2i[v], i] = counter[v] / counter.most_common(1)[0][1]
weighted_tf = tf_methods.get(method, None)
if weighted_tf is None:
raise ValueError
return weighted_tf(_tf)
步骤
-
先建一个2维矩阵
_tf = [词数, 句子数] -
依序填入

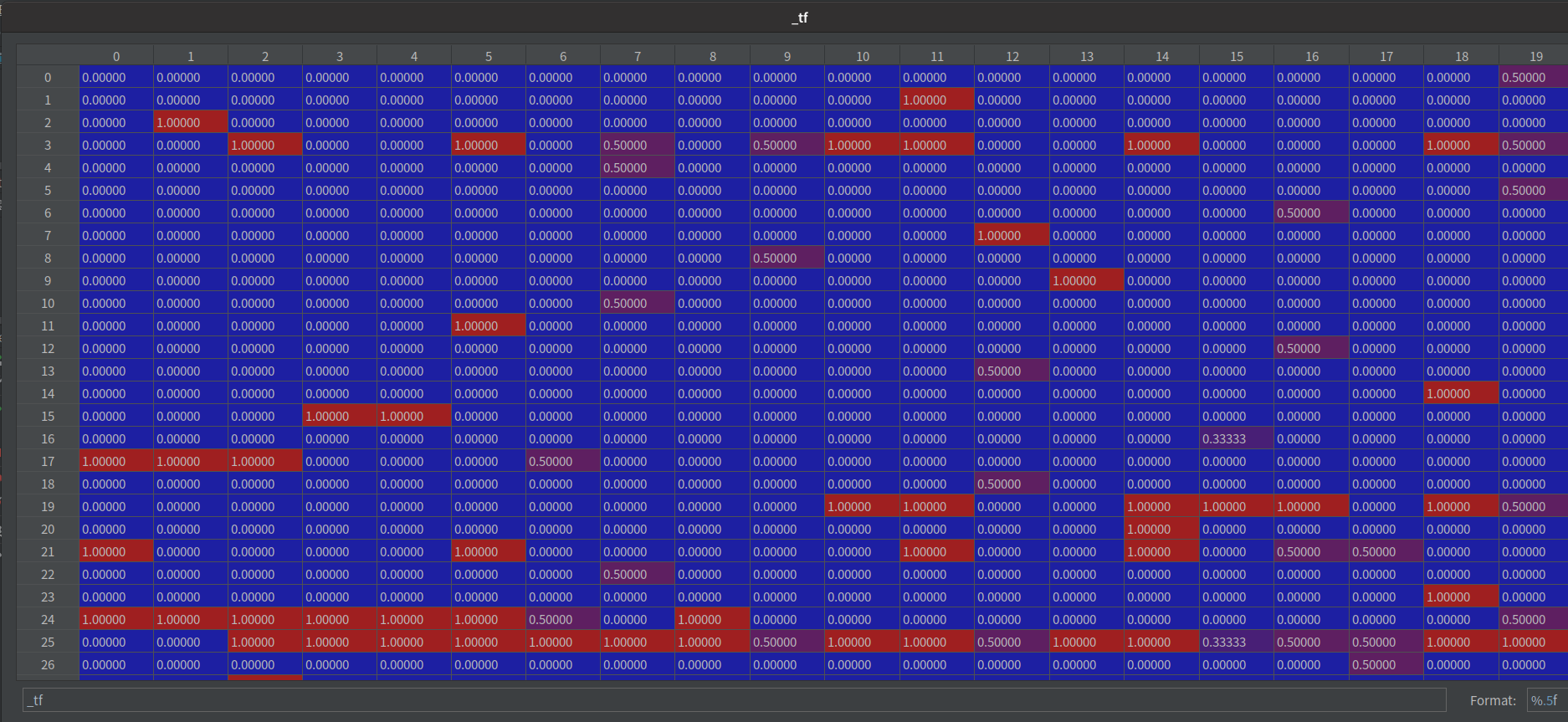
-
每个栏位都取自然对数
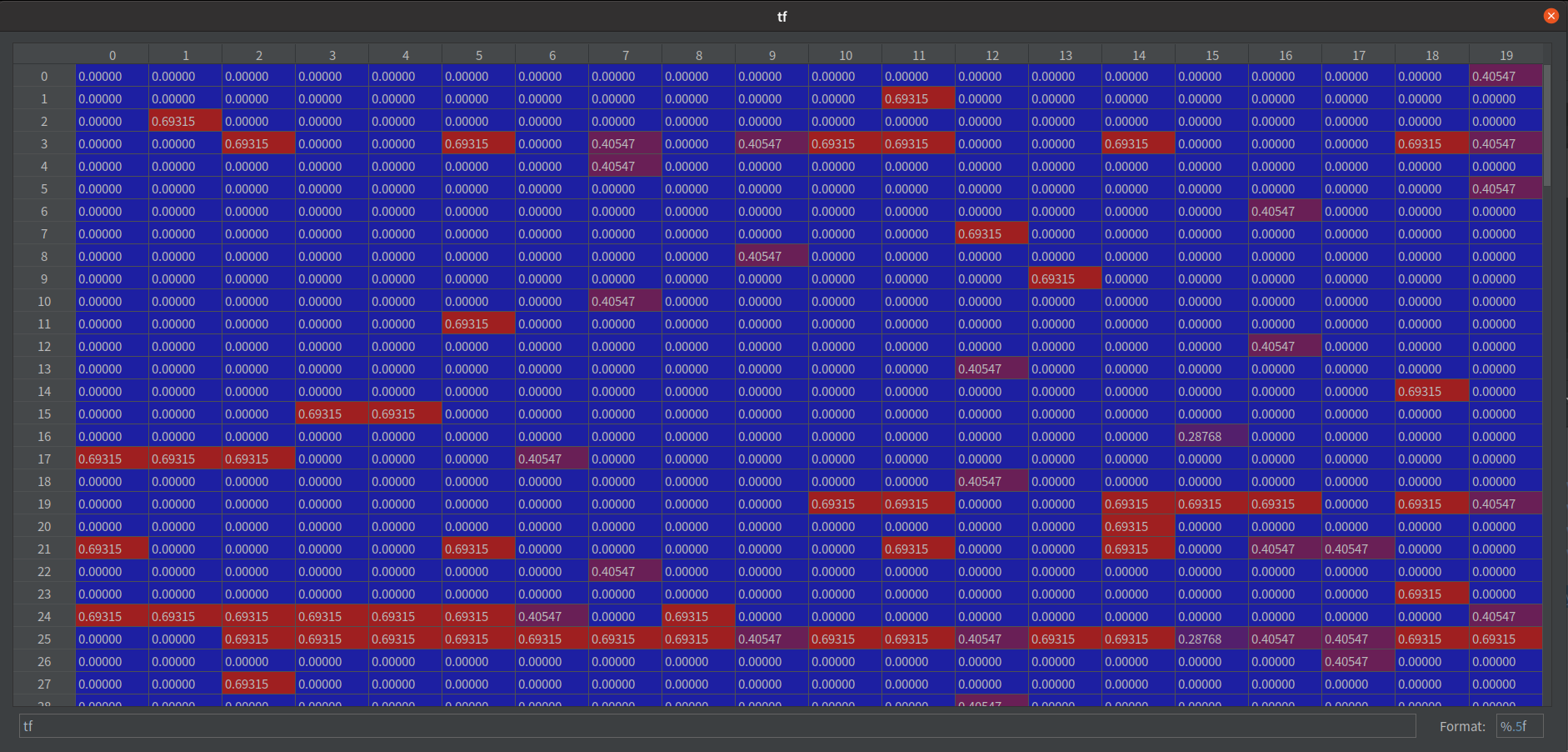
why 取对数?
处理资料时,对资料取对数的意义
log 以 e 为底的图
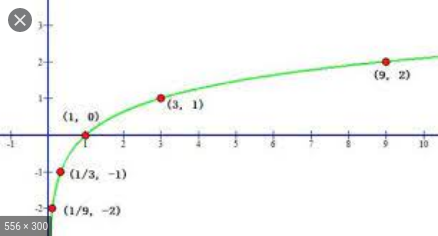
取log优点- 缩小资料的绝对数值,方便计算。
- 对数值小的部分差异的敏感程度比数值大的部分的差异敏感程度更高。
- 取对数之後不会改变资料的性质和相关关系,但压缩了变数的尺度,资料更加平稳
算 IDF
- DF(文件频率):是指一个词出现在几个句子中。
- IDF(逆向文件频率): IDF便是将DF经过转换,IDF 越低的表示这个词越不重要,反之亦然。
程序码
def get_idf(method="log"):
"""df: document frequency"""
"""inverse document frequency: low idf for a word appears in more docs, mean less important"""
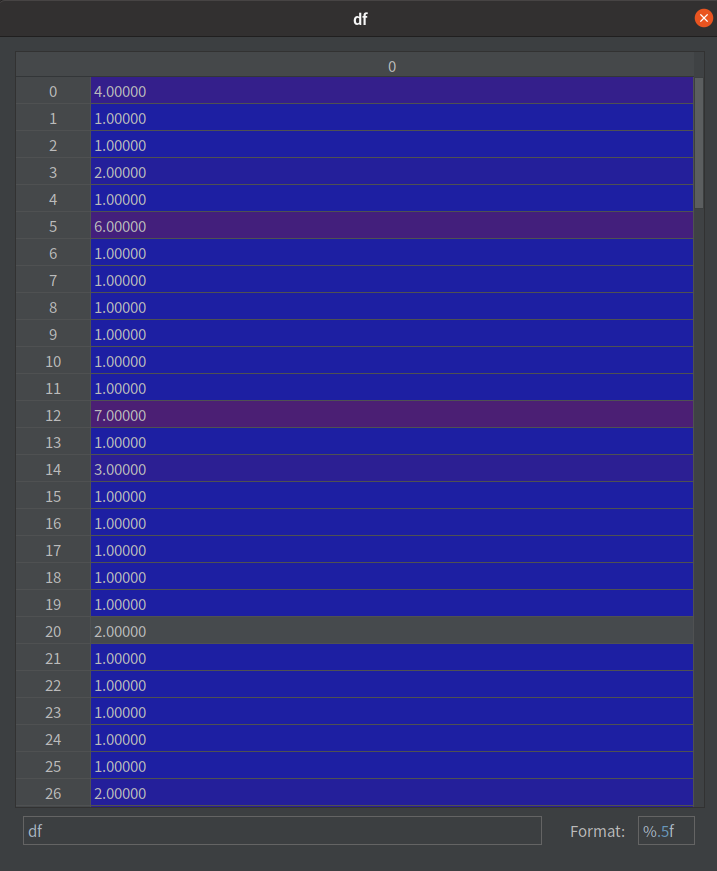
df = np.zeros((len(i2v), 1)) # [n_vocab, 1]
for i in range(len(i2v)):
d_count = 0
for d in docs_words:
d_count += 1 if i2v[i] in d else 0
df[i, 0] = d_count
if LOG:
print("\ndf samples:\n", df)
"""print df to a csv file"""
csv_writer = CsvWriter("df")
csv_writer.write_head(list(v2i))
csv_writer.write_row(df)
idf_fn = idf_methods.get(method, None)
if idf_fn is None:
raise ValueError
return idf_fn(df)
步骤
- 先算 df
- 建一个2维矩阵
df = [n_vocab, 1] - 依序填入

- 建一个2维矩阵
- 转成 idf
- 逐一带入公式

如果词语不在资料中,就导致分母为零,因此分母通常会加一
— from wiki https://zh.wikipedia.org/wiki/Tf-idf - 逐一带入公式
注意观察两张图,在 df 的数字越大,在 idf
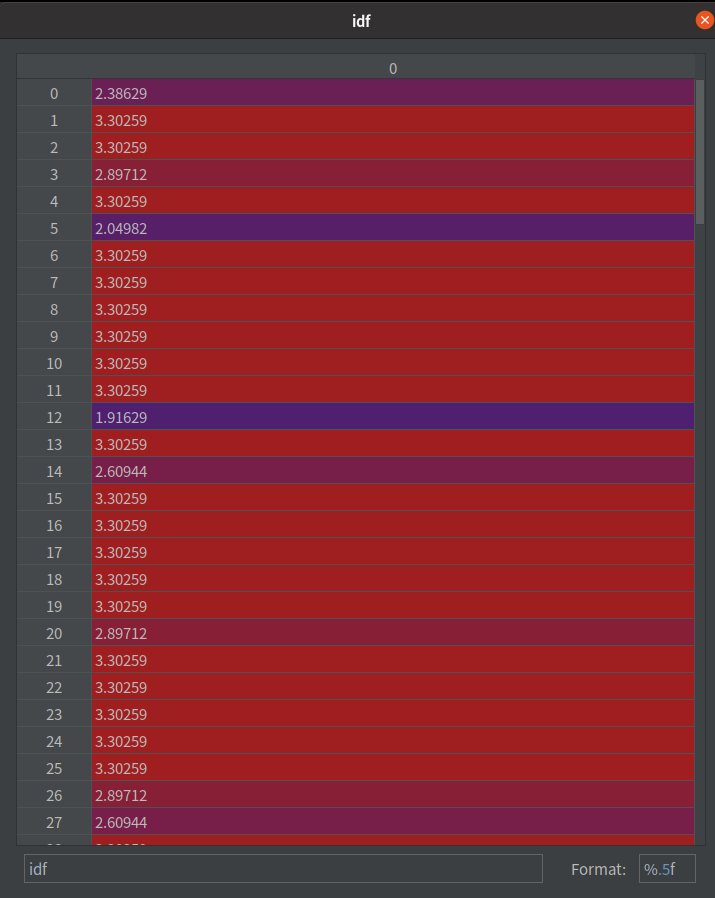
算 TF-IDF
TF-IDF 其实就是将 TF 加权 IDF 後的结果。
公式: tf_idf = tf * idf
注意这边是「乘」,不是矩阵乘法的那个 dot 哦。两者在 Python 里的写法不一样。
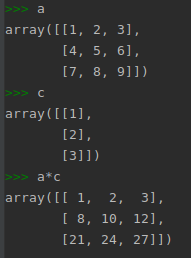
看个示意图:
a 的第一列都乘以 c 的第一列
a 的第二列都乘以 c 的第二列
...
对应到程序码里的几个阵列,他们的 size 分别是这样的:
tf [n_vocab, n_doc]
df [n_vocab, 1]
tf-idf [n_vocab, n_doc]
将 tf * idf 就会等於 tf_idf 罗!
结语
到这边,语料库模型(tf_idf)就建完了。明天会介绍,当我们接收到一个新句子,要如何比较它和其他句子的相似性。
好了,明天见!
<<: 【在 iOS 开发路上的大小事-Day20】透过 Firebase 来管理使用者 (Sign in with Facebook 篇) Part2
>>: DAY 20 『 连接 API 实作 - 天气 APP 』Part2
Day 12 | Dart 中的 Sound null safety
为什麽我们需要 null safety? 回答这个问题前应该要先了解为什麽会有 null ,如果写过...
如何设计自己的 RxJS Operators
今天我们来聊点轻松(?)的主题 - 「如何设计出自己的 RxJS Operators」吧! 为何要自...
DAY 7 『 TableView 』Part2
TableView:Storyboard + Table View + Table View Cel...
Azure DNS 手把手基础教学
葛瑞部落格欢迎光顾 目的应用 Azure DNS 顾名思义就是做为名称解析的托管服务,主要用途如下:...
【第十七天 - 文件读取漏洞】
Q1. 什麽是文件读取漏洞? 骇客可以透过一些手段读取无授权的档案,时常作为资讯收集的一种手段,例如...