[Day 15] 卷积类明星模型大乱斗
前言
前几天我介绍许多经典卷积神经网路架构,
也顺便等我的模型们都训练完成。
我总共训练了9种模型,
分别是VGG16, ResNet, ResNetv2, DenseNet121, DenseNet201,
MobileNet, MobileNetV2, EfficientNetB0, EfficientNetB7.
注意!我们只是要挑一个适合FER2013的演算法出来,
这边的模型只是雏形。
参数设定
下图可以看出我们在同样的条件下做实验,
像是...
batch size: 32
epochs: 30
optimizer: Adam
(如果有不一样的话,MLFlow会标记黄底)
模型比较
1. 训练时长
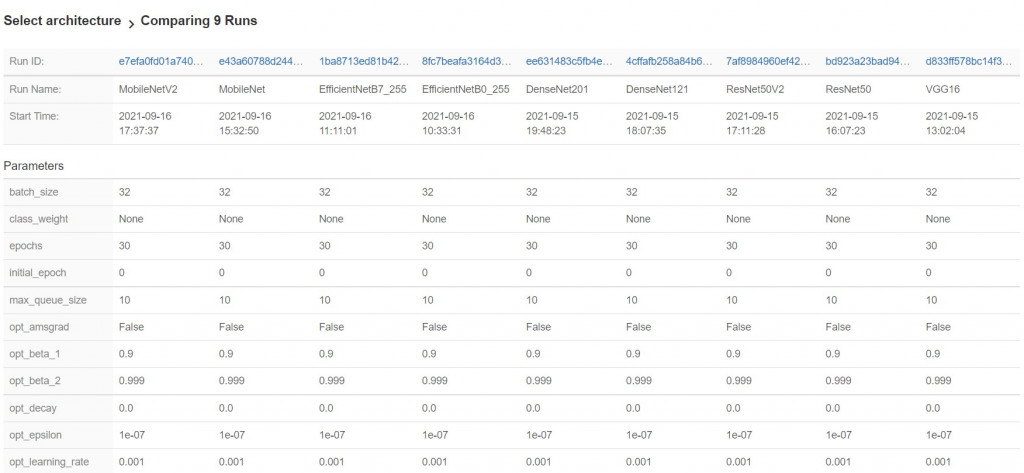
下图X轴是时间(单位:秒),Y轴是准确率。
可以看出EfficientNetB7一枝独秀,花费了超越12k秒,也就是3.3小时以上。
第二、三名是DenseNet201和VGG16,也花费了4k秒去训练模型,也就是1.1小时以上。
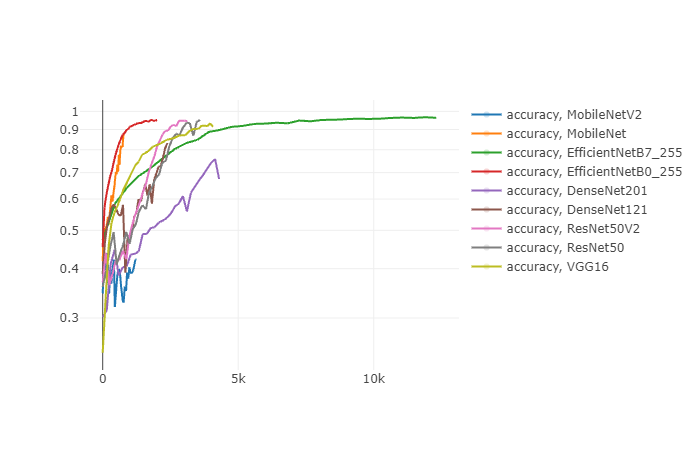
2. 比较准确率和损失函数值
| Metrics | MobileNetV2 | MobileNet | EfficientNetB7 | EfficientNetB0 | DenseNet201 | DenseNet121 | ResNet50V2 | ResNet50 | VGG16 |
|---|---|---|---|---|---|---|---|---|---|
| accuracy | 0.422 | 0.881 | 0.964 | 0.952 | 0.674 | 0.832 | 0.945 | 0.951 | 0.914 |
| loss | 1.547 | 0.348 | 0.108 | 0.139 | 0.892 | 0.474 | 0.162 | 0.147 | 0.259 |
| val_accuracy | 0.385 | 0.584 | 0.633 | 0.617 | 0.588 | 0.592 | 0.55 | 0.561 | 0.583 |
| val_loss | 1.663 | 1.472 | 1.756 | 1.905 | 1.21 | 1.566 | 2.431 | 2.312 | 1.986 |
对训练集准确率来说: EfficientNetB7 > EfficientNetB0 > ResNet50 > 其他
对训练集损失值来说: EfficientNetB7 < EfficientNetB0 < ResNet50 < 其他
对验证集准确率来说: EfficientNetB7 > EfficientNetB0>DenseNet121 > 其他
对验证集损失值来说: DenseNet201 < MobileNet < DenseNet121 < 其他
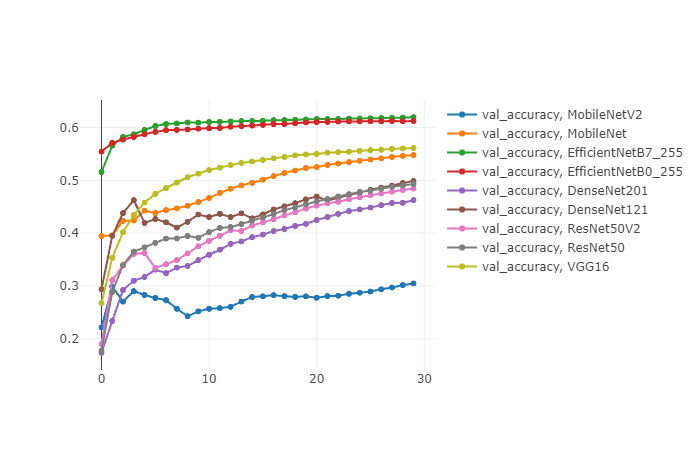
用MLFlow对val_accuracy做图:
X轴为epoch;Y轴为准确率。
3. 最终选择
OK,用这四个指标看起来不那麽一致,
那我只好用多数决来决定。
假设4个指标都有三票可以选,
所以EfficientNetB7和EfficientNetB0皆获得最高票(3票),
ResNet50和DenseNet121皆获得2票。
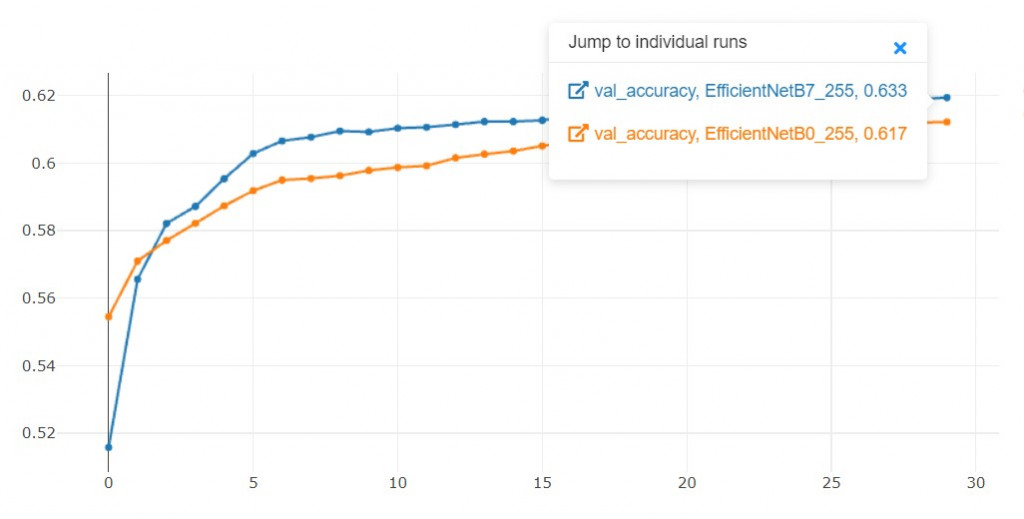
那EfficientNetB7和EfficientNetB0要选哪一个呢?
3.1 训练花费的时间:
由於EfficientNetB0的训练时间仅需37.1分钟,
而EfficientNetB7需要222分钟,是B0的6倍之多。
3.2 储存花费的空间:
EfficientNetB0仅有4M参数,而EfficientNetB7有64M参数,
B7是B0的16倍之多。
如果我选了B7,我浪费了这麽多空间和时间,只换来val_acc上升0.016。
那将是完全不划算的事情!
所以我决定选用EfficientNetB0当作我的初始演算法!
结语
记住,现在我们对验证集的准确率是61.7%。
这是我们的Baseline,
接下来几天,我将用各种方法,加强我们的模型!
ps:距离当年的冠军(69.8%)还落後 8.1%。
ps:其实EFN_B7已经打进八强了 :D
>>: [Day 15] 在Arduino IDE中用Arm CMSIS 牛刀小试一下
Springboot AJAX
Springboot AJAX ...
常见的BIA术语(Common BIA Terminologies)
NIST SP 800-34的第一个版本使用术语最大允许中断(Maximum Allowable ...
恐怖的全端工程师
这个标题有点重复,因为说白了「全端」工程师就是「懂很多」的工程师。 这类工程师受到市场青睐,说白了就...
【Day 29】支援向量机(Support Vector Machine, SVM)(下)
昨天讲完Hinge Loss,今天要继续介绍SVM的第二个特色:Kernel Method。 Dua...
【Day24】派一个Spy到网页中窃听—事件监听
先来说说什麽是「事件」呢? 举个例子:看到红灯,就踩刹车! 「看到红灯」就是事件;「踩刹车」就是事...