DAY16: 实作浏览器采取想访问的HTML
今天会结合上一篇的DAY15:HTTP GET请求的观念,并且加入一些不一样的东西,除了Nodejs要知道我拜访的GET请求,而需要浏览器会依照想访问的页面采取相对应的HTML文件。
但是这只是示范,所以今天只会建立四个不同的HTML文件,当作主页和即将拜访的页面,其中有一个是当要拜访的页面不在这几个档案时,要显示页面并不存在。
首先,建立一个资料夹,命名为HTML ,并建立四个不同内容的HTML,分别为start.html当作一开始的主页面、NicoleWorld.html为次要页面、Pocky.html为第三次拜访页面、最後是Notfound.html用来显示页面不存在。
接着程序码的部分先创建一个HTTP,(可以参考Day13:HTTP服务器),并用if else-if的形式来判别要读取的HTML档案,
若是Get请求,就做以下的判断,先是url===”/”,也就是代表主页(一开始会进入的页面),
接着当要拜访的页面是相对应的HTML档案时,根据url的位置,sendResponse()将会读取对应的HTML源代码。
//判别对应的HTML
var http=require("http");
var server=http.createServer((req,res)=>
{
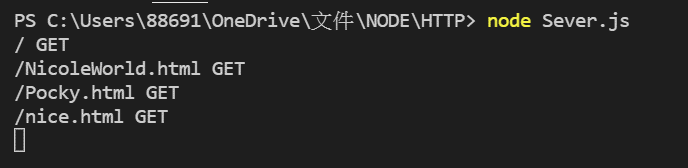
console.log(req.url,req.method)
if(req.method==="GET")
{
if(req.url==='/')
{
sendResponse("start.html",200,res);
}
else if(req.url==='/NicoleWorld.html')
{
sendResponse("NicoleWorld.html",200,res);
}
else if(req.url==='/Pocky.html')
{
sendResponse("Pocky.html",200,res);
}
else
{
sendResponse("Notfound.html",404,res);
}
}
else{}
});
server.listen(3000);
而要先建立一个sendResponse()用来读取和发送的HTML源代码,
参数为filename为档案名称、statusCode为状态码、res就是ressponse。
导入fs模块後就可以读取文件,而当读取错误时,状态码为500,并且告知读取错误;
当读取成功时,data参数会得到档案内容!
//读取对应的HTML
var fs=require("fs");
var sendResponse=(filename,statusCode,res)=>
{
fs.readFile(`./html/${filename}`,(err,data)=>
{
if(err)
{
res.statusCode=500;//服务器内部错误
res.setHeader("Content-Type", "text/plain");
res.end("ERROR");
}
else
{
res.statusCode = statusCode;
res.setHeader("Content-Type", "text/html");
res.end(data);
}
});
};
执行结果:
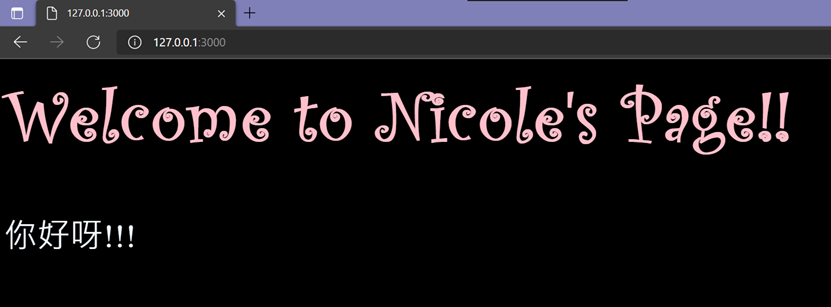
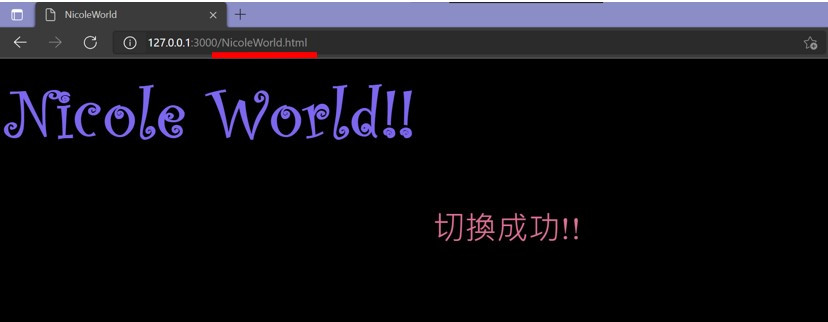
接下来拜访我想拜访NicoleWorld的页面(红色底线)
拜访Pocky.html的页面(红色底线)
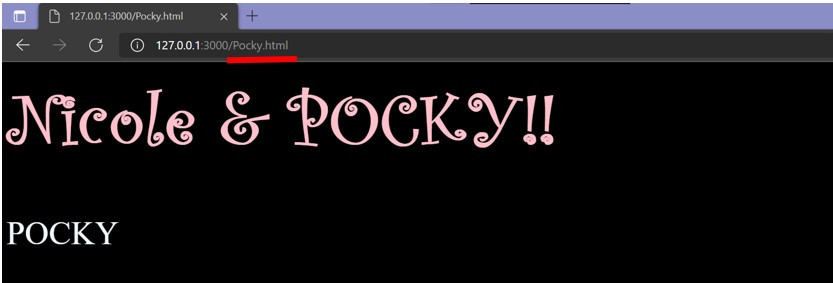
是的,都有被返回相对应的HTML。
接下来输入没有在设定的三个HTML以外的页面,输入url= "/nice.html"。
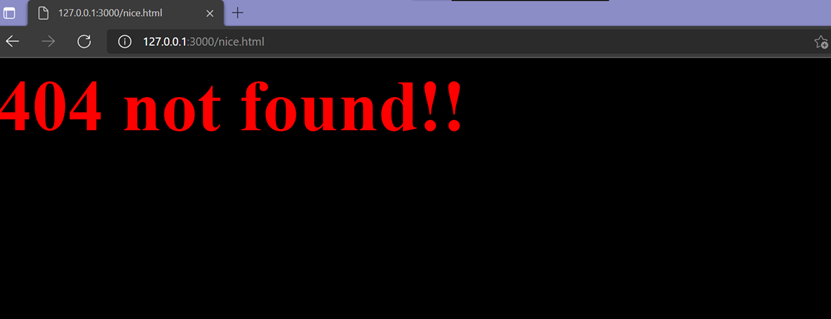
最後显示位找到该页面,也是因为此页面不在我们设定的范围中。
而当在我们拜访每一个页面时,NodeJS也知道我们拜访了哪个页面。
Day22-TypeScript(TS)的函式(Function) Part2
昨天讲的将函式(Function)加入型别相信大家都了解了, 今天就带大家来看看**完整函式型别(W...
Day 31:RecyclerView Loads More
本来先看了 paging 的相关资料,发现顺序有点不太对,应该先处理 RecyclerView 下滑...
[Day27] 基础的 Directive
在实际工作中,我们常常会需要某一块的网页内容重复出现,像是动态的抓资料然後塞到 table 的 ro...
Day6-我通知你的通知通知我!!!(无误!
标题那个还真的是没有写错~ 且听我细细道来~ ------------------------ 【一...
Day 28 让我胆战心惊的微服务 Vol.2
各位参赛选手~我是今天的主播 小笠宏树!各位准备好了!!!3 2 1 ~ 比赛开始! 今天来推脑洞神...