GPU程序设计(4) -- 记忆体管理
GPU记忆体类别
GPU记忆体类别有非常多种,各有所长,如果善用可进一步提升执行效能,参考下图:
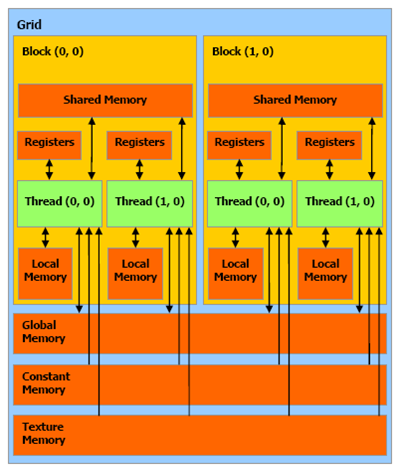
图一. GPU记忆体类别,图片来源:『CUDA Tutorial by Jonathan Hui』
比较说明如下表:
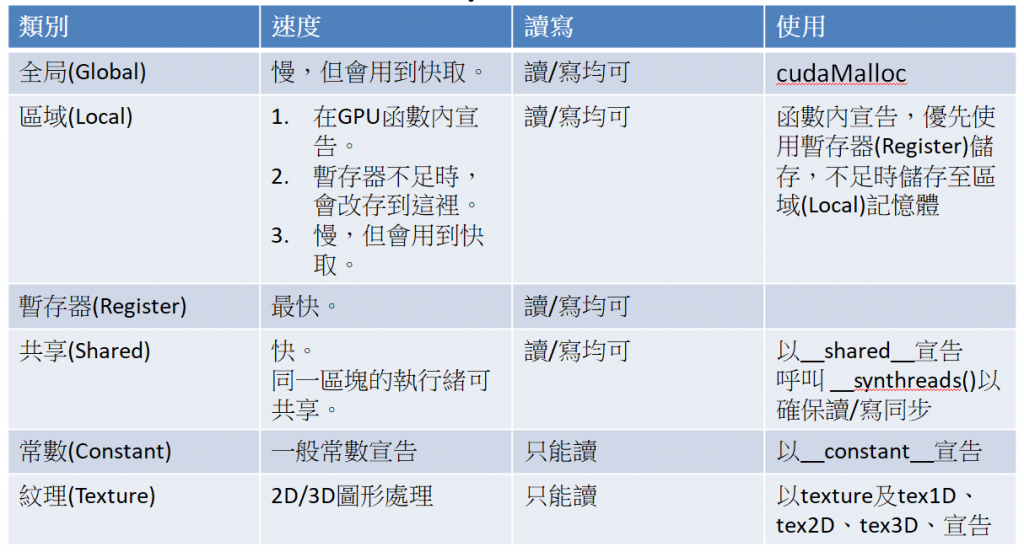
图二. GPU记忆体类别与比较
测试
- 区域(Local)变数:可能储存於暂存器(Register)或区域(Local)记忆体
__global__ void gpu_function(int* d_a, int* d_b, int* d_c) {
// 区域(Local)变数
int tid = threadIdx.x;
...
}
- 全局(Global)变数
int* d_a;
...
cudaMalloc((void**)&d_a, N * sizeof(int));
- 常数(Constant)
// 宣告常数
__constant__ int d_f;
__global__ void gpu_function(float *d_in, float *d_out) {
// 使用常数
d_out[tid] = d_f * d_in[tid];
}
int main(void) {
// 设定常数
int h_f = 2;
// 复制 h_f 至 d_f
cudaMemcpyToSymbol(d_f, &h_f, sizeof(int),0,cudaMemcpyHostToDevice);
gpu_function << <1, N >> >(d_in, d_out);
}
- 共享(Shared)记忆体较常用,下一段详细说明。
- 纹理(Texture)记忆体用於2D/3D图形处理,後续详加说明。
共享记忆体
当多执行绪运算时,会使用到同一个变数时,我们就可以利用共享记忆体,例如『上一篇』矩阵运算,由於全局(Global)记忆体较共享(Shared)记忆体存取较慢,故可将来源矩阵(a、b)复制到共享变数,再进行计算。
__global__ void gpu_inner_product_shared(float* d_a, float* d_b, float* d_c)
{
// 输出所在格子的座标
int row = threadIdx.x;
int col = threadIdx.y;
//Defining Shared Memory
__shared__ float shared_a[A_ROW_SIZE][A_COLUMN_SIZE];
__shared__ float shared_b[B_ROW_SIZE][B_COLUMN_SIZE];
for (int k = 0; k < A_COLUMN_SIZE; k++)
{
shared_a[row][k] = d_a[row * A_COLUMN_SIZE + k];
}
for (int k = 0; k < B_ROW_SIZE; k++)
{
shared_b[k][col] = d_b[k * B_COLUMN_SIZE + col];
//__syncthreads();
}
// // 点积
// printf("row=%d, col=%d\n", row, col);
for (int k = 0; k < A_COLUMN_SIZE; k++)
{
// 第一个输入矩阵的【列】与第二个输入矩阵的【行】相乘
d_c[row * B_COLUMN_SIZE + col] += shared_a[row][k] * shared_b[k][col];
//printf("result=%d, A=%d, B=%d\n", row * B_COLUMN_SIZE + col, row * A_COLUMN_SIZE + k, k * B_COLUMN_SIZE + col);
//__syncthreads();
}
}
宣告与复制动作都在多执行绪完成,不会有重复宣告的困扰,真是太神奇了。
结语
完整程序放在『GitHub』的InnerProduct目录。
<<: 风险处置(风险回应)[Risk Treatment (Risk Response)]
>>: 【前端效能优化】WebP - 较小容量的图片格式选择
【Day 27】差点被我遗忘的 x AWS RDS on Outpost x 云端资料库储存
tags: 铁人赛 AWS RDS Outposts database 前情提要 差点就跟蔡琴一样,...
用 Python 畅玩 Line bot - 13:MongoDB 操作
连接资料库与资料表 连接到对应的资料库与资料表: import pymongo myclient =...
IOS、Python自学心得30天 Day-23 Firebase衔接Python-1
前言: 之前提到 我一直在想办法让原本的训练模型 转成IOS可以用的模型 但找了许多方法後 还是没成...
Day 26 : 案例分享(7.5) 库存与制造 - 物料需求计划及MES制造执行系统 (客制内容)
案例说明及适用场景 提供二个实务运用的客制案例 物料需求计划-透过销售订单生成制造订单後,载入预计投...
[Android Studio] 汇入向量图档 .svg 时出现错误 <text> is not supported 的解决方式
今天因应工作上的需求 在专案中汇入 .svg 的向量图档 却出现了以下错误画面 这才发现原来这张 ....