DAY 19 Big Data 5Vs – Variety(速度) EMR (2)
接续介绍昨天建立的EMR丛集:
建立的丛集可以在左方工具栏的丛集分页找到
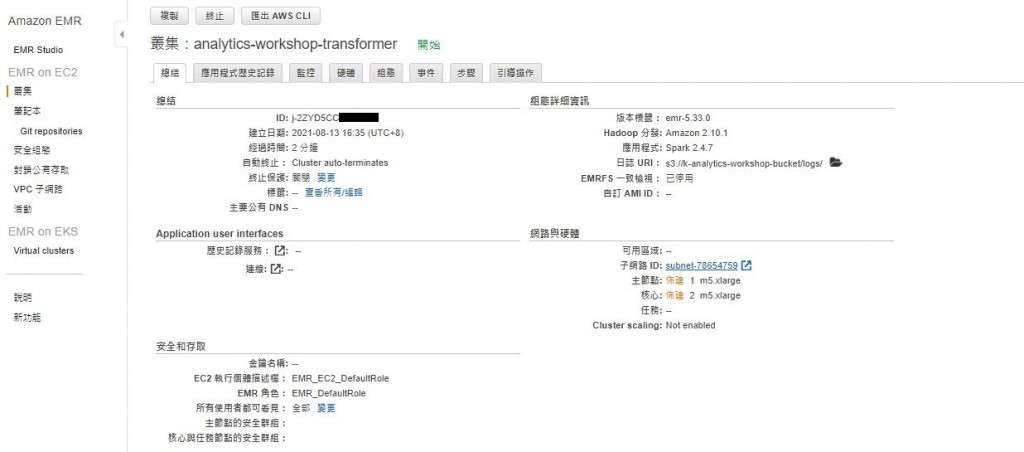
步骤的状态可以到「步骤」分页查看,可以看到丛集会分两步骤:
先建立好Hadoop後再安装Spark程序後执行分析任务
Hadoop设定大约需要6-8分钟
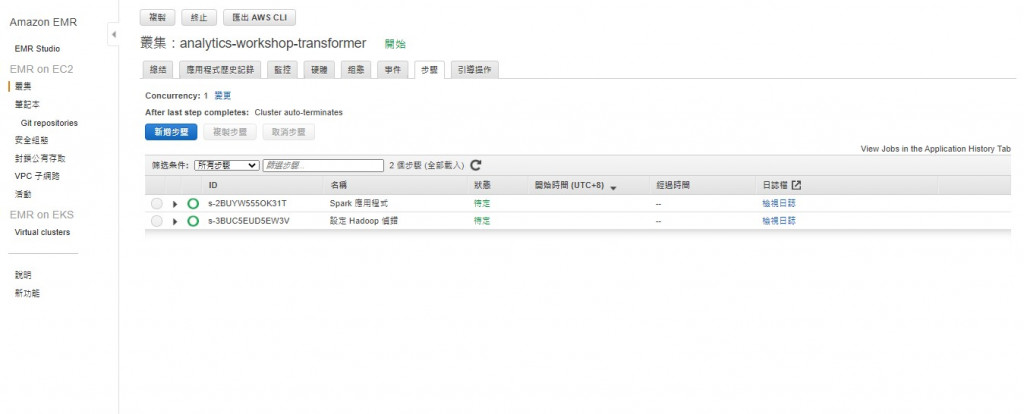
因为建立时选用的是步骤执行,可以看到状态还是「待定」
然後会看到执行步骤会由下而上依序转换成「已完成」,然後就会丛集就会终止
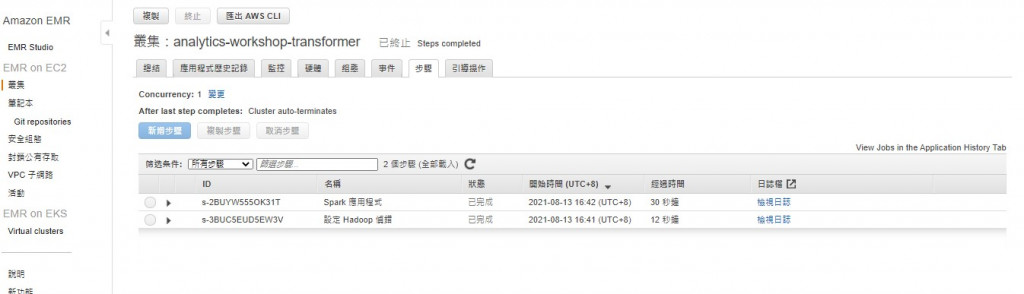
Log记录会存到建立丛集时指定的S3 bucket中,点选後会转跳到对应页面
如果执行失败了也可以到log记录去看
EMR的服务页面可以当作Hadoop3的 9870 port来用,相当方便,
而分析处理完的结果也是到S3 对应的bucket中查询
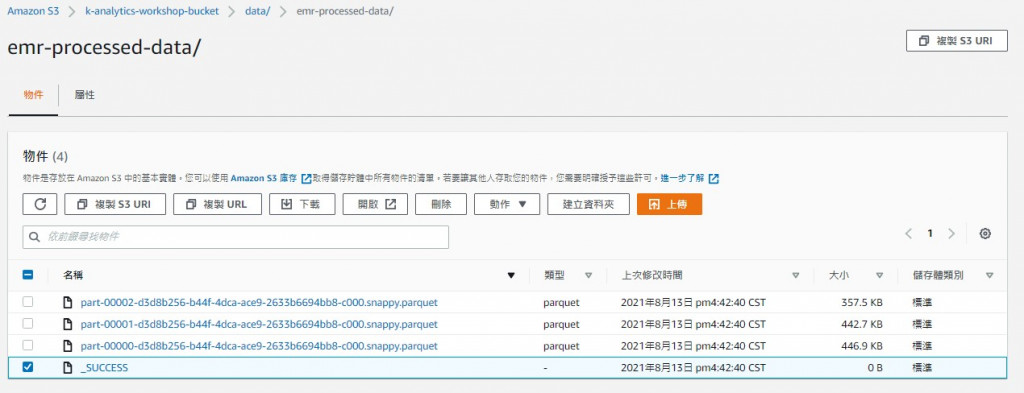
当然因为批次执行大量档案的分析,档案是以压缩档储存(这里是parquet档),
所以比起直接到S3察看EMR的ETL结果,更常见的架构是在EMR後串接像是Hive或Athena等查询工具来进一步分析资料
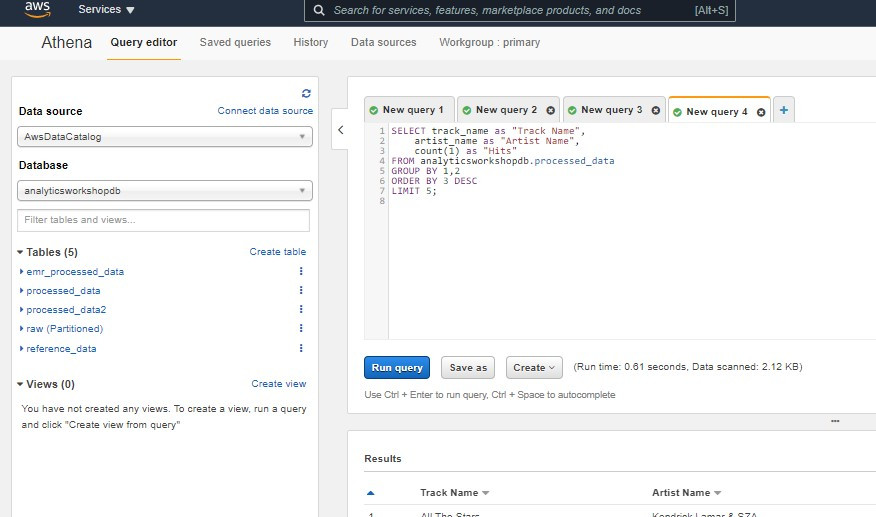
AWS上方便的查询工具就是Athena(後续会介绍),
进入到Athena服务页面可以在左方选定资料源後在右方编辑器下SQL查询语句
*Hadoop( https://zh.wikipedia.org/wiki/Apache_Hadoop )
[Day2] 电脑视觉下的人脸
万般皆是脸 注:在接下来的内容里,我会着重在"图片"下的人脸辨识 (包含摄影机...
Day11_HTML语法8
标示超连结 < a>元素是用来标示超连结,常使用的属性为< href> &l...
Day 18 - WooCommerce 测试环境建立 (下)
昨天我们安装完 WooCommerce 和修改 wp-config.php 关於 debug 的设定...
[NestJS 带你飞!] DAY04 - Controller (下)
主体资料 (Body) 在传输资料时经常会使用到主体资料,比如说:POST、PUT、PATCH等操作...
不同API层级的专案
手边有老机器的智慧型手机使用者应该不在少数,如果从早期HTC风光年代开始就换用智慧型手机的话,我想,...