Python爬虫,真的很简单
首先要先了解什麽是爬虫:
网路爬虫可理解成,可自动蒐集网页上资讯的程序。本篇会介绍静态与动态网页的爬虫作法,至於两场的使用场合,理论上来说动态的相对比较不会有问题
本篇爬虫皆使用python执行,所以执行前请先确认电脑有可执行python程序的环境,可参考以下连结
安装python请点我
静态网页爬虫
静态网页爬虫方法 (BeautifulSoup)
import psycopg2 # pip3 install psycopg2
import urllib.request # pip3 install requests
from bs4 import BeautifulSoup # pip3 install psycopg2
HOST = "localhost"
PORT = 5432
USER = "liyanxian"
PASSWD = ''
DATABASE = "postgres"
try:
conn = psycopg2.connect(host=HOST, port=PORT, user=USER,password=PASSWD,
database=DATABASE)
curr = conn.cursor()
print('开始连接资料库')
except:
print('资料库连接失败')
raise
url = "http://www.smeacommercialdistrict.tw/location/street"
# 发一个request去这串网址 并且拿回结果
response = urllib.request.urlopen(url)
data = response.read()
text = data.decode('utf-8-sig')
# 这边参数很多可以选择 不过基本上都在做同一件事情 (不过现在一般都推荐lxml 因为效能好)
soup = BeautifulSoup(text, "lxml") # parse (要先pip install lxml 不然会喷错)
html_div = soup.find('div',class_="col-12") #找到我们需要蒐集资料的外框 (find只会找第一个)
# 去外框里面找到每一个(find_all)城市名称
city_name = html_div.find_all(
'h3', attrs={'class': 'county_title'})
#去外框里面找到每一个(find_all)表格
table_content = html_div.find_all(
'table', attrs={'class': 'table table-striped table-bordered table-sm contactus_table'})
# range(len(xxx)) vs enumerate(xxx) 前者不可传val 後者可传
for index in range(len(city_name)):
# 找出表格里所有的tr (select跟find_all功能其实一样 只是语法不太一样)
table_tbody_tr = table_content[index].select(
'tbody > tr')
# 这边在做资料库的Insert
for index2, val2 in enumerate(table_tbody_tr):
curr.execute("""INSERT IGNORE INTO `bussinessdistrict`
(`id`, `city`, `businessname`,`regio`, `businessarea`)
VALUES (%s,%s,%s,%s,%s)""",
(table_tbody_tr[index2].contents[1].contents[0], city_name[index].contents[0], table_tbody_tr[index2].contents[3].contents[0], table_tbody_tr[index2].contents[5].contents[0], table_tbody_tr[index2].contents[7].contents[0]))
conn.commit() # 确认送出(必要)
curr.close()
conn.close()
动态网页爬虫
为何需要动态网页爬虫?
因为在呼叫动态网页时,无法取得该网页与呼叫後端的“资料”。此外,也有SPA网页只有读到空白html的可能性(例如:中油网站)
在动态爬虫我们需要chrome的driver来帮我们执行浏览器可至以下连结下载
https://chromedriver.chromium.org/downloads
认识xPath
xPath是一种用来寻找XML文件中某个节点(node)位置的查询语。
实作:以我司的登入系统(NIS)为例
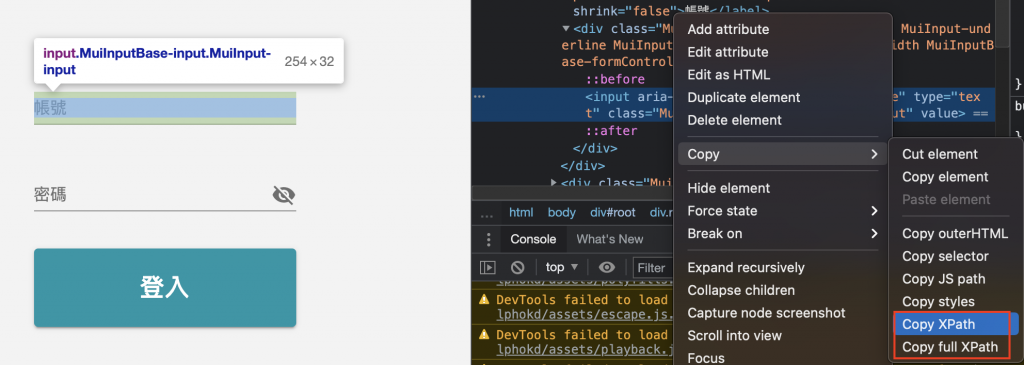
XPath vs. full XPath
"//*[@id="root"]/div[3]/div/form/div[2]/div/input" vs. "/html/body/div/div[3]/div/form/div[2]/div/input"
Step.1:抓取NIS的帐号输入方块xpath://*[@id="root"]/div[3]/div/form/div[2]/div/input
Step.2 定位帐号输入框
Step.3 传入字串
Step.4:抓取NIS的密码输入方块xpath
Step.5 定位密码框
Step.6 传入字串
Step.7:抓取NIS的登入方块xpath
Step.8 定位登入按钮
Step.9 点击登入按钮
输入完帐号密码後 就可以透过button点击登入按钮
因诸多考量,不公开底下python语言中的url及帐号密码
动态爬虫方法 (Selenium)
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 背景执行设定
driver = webdriver.Chrome(executable_path='./chromedriver' ) # chromedriver的路径(档名要记得确认)
# driver = webdriver.Chrome(executable_path='./chromedriver', chrome_options=options)
url = 'jubo_url' # 进入点的网址(换成你想登入的网址)
driver.get(url)
driver.implicitly_wait(10) # 如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间终止
# 请使用正确的xpath
account = driver.find_element_by_xpath('/html/body/div/div[3]/div/form/div[2]/div/input')
account.send_keys("xxxxxxxxxxxx") # 输入帐号
# 请使用正确的xpath
password = driver.find_element_by_xpath('/html/body/div/div[3]/div/form/div[3]/div/input')
password.send_keys("xxxxxxxxxxxx") #输入密码
button = driver.find_element_by_xpath('/html/body/div/div[3]/div/form/button')
button.click()
结语
爬虫看起来很万能可以长期抓取想要的资料,但面对常改版或出事的网页时,爬虫常会遇到程序"执行有误"的问题发生,虽可透过发讯息告知使用者,不过收到讯息後大概表示又要修改爬虫程序,实际上频繁的改动也是相当耗神。
>>: Efficient & Latest ECCouncil 312-49v10 Dumps "2021" | Real 312-49v10 Exam Questions & Answers
CMoney菁英软件工程师战斗营_Week 7
Hi again 本周大部分时间都是在准备游戏专题 在专题中也会需要上周所提及的图片切个制作动画 由...
【Day20】 WavenetGan, BidirectionalLSTMGAN, WaveGan 钢琴音乐生成
因为之後想花一点时间分享一下 Transformer 阅读跟实作的经验,所以这篇就没写 Trans...
第44天~
这个得上一篇:https://ithelp.ithome.com.tw/articles/10258...
【day12】连续上班日做便当
终於要回到正轨了 其实参加这个系列 主要是期许自己 在忙碌的工作之余 还可以每天现做便当 自从上个中...
CSS display:Grid
grid-template-areas 使用 grid-template-areas 定义每个区块,...